Проблема с быстродействием конфигураций 1С в связке с Debian 11 и PostgreSQL Pro
Суть проблемы.
После установки на железный сервер Debian 11, PostgreSQL и сервера 1С:Предприятие поработать с конфигурациями как-то не получается. Запускается 1,5Гб база ЗУП около 2 минут, элемент справочника Сотрудники открывается 20-30 секунд, про формирование отчетов молчу. Такая же примерно ситуация наблюдается и на пустых конфигурациях, новый элемент пустого справочника создается и открывается по несколько секунд. Аналогичная проблема с pgAdmin крайней версии - очень медленно работает и постоянно теряет связь с сервером.
Путь к проблеме.
Debian 11 устанавливал по инструкции. Там же описана установка , условия для дистрибутива указал Postgres 14 и Debian. Сервер 1С:Предприятие устанавливал из дистрибутива с ИТС, версия 8.3.20.1789-х64. Ключ HASP стоит аппаратный, драйвера качал из репозитория etersoft версии 7.90 (haspd-modules_7.90-eter2debian_i386.deb). По указанному в статье довольно странный набор драйверов, крайние свежие есть только в виде одного файла и то для другой версии Debian. Устанавливал его, но сервер 1С запускаться отказывался. В итоге установил оба драйвера версии 7.90, тогда сервер стартовал.
Файл postgresql.conf в прикрепленных файлах.
Postgresql.conf настраивал через и по советам из профильных статей Инфостарта.
Согласно рекомендациям в книге включил работу с большими страницами.
pg_wal символьной ссылкой перенес на один из рейдов (два диска в RAID 1), файлы баз данных располагаются на другом такого же типа рейде, но эту настройку делал при помощи tablespace в pgAdmin. Система на третьем рейде.
Настройки сервера 1С:Предприятие в прикрепленных файлах.
Информация о железе в прикрепленных файлах.
Сервер не в домене.
Прошу сообщество помочь победить проблему. Если на указанной конфигурации с любыми настройками все так и будет работать - хотел бы получить пояснение для понимания. Если я что-то не сделал - сетевые настройки, firewall, порты, настройки СУБД или сервера - также прошу подсказать и по возможности направить.
После установки на железный сервер Debian 11, PostgreSQL и сервера 1С:Предприятие поработать с конфигурациями как-то не получается. Запускается 1,5Гб база ЗУП около 2 минут, элемент справочника Сотрудники открывается 20-30 секунд, про формирование отчетов молчу. Такая же примерно ситуация наблюдается и на пустых конфигурациях, новый элемент пустого справочника создается и открывается по несколько секунд. Аналогичная проблема с pgAdmin крайней версии - очень медленно работает и постоянно теряет связь с сервером.
Путь к проблеме.
Debian 11 устанавливал по инструкции. Там же описана установка , условия для дистрибутива указал Postgres 14 и Debian. Сервер 1С:Предприятие устанавливал из дистрибутива с ИТС, версия 8.3.20.1789-х64. Ключ HASP стоит аппаратный, драйвера качал из репозитория etersoft версии 7.90 (haspd-modules_7.90-eter2debian_i386.deb). По указанному в статье довольно странный набор драйверов, крайние свежие есть только в виде одного файла и то для другой версии Debian. Устанавливал его, но сервер 1С запускаться отказывался. В итоге установил оба драйвера версии 7.90, тогда сервер стартовал.
Сетевые настройки |
|---|
ifconfig 14:40
eno1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.4.2.17 netmask 255.0.0.0 broadcast 10.255.255.255
inet6 fe80::6eae:8bff:fe62:11da prefixlen 64 scopeid 0x20[*]
ether 6c:ae:8b:62:11:da txqueuelen 1000 (Ethernet)
RX packets 2960956 bytes 1972685937 (1.8 GiB)
RX errors 0 dropped 2311 overruns 0 frame 0
TX packets 922968 bytes 133748564 (127.5 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
device memory 0xa9a60000-a9a7ffff
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 38992468 bytes 19025124260 (17.7 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 38992468 bytes 19025124260 (17.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 Показать |
Файл postgresql.conf в прикрепленных файлах.
