
Быстрый поиск по запросу "математи*" по ИС выдаёт всего одну статью с набором полезных математических функций:
Библиотека математических функций 1.1
Отличная статья, но перечень функций в основном предназначен для матриц. В моём случае понадобилось обрабатывать одномерные массивы чисел. Получился небольшой набор простых функций, которыми хочу поделиться со всеми нуждающимися и достаточно ленивыми, чтобы писать самостоятельно.
Функция Сумма(Массив) Экспорт
Если Массив.Количество() = 0 Тогда Возврат 0 КонецЕсли;
ТЗ = Новый ТаблицаЗначений;
ТЗ.Колонки.Добавить("Сумма");
Для ё = 1 по Массив.Количество() Цикл
ТЗ.Добавить();
КонецЦикла;
ТЗ.ЗагрузитьКолонку(Массив, "Сумма");
Сумма = ТЗ.Итог("Сумма");
Возврат Сумма;
КонецФункции
Функция Минимум(Массив) Экспорт
Если Массив.Количество() = 0 Тогда Возврат Неопределено КонецЕсли;
УпорядочитьМассив(Массив);
Возврат Массив[0];
КонецФункции
Функция Среднее(Массив) Экспорт
Если Массив.Количество() = 0 Тогда Возврат Неопределено КонецЕсли;
Возврат Сумма(Массив) / Массив.Количество();
КонецФункции
Функция Максимум(Массив) Экспорт
Если Массив.Количество() = 0 Тогда Возврат Неопределено КонецЕсли;
УпорядочитьМассив(Массив);
Возврат Массив[Массив.Количество() - 1];
КонецФункции
Функция Медиана(Массив) Экспорт
Если Массив.Количество() = 0 Тогда Возврат Неопределено КонецЕсли;
КоличествоЭлементов = Массив.Количество();
Если КоличествоЭлементов = 1 Тогда
Возврат Массив[0];
ИначеЕсли КоличествоЭлементов = 2 Тогда
Возврат Среднее(Массив);
КонецЕсли;
УпорядочитьМассив(Массив);
Середина = КоличествоЭлементов / 2;
Если Середина = Цел(Середина) Тогда
Медиана = (Массив[Середина - 1] + Массив[Середина]) / 2;
Иначе
Медиана = Массив[Середина - 0.5]
КонецЕсли;
Возврат Медиана;
КонецФункции
Функция Дисперсия(Массив) Экспорт
Если Массив.Количество() = 0 Тогда Возврат Неопределено КонецЕсли;
Среднее = Среднее(Массив);
Сумма = 0;
Для каждого Значение из Массив Цикл
Сумма = Сумма + Pow((Значение - Среднее), 2);
КонецЦикла;
Дисперсия = Сумма / Массив.Количество();//имеется ввиду генеральная дисперсия, для получения несмещённой добавить в делителе -1
Возврат Дисперсия;
КонецФункции
Функция СреднеКвадратичноеОтклонение(Массив) Экспорт
Если Массив.Количество() = 0 Тогда Возврат Неопределено КонецЕсли;
Дисперсия = Дисперсия(Массив);
Возврат ?(Дисперсия < 0, 0, Sqrt(Дисперсия));
КонецФункции
Процедура УпорядочитьМассив(Массив) Экспорт
СЗ = Новый СписокЗначений;
СЗ.ЗагрузитьЗначения(Массив);
СЗ.СортироватьПоЗначению(НаправлениеСортировки.Возр);
Массив = СЗ.ВыгрузитьЗначения();
КонецПроцедуры
Для получения крайних значений использую упорядочивание массива, так как в результате тестирования на разных количествах реальных данных такой вариан выдал лучшие показатели, чем перебор со сравнением текущего значения с минимальным/максимальным.
Также возникла необходимость проверить входят ли значения одного массива в крайние положения другого с учётом допустимого процента отклонения:
Функция МинимумКП(МассивПолный, МассивТекущий, ПроцентОтклонения, ВернутьКоличество = Ложь) Экспорт
Минимум = Минимум(МассивПолный);
ПроцентХ = Минимум / 100 * (100 + ПроцентОтклонения);
сч = 0;
Для каждого Значение из МассивТекущий Цикл
Если Значение >= Минимум и Значение <= ПроцентХ Тогда
Если ВернутьКоличество Тогда
сч = сч + 1;
Иначе
Возврат Истина;
КонецЕсли;
КонецЕсли;
КонецЦикла;
Если ВернутьКоличество Тогда Возврат сч КонецЕсли;
Возврат Ложь;
КонецФункции
Функция МаксимумКП(МассивПолный, МассивТекущий, ПроцентОтклонения, ВернутьКоличество = Ложь) Экспорт
Максимум = Максимум(МассивПолный);
ПроцентХ = Максимум / 100 * (100 - ПроцентОтклонения);
сч = 0;
Для каждого Значение из МассивТекущий Цикл
Если Значение >= ПроцентХ и Значение <= Максимум Тогда
Если ВернутьКоличество Тогда
сч = сч + 1;
Иначе
Возврат Истина;
КонецЕсли;
КонецЕсли;
КонецЦикла;
Если ВернутьКоличество Тогда Возврат сч КонецЕсли;
Возврат Ложь;
КонецФункции
У данных функций есть параметр ВернутьКоличество, при установке значения которого в Истина функция возвращает количество значений, попавших в диапазон, иначе вернёт булево (есть пападания/нет).
В дополнение прикладываю обработку с примером использования и возможностью поиграться. Источником данных является таблица значений. необходимые данные с отбором удобно получать при помощи функции ПолучитьМассивДанных();
Надеюсь, кому-то может оказаться полезным.

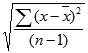

{kind=link}