Шепоту посвящается.
Возможно читателю покажется интересным приложение в конце статьи :
Что такое нарастающие итоги ? И зачем они нужны ?
Три подхода или кто прав ?
1. Eugeneer предлагает следующий алгоритм решения задачи получения просроченных долгов контрагентов . Организовать цикл обхода выборки контрагентов ,в каждой итерации которого выполнять "мелкий" запрос к базе и с помощью кодинга получить необходимые данные отчета. Eugeneer имеет весомый аргумент - отчет //infostart.ru/public/60670/ ,практическое тестирование которого показало неплохие результаты при размере базы УТ - 13 Гб и количестве контрагентов - более 4 тыс.
2. Ish_2 в дискуссиях с Anig99 и Eugeneer настаивал на том , что лучший вариант с точки зрения быстродействия - это сделать один запрос к базе и за один проход выборки кодингом получить все необходимые для отчета данные . Ish_2 считает весомым аргументом собственные рассуждения и умозрительные построения.
3. Anig99 предлагает уместить алгоритм получения всех данных в один пакет запросов. Anig99 имеет весомый аргумент- отчет //infostart.ru/public/58966/ , который показал хорошее быстродействие при объеме базы 120(!) Гб
В настоящий момент , автор статьи считает , что прав в споре - Anig99. Опуская аргументацию почему Eugeneer и Ish_2 неправы (пожалуй , потянет на отдельную статью о вредности "семерочного" похода при работе с таблицами БД),скажу лишь , что выбранный Anig99 подход , не предполагающий кодинга вовсе - самый простой и технологичный , при котором мы "отвязываемся" от "слабости" клиента и передаем всю обработку данных на сервер баз данных. Итак, правильный подход к решению задачи выбран. Осталась мелочь - написать эффективный запрос , обеспечивающий наилучшее быстродействие. Мелочь эту мы и рассмотрим в статье.
Рассматриваемый ниже вариант построения текста пакета запросов для решения поставленной задачи представляется автору самым оптимальным для как небольших, так и очень больших объемов данных (свыше 120-150 ГБ). В демонстрационных целях , для объяснения сути подхода к решению задача несколько упрощена . Несколько упрощен , соответственно , и предлагаемый к рассмотрению текст пакета запросов . Теперь можно приступить к делу.
Постановка задачи.
Даны две таблицы:
Таблица «Долги»
|
Контрагент |
Долг |
ДатаОтсрочки |
|
Компания |
200 |
01.11.09 |
Таблица «Обороты»
|
Контрагент |
Период |
Рег-р |
Сумма |
|
Компания |
10.09.09 |
Накл. 1 |
40 |
|
Компания |
20.09.09 |
Накл. 2 |
60 |
|
Компания |
31.10.09 |
Накл. 3 |
80 |
|
Компания |
25.11.09 |
Накл. 4 |
100 |
Требуется получить таблицу «Просроченные долги»
|
Контрагент |
Период |
Рег-р |
Сумма |
Долг |
Просроченный долг |
|
Компания |
20.09.09 |
Накл. 2 |
60 |
20 |
20 |
|
Компания |
31.10.09 |
Накл. 3 |
80 |
80 |
80 |
|
Компания |
25.11.09 |
Накл. 4 |
100 |
100 |
0 |
В выходную таблицу вошли документы на общую сумму равную долгу контрагента (=200).
Алгоритм получения выходной таблицы сводится к нахождению в таблице «Обороты» строки с регистратором «Накл 2»,.
Действительно , сумма долга 200 будет складываться как
Строка «Накл 4» - 100
Строка «Накл 3» - 80
Строка «Накл 2» - 20 , где 20 – это часть значения «Суммы» текущей строки
таблицы «Обороты».
Итак , мы ищем строку в таблице «Обороты», которая является последней в последовательности строк таблицы «Обороты» , «набирающих» в обратном порядке следования строк необходимую сумму долга.
 Отступление для "семерочников".
Отступление для "семерочников".
Не спешите восклицать: " Делов -то ! Пройтись по таблице "Обороты" циклом, да и дело с концом !" Представьте себе , что во встроенном языке 1с нет оператора цикла . Возможно, тогда представленный алгоритм не покажется совсем уж нелепым.
Описание алгоритма решения .
I. Получим суммарные обороты с нарастающими итогами по месяцам из таблицы «Обороты». . Долг контрагента(=200) лежит в интервале 180-280, значит искомый период - сентябрь . Остаток долга для последующего поиска составит 200 – 180 = 20.