Postgresql.conf настраивал через и по советам из профильных статей Инфостарта.
Согласно рекомендациям в книге включил работу с большими страницами.
pg_wal символьной ссылкой перенес на один из рейдов (два диска в RAID 1), файлы баз данных располагаются на другом такого же типа рейде, но эту настройку делал при помощи tablespace в pgAdmin. Система на третьем рейде.
Настройки сервера 1С:Предприятие в прикрепленных файлах.
Информация о железе в прикрепленных файлах.
Сервер не в домене.
Прошу сообщество помочь победить проблему. Если на указанной конфигурации с любыми настройками все так и будет работать - хотел бы получить пояснение для понимания. Если я что-то не сделал - сетевые настройки, firewall, порты, настройки СУБД или сервера - также прошу подсказать и по возможности направить.
Прикрепленные файлы:
postgresql.conf
lshw_info
srv1cv83.conf
Ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
(2) Если Вы об этом:
У меня так на сервере. То есть не powersave. Можно конечно попробовать поменять на performance...
UPD. Сразу попробовал. Стало так:
На скорость работы 1С не повлияло никак.
scaling_governor |
|---|
| cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor 16:50
schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil schedutil cat /proc/cpuinfo| grep MHz 16:51 cpu MHz : 1599.787 cpu MHz : 1601.509 cpu MHz : 1600.064 cpu MHz : 1276.777 cpu MHz : 1600.356 cpu MHz : 1597.989 cpu MHz : 1199.821 cpu MHz : 1200.029 cpu MHz : 1200.117 cpu MHz : 1200.047 cpu MHz : 1200.049 cpu MHz : 1199.948 cpu MHz : 1600.064 cpu MHz : 1421.895 cpu MHz : 1271.030 cpu MHz : 1476.571 cpu MHz : 1599.934 cpu MHz : 1565.376 cpu MHz : 1200.022 cpu MHz : 1200.037 cpu MHz : 1199.814 cpu MHz : 1200.027 cpu MHz : 1199.978 cpu MHz : 1200.099 |
У меня так на сервере. То есть не powersave. Можно конечно попробовать поменять на performance...
UPD. Сразу попробовал. Стало так:
scaling_governor |
|---|
| cat /proc/cpuinfo| grep MHz 17:06
cpu MHz : 2440.371 cpu MHz : 1255.620 cpu MHz : 2253.460 cpu MHz : 1561.249 cpu MHz : 1396.199 cpu MHz : 2398.978 cpu MHz : 1200.005 cpu MHz : 1200.123 cpu MHz : 2499.955 cpu MHz : 2220.088 cpu MHz : 1643.772 cpu MHz : 1879.946 cpu MHz : 2348.939 cpu MHz : 2455.281 cpu MHz : 2417.821 cpu MHz : 2236.153 cpu MHz : 2363.481 cpu MHz : 2373.275 cpu MHz : 1200.028 cpu MHz : 1580.531 cpu MHz : 2500.182 cpu MHz : 1673.228 cpu MHz : 1604.723 cpu MHz : 1502.545 |
На скорость работы 1С не повлияло никак.
#listen_addresses = 'localhost' # what IP address(es) to listen on;
# comma-separated list of addresses;
# defaults to 'localhost'; use '*' for all
# (change requires restart)
#port = 5432 # (change requires restart)
#max_connections = 20
или комментарии только у меня...
шутка ?
а, извините, до конца не посмотрел...
# comma-separated list of addresses;
# defaults to 'localhost'; use '*' for all
# (change requires restart)
#port = 5432 # (change requires restart)
#max_connections = 20
или комментарии только у меня...
шутка ?
а, извините, до конца не посмотрел...
(4) Если Вы про postgrsql.conf - это один из вопросов, которые мне самому интересны, спрашивал об этом в соседней теме. У меня в этом файле все отличные от дефолтных настройки указаны в конце файла. Интересно - так и должно быть или по правилам хорошего тона надо раскомментировать конкретные строки с параметрами и менять их значения? И вообще тот формат файла что у меня правильный или указанные настройки скопом в конце файла не будут работать и поэтому у меня все так "летает"?
checkpoint_timeout = 15min
лично мне не нравится время
logging_collector = on # Enable capturing of stderr and csvlog
ну и что вы логируете ???
autovacuum = on # Enable autovacuum subprocess? 'on'
track_counts --- у вас в комментах
--------------
сложновато читать,когда все в низу :)
лично мне не нравится время
logging_collector = on # Enable capturing of stderr and csvlog
ну и что вы логируете ???
autovacuum = on # Enable autovacuum subprocess? 'on'
track_counts --- у вас в комментах
--------------
сложновато читать,когда все в низу :)
(6) Время должно быть меньше или больше? Пока читал книгу - вроде чем меньше время, тем чаще будет сбрасываться копия данных на диск и будет увеличиваться время отклика... logging_collector отключить. autovacuum и track_counts включить.
(7) Сюда за этим и пришел, за советом специалиста. Я еще никак не делаю бекап - подобная связка ПО для меня полностью новая. Я для начала просто не смог запустить нормально конфигурацию, какой тут бекап...
(8) Сбои у нас постоянно, резервного вроде хватает. Что Вы имеете в виду? fsync?
(7) Сюда за этим и пришел, за советом специалиста. Я еще никак не делаю бекап - подобная связка ПО для меня полностью новая. Я для начала просто не смог запустить нормально конфигурацию, какой тут бекап...
(8) Сбои у нас постоянно, резервного вроде хватает. Что Вы имеете в виду? fsync?
(9)
тем чаще будет сбрасываться копия данных на диск
тем большая нагрузка на диск и тем сильнее последствие влияния для других
разве только у вас ССД ?
чтобы увидели разницу - установите 60мин
max_connections = 500 --- если у вас столько клиентов, если нет - оставьте реальное,умноженное на 1,5-2
track_counts включить,чтобы работал автовакуум должным образом.
это минимум, а максимум - пересмотреть места и способы установки.
вы пробовали восстановление на рейдах и есть ли запасные в наличии для замены "здесь и сейчас" ?
если цена простоя у вас 15 минут, то да RAID , UPS , NVME .
если возможность простоя от 60мин не критическая - лучше бекап и архив.
тем чаще будет сбрасываться копия данных на диск
тем большая нагрузка на диск и тем сильнее последствие влияния для других
разве только у вас ССД ?
чтобы увидели разницу - установите 60мин
max_connections = 500 --- если у вас столько клиентов, если нет - оставьте реальное,умноженное на 1,5-2
track_counts включить,чтобы работал автовакуум должным образом.
это минимум, а максимум - пересмотреть места и способы установки.
вы пробовали восстановление на рейдах и есть ли запасные в наличии для замены "здесь и сейчас" ?
если цена простоя у вас 15 минут, то да RAID , UPS , NVME .
если возможность простоя от 60мин не критическая - лучше бекап и архив.
(11) track_counts и logging_collector не трогаю (включены по умолчанию)
(7) Раздел WRITE-AHEAD LOG действительно не трогал, хотя в начале своих попыток настройки пробовал отключать fsync (fsync=off), но так как в интернете прочитал, что в таком случае восстанавливать базу придется из резервной копии исключительно (при сбое) и по быстродействию никакого выигрыша отключение этого параметра не дало все вернул в исходное (по умолчанию, fsync=on).
(10) сменил checkpoint_timeout на 60 минут
max_connections = 100 (максимум 30 пользователей в базе)
По быстродействию самой конфигурации - реакции никакой, хотя pgbench выдал tps в два раза больше, чем вчера
Восстановление на рейде не пробовал, так как еще не настраивал даже резервное копирование. Если имеете в виду восстановление информации на рейде - также не пробовал, так как пока еще ничего не падало. Горячая замена не предусмотрена, менять не на что.
Бэкап и архив собираюсь настраивать после того, как разберусь с проблемами работоспособности собственно базы. Читал про бэкап в PostgreSQL довольно поверхностно, там есть pg_dump, есть скрипты для этого. Расположение журналов влияет на работу pg_dump?