В вехней строке таблицы показаны нарастающие итоги оборотов.
| 0 | 100 | 180 280 |
|
Ноябрь |
Октябрь |
Сентябрь |
|
100 |
80 |
100 |
II. Получим последовательность документов с нарастающими итогами в сентябре. Остаток долга 20 лежит в интервале 0-60 , значит искомая строка таблицы «Обороты» найдена.
| 0 60 | 100 |
|
Накл. 1 от 20.09.09 |
Накл. 1 от 10.09.09 |
|
60 |
40 |
III. Скопируем все строки из таблицы «Обороты» с периодом большим или равным 20.09.09 в новую таблицу. Добавим новые колонки «Долг» и «Просроченный долг». Заполним добавленные колонки очевидным образом ,учитывая , что «Долг» для строки с «Накл. 2» составляет 20, и значение «Даты Отсрочки» - 01.11.09 .
|
Контрагент |
Период |
Рег-р |
Сумма |
Долг |
Просроченный долг |
|
Компания |
20.09.09 |
Накл. 2 |
60 |
20 |
20 |
|
Компания |
31.10.09 |
Накл. 3 |
80 |
80 |
80 |
|
Компания |
25.11.09 |
Накл. 4 |
100 |
100 |
0 |
Отступление для "семерочников".
Обратите внимание на то, что с точки зрения здравого ("семерочного") смысла мы сделали немыслимое : вместо очевидного перебора строк в таблице "Обороты" просуммировали по месяцам всю таблицу. Поехали в Москву через Владивосток ? - Смотри приложение в конце статьи.
В демонстрационном примере мы рассматривали лишь два вида интервала для поиска Месяц-документ. В реальных же задачах, когда очень большая таблица "Обороты" имеет строки с высокой плотностью по времени (розничные продажи по дисконтным картам , как у пользователя Anig99) количество видов интервалов для поиска должно быть увеличено, например Год - квартал - месяц - декада - день - документ.
Текст пакета запросов
Рассмотрим текст пакета запросов из отчета "ПросроченныйДолг", содержащегося в демонстрационной конфигурации "ПросроченныйДолг.dt". Таблицы "Долги"и "Обороты" реализованы как справочники . Сделано допущение, что поле "Период" в справочнике "Обороты" содержит только уникальные значения.
1. Найдем обороты по месяцам
ВЫБРАТЬ
Обороты.Контрагент,
НАЧАЛОПЕРИОДА(Обороты.Период, МЕСЯЦ) КАК НачПериода,
КОНЕЦПЕРИОДА(Обороты.Период, МЕСЯЦ) КАК КонПериода,
СУММА(Обороты.Сумма) КАК Сумма
ПОМЕСТИТЬ ОборотыПоМесяцам
ИЗ
Справочник.Обороты КАК Обороты
СГРУППИРОВАТЬ ПО
Обороты.Контрагент,
НАЧАЛОПЕРИОДА(Обороты.Период, МЕСЯЦ),
КОНЕЦПЕРИОДА(Обороты.Период, МЕСЯЦ)
;
Временная таблица "ОборотыПоМесяцам"
|
Контрагент |
НачПериода |
КонПериода |
Сумма |
|
Компания |
01.09.09 |
30.09.09 |
100 |
|
Компания |
01.10.09 |
31.10.09 |
80 |
|
Компания |
01.11.09 |
30.11.09 |
100 |
2. Получим нарастающие итоги для "ОборотыПоМесяцам".
ВЫБРАТЬ
ОборотыПоМесяцам.Контрагент,
ОборотыПоМесяцам.НачПериода,
ОборотыПоМесяцам.КонПериода,
ОборотыПоМесяцам.Сумма,
СУММА(ОборотыПоМесяцамКопия.Сумма) КАК СуммаПосле,
СУММА(ОборотыПоМесяцамКопия.Сумма) - ОборотыПоМесяцам.Сумма КАК СуммаДо
ПОМЕСТИТЬ ОборотыПоМесяцамНарастающие
ИЗ
ОборотыПоМесяцам КАК ОборотыПоМесяцам
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ОборотыПоМесяцам КАК ОборотыПоМесяцамКопия
ПО ОборотыПоМесяцам.Контрагент = ОборотыПоМесяцамКопия.Контрагент
И ОборотыПоМесяцам.НачПериода <= ОборотыПоМесяцамКопия.НачПериода
СГРУППИРОВАТЬ ПО
ОборотыПоМесяцам.НачПериода,
ОборотыПоМесяцам.КонПериода,
ОборотыПоМесяцам.Контрагент,
ОборотыПоМесяцам.Сумма
;
Временная таблица "ОборотыПоМесяцамнНарастающие"
|
Контрагент |
НачПериода |
КонПериода |
Сумма |
СуммаДо | СуммаПосле |
|
Компания |
01.09.09 |
30.09.09 |
100 |
180 | 280 |
|
Компания |
01.10.09 |
31.10.09 |
80 |
100 | 180 |
|
Компания |
01.11.09 |
30.11.09 |
100 |
0 | 100 |
3. Найдем строку, интервал которой от "СуммаДо " до "СуммаПосле" содержит в себе значение долга (=200) , используя внутренне соединение таблиц "Долги" и "ОборотыПоМесяцамНарастающие".