(7) Раздел WRITE-AHEAD LOG действительно не трогал, хотя в начале своих попыток настройки пробовал отключать fsync (fsync=off), но так как в интернете прочитал, что в таком случае восстанавливать базу придется из резервной копии исключительно (при сбое) и по быстродействию никакого выигрыша отключение этого параметра не дало все вернул в исходное (по умолчанию, fsync=on).
(10) сменил checkpoint_timeout на 60 минут
max_connections = 100 (максимум 30 пользователей в базе)
По быстродействию самой конфигурации - реакции никакой, хотя pgbench выдал tps в два раза больше, чем вчера
pgbench |
|---|
| pgbench -c 24 -j 12 -T 300 zup3
pgbench (14.2) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 1 query mode: simple number of clients: 24 number of threads: 12 duration: 300 s number of transactions actually processed: 946154 latency average = 7.610 ms initial connection time = 16.517 ms tps = 3153.936123 (without initial connection time) |
Восстановление на рейде не пробовал, так как еще не настраивал даже резервное копирование. Если имеете в виду восстановление информации на рейде - также не пробовал, так как пока еще ничего не падало. Горячая замена не предусмотрена, менять не на что.
Бэкап и архив собираюсь настраивать после того, как разберусь с проблемами работоспособности собственно базы. Читал про бэкап в PostgreSQL довольно поверхностно, там есть pg_dump, есть скрипты для этого. Расположение журналов влияет на работу pg_dump?
(16) Локально у меня странное поведение pgbench... С одним потоком и сеансом отработал
С прошлыми параметрами отказался
pgbench -h 10.4.2.17 -p 5432 -U postgres -c 1 -j 1 -T 300 zup3 |
|---|
| pgbench -h 10.4.2.17 -p 5432 -U postgres -c 1 -j 1 -T 300 zup3
Password: pgbench (14.2) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 1 query mode: simple number of clients: 1 number of threads: 1 duration: 300 s number of transactions actually processed: 50299 latency average = 5.964 ms initial connection time = 6.824 ms tps = 167.663358 (without initial connection time) |
С прошлыми параметрами отказался
pgbench -h 10.4.2.17 -p 5432 -U postgres -c 24 -j 12 -T 300 zup3 |
|---|
| pgbench -h 10.4.2.17 -p 5432 -U postgres -c 24 -j 12 -T 300 zup3
Password: pgbench (14.2) starting vacuum...end. pgbench: pgbench: pgbench: pgbench: pgbench: pgbench: pgbench: pgbench: pgbench: pgbench: pgbench: pgbench: fatal: too many client connections for select() fatal: |
(21)
Видимо 80Гб. shared_buffers = 20GB и effective_cache_size = 60GB. На сервере всего 128Гб ОЗУ. Или я Вас не понял?
postgresql.conf |
|---|
| max_connections = 100
listen_addresses = '*' shared_buffers = 20GB # 25% of RAM temp_buffers = 128MB work_mem = 256MB maintenance_work_mem = 2GB max_files_per_process = 10000 max_worker_processes = 24 max_parallel_workers_per_gather = 4 max_parallel_workers = 24 max_parallel_maintenance_workers = 6 # Количество CPU/4, минимум 2, максимум 6 min_wal_size = 1GB max_wal_size = 4GB checkpoint_timeout = 60min checkpoint_completion_target = 0.9 effective_cache_size = 60GB # 75% of RAM from_collapse_limit = 8 join_collapse_limit = 8 autovacuum_max_workers = 12 # Количество CPU/2, минимум 2 vacuum_cost_limit = 1200 # 100* autovacuum_max_workers autovacuum_naptime = 20s autovacuum_vacuum_scale_factor = 0.01 autovacuum_analyze_scale_factor = 0.005 max_locks_per_transaction = 256 escape_string_warning = off standard_conforming_strings = off shared_preload_libraries = 'online_analyze, plantuner' online_analyze.threshold = 50 online_analyze.scale_factor = 0.1 online_analyze.enable = on online_analyze.verbose = off online_analyze.min_interval = 10000 online_analyze.table_type = 'temporary' plantuner.fix_empty_table = on wal_buffers = 16MB default_statistics_target = 100 random_page_cost = 4 effective_io_concurrency = 2 |
Видимо 80Гб. shared_buffers = 20GB и effective_cache_size = 60GB. На сервере всего 128Гб ОЗУ. Или я Вас не понял?
(23) Поменял на указанное значение. В производительности - без изменений.
Теперь так
Теперь так
postgresql.conf |
|---|
| #------------------------------------------------------------------------------
# CUSTOMIZED OPTIONS #------------------------------------------------------------------------------ # Add settings for extensions here max_connections = 100 listen_addresses = '*' shared_buffers = 20GB # 25% of RAM temp_buffers = 128MB work_mem = 104857kB maintenance_work_mem = 2GB max_files_per_process = 10000 max_worker_processes = 24 max_parallel_workers_per_gather = 4 max_parallel_workers = 24 max_parallel_maintenance_workers = 6 # Количество CPU/4, минимум 2, максимум 6 min_wal_size = 1GB max_wal_size = 4GB checkpoint_timeout = 60min checkpoint_completion_target = 0.9 effective_cache_size = 60GB # 75% of RAM from_collapse_limit = 8 join_collapse_limit = 8 autovacuum_max_workers = 12 # Количество CPU/2, минимум 2 vacuum_cost_limit = 1200 # 100* autovacuum_max_workers autovacuum_naptime = 20s autovacuum_vacuum_scale_factor = 0.01 autovacuum_analyze_scale_factor = 0.005 max_locks_per_transaction = 256 escape_string_warning = off standard_conforming_strings = off shared_preload_libraries = 'online_analyze, plantuner' online_analyze.threshold = 50 online_analyze.scale_factor = 0.1 online_analyze.enable = on online_analyze.verbose = off online_analyze.min_interval = 10000 online_analyze.table_type = 'temporary' plantuner.fix_empty_table = on wal_buffers = 16MB default_statistics_target = 100 random_page_cost = 4 effective_io_concurrency = 2 |
если у вас 1с сервер на винде, а слон на линуксе,
то проблема еще и в настройках сети ( файрволы и iptables )
ну и сам сервер 1с не исключение
( тут я точно не помогу )
посмотрите в реальном времени, что загружено :
проц, диски, сеть .
там и узкое место.
если Тетя Дуня качает сериал , то сетка не даст прорваться 1С
то проблема еще и в настройках сети ( файрволы и iptables )
ну и сам сервер 1с не исключение
( тут я точно не помогу )
посмотрите в реальном времени, что загружено :
проц, диски, сеть .
там и узкое место.
если Тетя Дуня качает сериал , то сетка не даст прорваться 1С
(27) Тут (19) спросили про версию pgbench, которую запускаю для тестирования. Обычно я ее запускаю непосредственно на сервере с PostgreSQL, решил попробовать запустить со своей рабочей машины (Win 10) через консоль. Установил PostgreSQL 14 себе на рабочую машину (Win 10) и запустил pgbench. На отличном от 1 значении сеансов и потоков утилита работать отказалась, о чем и сообщил. То есть когда запускал тестирование непосредственно на сервере - оно проходило нормально. По сети же - только в формате
pgbench -h 10.4.2.17 -p 5432 -U postgres -c 1 -j 1 -T 300 zup3
(30)
11 или 12
настройки могут различаться,
я годик назад с настройкой слона от 13 версии копировал на 12 - даже не запустился 12-ый
так что может быть и такое.
и все-таки посмотрите загрузку на железо,
если узкое место проц - да еще и диски в рейде, то ждать фантастических результатов не придется.
11 или 12
настройки могут различаться,
я годик назад с настройкой слона от 13 версии копировал на 12 - даже не запустился 12-ый
так что может быть и такое.
и все-таки посмотрите загрузку на железо,
если узкое место проц - да еще и диски в рейде, то ждать фантастических результатов не придется.