ВЫБРАТЬ
Долги.Контрагент,
Долги.Долг,
Долги.ДатаОтсрочки,
ОборотыПоМесНарастающие.НачПериода,
ОборотыПоМесНарастающие.КонПериода,
Долги.Долг - ОборотыПоМесНарастающие.СуммаДо КАК ОстатокДолга
ПОМЕСТИТЬ ДолгиПоВыбраннымМесяцам
ИЗ
Справочник.Долги КАК Долги
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ОборотыПоМесяцамНарастающие КАК ОборотыПоМесНарастающие
ПО Долги.Контрагент = ОборотыПоМесНарастающие.Контрагент
И Долги.Долг > ОборотыПоМесНарастающие.СуммаДо
И Долги.Долг <= ОборотыПоМесНарастающие.СуммаПосле
;
Временная таблица "ДолгиПовыбраннымМесяцам" Контрагент НачПериода КонПериода Долг Компания 01.09.09 30.09.09 200
ДатаОтсрочки
ОстатокДолга
01.11.09
20
4. Выберем из таблицы "Обороты" документы только за указанный период
ВЫБРАТЬ
Обороты.Контрагент,
Обороты.Документ,
Обороты.Период,
ДолгиПоВыбМесяцам.Долг,
ДолгиПоВыбМесяцам.ОстатокДолга,
Обороты.Сумма,
ДолгиПоВыбМесяцам.ДатаОтсрочки
ПОМЕСТИТЬ ДвиженияПоВыбраннымМесяцам
ИЗ
Справочник.Обороты КАК Обороты
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ДолгиПоВыбраннымМесяцам КАК ДолгиПоВыбМесяцам
ПО Обороты.Контрагент = ДолгиПоВыбМесяцам.Контрагент
И Обороты.Период >= ДолгиПоВыбМесяцам.НачПериода
И Обороты.Период <= ДолгиПоВыбМесяцам.КонПериода
;
Временная таблица "ДвиженияПоВыбраннымМесяцам"
|
Контрагент |
Период |
Рег-р |
Сумма |
Долг |
ОстатокДолга |
ДатаОтсрочки |
|
Компания |
10.09.09 |
Накл 1 |
40 |
200 |
20 |
01.11.09 |
|
Компания |
20.10.09 |
Накл. 2 |
60 |
200 |
20 |
01.11.09 |
5. Получим нарастающие итоги по документам
ВЫБРАТЬ
ДвиженияПоВыбМесяцам.Контрагент,
ДвиженияПоВыбМесяцам.Документ,
ДвиженияПоВыбМесяцам.Период,
ДвиженияПоВыбМесяцам.Сумма,
СУММА(ДвиженияПоВыбМесяцамКопия.Сумма) КАК СуммаПосле,
СУММА(ДвиженияПоВыбМесяцамКопия.Сумма) - ДвиженияПоВыбМесяцам.Сумма КАК СуммаДо,
ДвиженияПоВыбМесяцам.ОстатокДолга,
ДвиженияПоВыбМесяцам.ДатаОтсрочки
ПОМЕСТИТЬ ДвиженияПредварительные
ИЗ
ДвиженияПоВыбраннымМесяцам КАК ДвиженияПоВыбМесяцам
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ДвиженияПоВыбраннымМесяцам КАК ДвиженияПоВыбМесяцамКопия
ПО ДвиженияПоВыбМесяцам.Контрагент = ДвиженияПоВыбМесяцамКопия.Контрагент
И ДвиженияПоВыбМесяцам.Период <= ДвиженияПоВыбМесяцамКопия.Период
СГРУППИРОВАТЬ ПО
ДвиженияПоВыбМесяцам.Контрагент,
ДвиженияПоВыбМесяцам.Документ,
ДвиженияПоВыбМесяцам.Период,
ДвиженияПоВыбМесяцам.Сумма,
ДвиженияПоВыбМесяцам.ОстатокДолга,
ДвиженияПоВыбМесяцам.ДатаОтсрочки
;