(34)
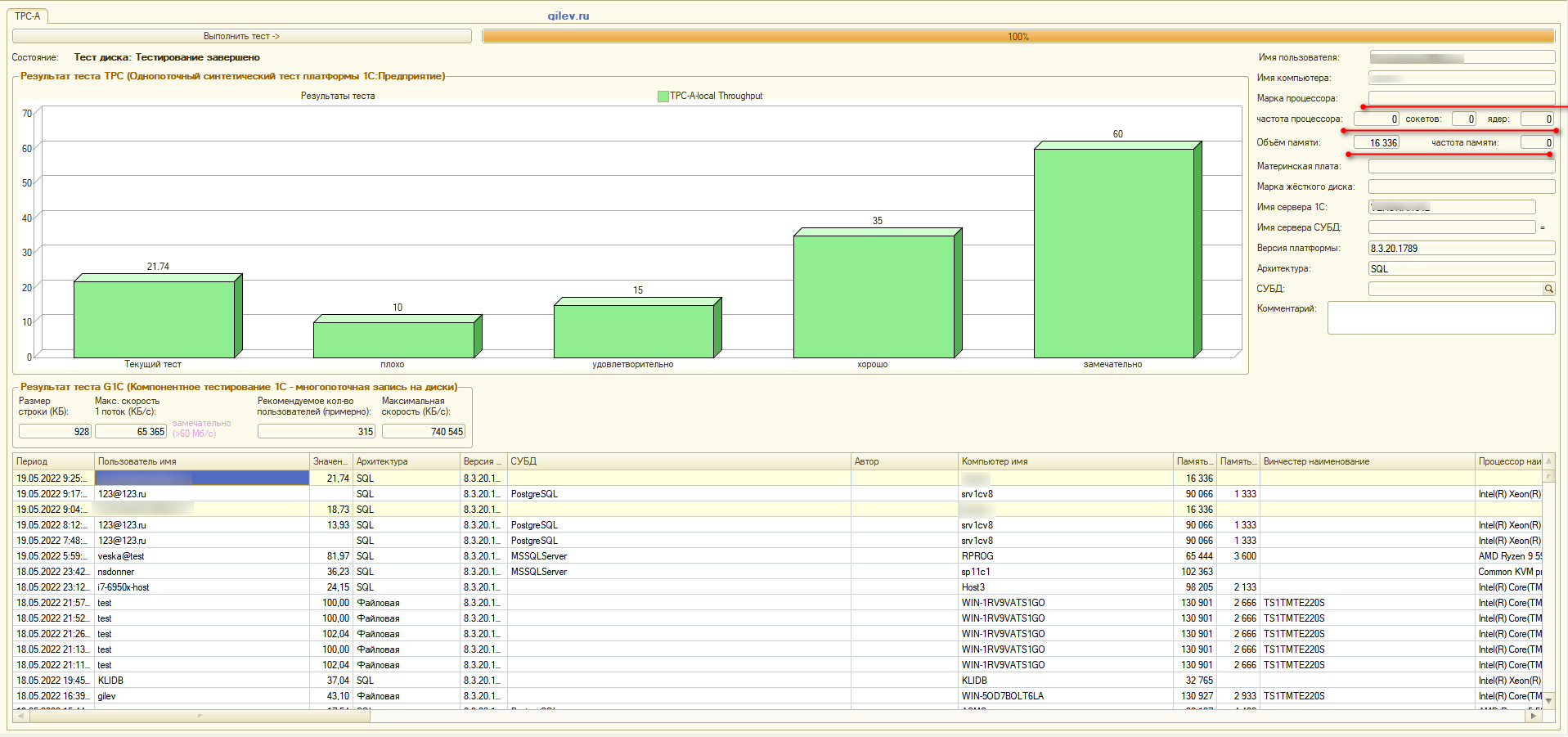
Тест установил аналогично рабочей конфигурации, с тем же tablespace.
Смущает только отсутствие данных о процессорах и объем памяти... Ощущение, что с локального ПК взял память.
По тесту получается, что работать не получится, правильно я понимаю? Что можно улучшить? Когда на этом же сервере стояла Windows + MSSQL эта же конфигурация работала в разы быстрее. После определенных событий решил перенести все на Linux + PostgreSQL.
Тест Гилева |
|---|
 |
Тест установил аналогично рабочей конфигурации, с тем же tablespace.
Смущает только отсутствие данных о процессорах и объем памяти... Ощущение, что с локального ПК взял память.
По тесту получается, что работать не получится, правильно я понимаю? Что можно улучшить? Когда на этом же сервере стояла Windows + MSSQL эта же конфигурация работала в разы быстрее. После определенных событий решил перенести все на Linux + PostgreSQL.
Прикрепленные файлы:
(36)
У Вас не в СУБД проблема - у Вас во что-то упирается клиент. Например, если в 1С пинг превышает 10 мс, то начинается такое вот поведение с очень долгим открытием форм. Так что копайте сеть. Хотя и это решается путем публикации базы на веб-сервере.
По тесту получается, что работать не получится, правильно я понимаю?
Тест в принципе нормальные цифры выдает, народ на 10-ти работает и не жужжит, хотя и не так быстро, но документы открываются вполне прилично.
У Вас не в СУБД проблема - у Вас во что-то упирается клиент. Например, если в 1С пинг превышает 10 мс, то начинается такое вот поведение с очень долгим открытием форм. Так что копайте сеть. Хотя и это решается путем публикации базы на веб-сервере.
(38)
Сетевых настроек на самом сервере вроде по минимуму, пинг до рабочей машины нормальный. Публикация на веб - это установка Apache и дальнейшие действия по публикации? Так все-таки попробовать посмотреть сетевые настройки пока, без переустановки СУБД на более раннюю версию?
ping до рабочей машины с сервера |
|---|
ping -t 10.4.7.39
ping: invalid argument: '10.4.7.39'
root@verona:~# ping 10.4.7.39
PING 10.4.7.39 (10.4.7.39) 56(84) bytes of data.
64 bytes from 10.4.7.39: icmp_seq=1 ttl=63 time=0.396 ms
64 bytes from 10.4.7.39: icmp_seq=2 ttl=63 time=2.05 ms
64 bytes from 10.4.7.39: icmp_seq=3 ttl=63 time=16.0 ms
64 bytes from 10.4.7.39: icmp_seq=4 ttl=63 time=0.504 ms
64 bytes from 10.4.7.39: icmp_seq=5 ttl=63 time=0.651 ms
64 bytes from 10.4.7.39: icmp_seq=6 ttl=63 time=0.731 ms
64 bytes from 10.4.7.39: icmp_seq=7 ttl=63 time=0.796 ms
64 bytes from 10.4.7.39: icmp_seq=8 ttl=63 time=1.68 ms
64 bytes from 10.4.7.39: icmp_seq=9 ttl=63 time=1.11 ms
64 bytes from 10.4.7.39: icmp_seq=10 ttl=63 time=0.773 ms
64 bytes from 10.4.7.39: icmp_seq=11 ttl=63 time=0.687 ms
64 bytes from 10.4.7.39: icmp_seq=12 ttl=63 time=0.721 ms
64 bytes from 10.4.7.39: icmp_seq=13 ttl=63 time=0.472 ms
64 bytes from 10.4.7.39: icmp_seq=14 ttl=63 time=1.44 ms
64 bytes from 10.4.7.39: icmp_seq=15 ttl=63 time=0.478 ms
64 bytes from 10.4.7.39: icmp_seq=16 ttl=63 time=0.496 ms
64 bytes from 10.4.7.39: icmp_seq=17 ttl=63 time=1.17 ms
64 bytes from 10.4.7.39: icmp_seq=18 ttl=63 time=0.662 ms
64 bytes from 10.4.7.39: icmp_seq=19 ttl=63 time=0.520 ms
64 bytes from 10.4.7.39: icmp_seq=20 ttl=63 time=1.22 ms
64 bytes from 10.4.7.39: icmp_seq=21 ttl=63 time=0.534 ms
64 bytes from 10.4.7.39: icmp_seq=22 ttl=63 time=0.521 ms
64 bytes from 10.4.7.39: icmp_seq=23 ttl=63 time=1.11 ms
64 bytes from 10.4.7.39: icmp_seq=24 ttl=63 time=0.786 ms
64 bytes from 10.4.7.39: icmp_seq=25 ttl=63 time=0.649 ms
64 bytes from 10.4.7.39: icmp_seq=26 ttl=63 time=0.820 ms
64 bytes from 10.4.7.39: icmp_seq=27 ttl=63 time=0.562 ms
64 bytes from 10.4.7.39: icmp_seq=28 ttl=63 time=0.620 ms
64 bytes from 10.4.7.39: icmp_seq=29 ttl=63 time=0.507 ms
64 bytes from 10.4.7.39: icmp_seq=30 ttl=63 time=0.488 ms