Временная таблица "ДвиженияПредварительные "
|
Контрагент |
Период |
.... |
ОстатокДолга |
СуммаДо |
СуммаПосле |
|
Компания |
10.09.09 |
.... |
20 |
60 |
100 |
|
Компания |
20.10.09 |
.... |
20 |
0 |
60 |
6. По "ОстаткуДолга" =20 определим единственную строку и выведем ее в таблицу "ДвиженияОкончательные"
ВЫБРАТЬ
ДвиженияПредв.Контрагент,
ДвиженияПредв.Документ,
ДвиженияПредв.Период,
ДвиженияПредв.ОстатокДолга - ДвиженияПредв.СуммаДо КАК СуммаДолга,
ДвиженияПредв.Сумма,
ДвиженияПредв.ДатаОтсрочки
ПОМЕСТИТЬ ДвиженияОкончательные
ИЗ
ДвиженияПредварительные КАК ДвиженияПредв
ГДЕ
ДвиженияПредв.ОстатокДолга > ДвиженияПредв.СуммаДо
И ДвиженияПредв.ОстатокДолга <= ДвиженияПредв.СуммаПосле
;
Временная таблица "ДвиженияОкончательные"
|
Контрагент |
Период |
.... |
ОстатокДолга |
СуммаДо |
СуммаПосле |
|
Компания |
20.10.09 |
.... |
20 |
0 |
60 |
7. Используя таблицу "ДвиженияОкончательные" и внутреннее соединение с исходной таблицей "Обороты" получим выходную таблицу запроса.
ВЫБРАТЬ
Обороты.Контрагент,
Обороты.Период,
Обороты.Документ,
Обороты.Сумма,
ВЫБОР
КОГДА Обороты.Документ = ДвиженияОконч.Документ
ТОГДА ДвиженияОконч.СуммаДолга
ИНАЧЕ Обороты.Сумма
КОНЕЦ КАК СуммаДолга,
///
ВЫБОР
КОГДА Обороты.Период < ДвиженияОконч.ДатаОтсрочки
ТОГДА ВЫБОР
КОГДА Обороты.Документ = ДвиженияОконч.Документ
ТОГДА ДвиженияОконч.СуммаДолга
ИНАЧЕ Обороты.Сумма
КОНЕЦ
ИНАЧЕ 0
КОНЕЦ КАК СуммаПросроченногоДолга
ИЗ
Справочник.Обороты КАК Обороты
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ДвиженияОкончательные КАК ДвиженияОконч
ПО Обороты.Контрагент = ДвиженияОконч.Контрагент
И Обороты.Период >= ДвиженияОконч.Период
Выходная таблица "ПросроченныеДолги"
|
Контрагент |
Период |
Рег-р |
Сумма |
Долг |
Просроченный долг |
|
Компания |
20.09.09 |
Накл. 2 |
60 |
20 |
20 |
|
Компания |
31.10.09 |
Накл. 3 |
80 |
80 |
80 |
|
Компания |
25.11.09 |
Накл. 4 |
100 |
100 |
0 |
В прикрепленном к статье файле "ПросроченныйДолг.dt"(26Кб) находится небольшая демонстрационная конфигурация,содержащая :
- справочники "Контрагенты","Долги","Обороты".
- отчет "ПросроченныйДолг".
После запуска конфигурации см. Рисунок ниже :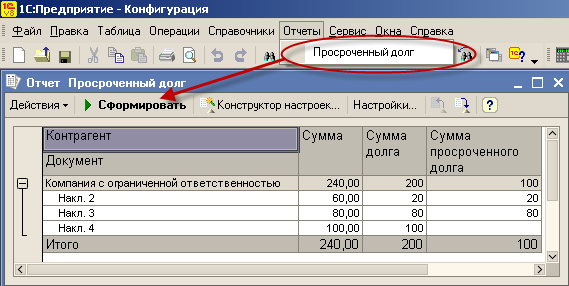
Приложение .
Что такое нарастающие итоги ? И зачем они нужны ?
Дана таблица с именем «Таблица» наших месячных оборотов :
|
Месяц |
Оборот |
|
Сентябрь |
100 |
|
Октябрь |
80 |
|
Ноябрь |
100 |
Вопрос : В каком месяце мы достигли суммарного оборота 200 ,начиная с сентября ?
Решение.
Представим , что у нас в языке 1с нет оператора цикла и «в лоб» перебрать строки таблицы мы не можем. Но у нас есть язык запросов.
Вначале сделаем «ненужный» вспомогательный запрос , проясняющий суть соединения по неравенству . Таблица "Таблица" соединяется "сама с собой".
Выбрать Т1.Месяц , Т1.Оборот, Т2.месяц,Т2.Оборот
ИЗ Таблица как Т1
ВнутреннееСоединение Таблица как Т2
по Т1.Месяц >=Т2.Месяц
|
Т1Месяц |
Т1Оборот |
Т2Месяц |
Т2Оборот |
|
Сентябрь |
100 |
Сентябрь |
100 |
|
Октябрь |
80 |
Сентябрь |
100 |
|
Октябрь |
80 |
Октябрь |
80 |
|
Ноябрь |
100 |
Сентябрь |
100 |
|
Ноябрь |
100 |
Октябрь |
80 |
|
Ноябрь |
100 |
Ноябрь |
100 |
Уберем из полей выборки лишние поля и сгруппируем по Т1Месяц с суммой поля Т2Оборот
Выбрать Т1.Месяц , Т1.Оборот, Сумма(Т2.Оборот) как СуммаПосле // так вот назвал
ИЗ Таблица как Т1
ВнутреннееСоединение Таблица как Т2
по Т1.Месяц >=Т2.Месяц
Сгруппировать ПО Т1.Месяц , Т1.Оборот
|
Т1Месяц |
Т1Оборот |
СуммаПосле |
|
Сентябрь |
100 |
100 |
|
Октябрь |
80 |
180 |
|
Ноябрь |
100 |
280 |
Но этого мало , в каждой строке нужно иметь интервал СуммаДо и СуммаПосле.
Поэтому перепишем запрос :
Выбрать Т1.Месяц , Т1.Оборот, Сумма(Т2.Оборот) как СуммаПосле ,
Сумма(Т2.Оборот) – Т1.Оборот как СуммаДо
ИЗ Таблица как Т1
ВнутреннееСоединение Таблица как Т2
по Т1.Месяц >=Т2.Месяц
Сгруппировать ПО Т1.Месяц , Т1.Оборот
|
Т1Месяц |
Т1Оборот |
СуммаДо |
СуммаПосле |
|
Сентябрь |
100 |
0 |
100 |
|
Октябрь |
80 |
100 |
180 |
|
Ноябрь |
100 |
180 |
280 |
Теперь нужно определить в какой строке выполняется двойное неравенство
СуммаДо <= 200 <= CуммаПосле. Или , другими словами, в каком месяце мы достигли оборота со значением 200.
Для этого поместим результат первого запроса во временную таблицу Итоги и приведем весь пакетный запрос решения :
Выбрать Т1.Месяц , Т1.Оборот, Сумма(Т2.Оборот) как СуммаПосле ,
Сумма(Т2.Оборот) – Т1.Оборот как СуммаДо
ПОМЕСТИТЬ Итоги
ИЗ Таблица как Т1
ВнутреннееСоединение Таблица как Т2
по Т1.Месяц >=Т2.Месяц
Сгруппировать ПО Т1.Месяц , Т1.Оборот
;
Выбрать Итоги.Т1Месяц,Итоги.Т1Оборот,Итоги.СуммаДо , Итоги.СуммаПосле
ИЗ Итоги как Итоги
ГДЕ 200 >Итоги.СуммаДо и 200 <=Итогм.СуммаПосле
Выходная таблица решения :
|
Т1Месяц |
Т1Оборот |
СуммаДо |
СуммаПосле |
|
Ноябрь |
100 |
180 |
280 |
Вывод : нарастающие итоги (значения колонок СуммаДо и СуммаПосле, задающих определенный интервал) нужны в контексте темы статьи для поиска некоторого определенного значения (Оборот = 200).
Примечание : Представим, что исходная таблица "Таблица" имеет миллионы записей . Тогда какого размера достигнет таблица в результате соединения "сама с собой" ( первый запрос в приложении) ?
Поэтому нарастающие итоги применять нужно для таблиц ограниченного
размера. В этом весь смысл приведенного в статье алгоритма :
нарастающие итоги применяются сначала для поиска в небольшой таблице месячных итогов , затем "вырезается" интервал в таблице "Обороты" и в этом небольшом месячном интервале снова используются нарастающие итоги для поиска нужного значения оборотов.