64 bytes from 10.4.7.39: icmp_seq=31 ttl=63 time=0.837 ms
64 bytes from 10.4.7.39: icmp_seq=32 ttl=63 time=0.720 ms
64 bytes from 10.4.7.39: icmp_seq=33 ttl=63 time=0.674 ms
64 bytes from 10.4.7.39: icmp_seq=34 ttl=63 time=0.868 ms
64 bytes from 10.4.7.39: icmp_seq=35 ttl=63 time=0.682 ms
64 bytes from 10.4.7.39: icmp_seq=36 ttl=63 time=0.818 ms
64 bytes from 10.4.7.39: icmp_seq=37 ttl=63 time=0.482 ms
64 bytes from 10.4.7.39: icmp_seq=38 ttl=63 time=2.05 ms
64 bytes from 10.4.7.39: icmp_seq=39 ttl=63 time=1.51 ms
64 bytes from 10.4.7.39: icmp_seq=40 ttl=63 time=0.528 ms
64 bytes from 10.4.7.39: icmp_seq=41 ttl=63 time=0.675 ms
64 bytes from 10.4.7.39: icmp_seq=42 ttl=63 time=0.496 ms Показать |
interfaces |
|---|
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
allow-hotplug eno1
iface eno1 inet static
address 10.4.2.17
gateway 10.4.2.1
# dns-* options are implemented by the resolvconf package, if installed
dns-nameservers 10.4.2.2 10.4.2.4
dns-search domain.com Показать |
Сетевых настроек на самом сервере вроде по минимуму, пинг до рабочей машины нормальный. Публикация на веб - это установка Apache и дальнейшие действия по публикации? Так все-таки попробовать посмотреть сетевые настройки пока, без переустановки СУБД на более раннюю версию?
Прикрепленные файлы:
(38) Опубликовал базу на веб-сервере (Apache). Через браузер работает с такой же скоростью.
Возможно это тоже важно - вчера перед уходом около 17.30 запустил очистку базы
Сегодня на 9 утра процесс все еще не завершился, сбрасывал через pgAdmin...
Возможно это тоже важно - вчера перед уходом около 17.30 запустил очистку базы
# vacuumdb --full --analyze --username postgres --dbname zup3Сегодня на 9 утра процесс все еще не завершился, сбрасывал через pgAdmin...
(40)
ping у вас достаточно нестабильный, даже в этом небольшом тесте есть ситуация, когда он превысил 2 мс. Вполне могут где-то теряться пакеты. Попробуйте сетевушку поменять на самую простую для начала.
Да, еще есть мнение, что ipv6 может влиять на доступ к системе в нехорошую сторону, но это не точно.
Через браузер работает с такой же скоростью.
Т.е. так же медленно? Пробовали тупо замер производительности дернуть? На чем основные потери времени?
ping у вас достаточно нестабильный, даже в этом небольшом тесте есть ситуация, когда он превысил 2 мс. Вполне могут где-то теряться пакеты. Попробуйте сетевушку поменять на самую простую для начала.
Да, еще есть мнение, что ipv6 может влиять на доступ к системе в нехорошую сторону, но это не точно.
(41)
Это просто запуск конфигурации (2 минуты) и открытие карточки сотрудника (2,5 минуты). Причем первый раз когда открывал окно замера производительности там было что-то по поводу загрузки новостей и это все было по времени от 60 до 70.
Т.е. так же медленно? Пробовали тупо замер производительности дернуть? На чем основные потери времени?
Это просто запуск конфигурации (2 минуты) и открытие карточки сотрудника (2,5 минуты). Причем первый раз когда открывал окно замера производительности там было что-то по поводу загрузки новостей и это все было по времени от 60 до 70.
ping у вас достаточно нестабильный, даже в этом небольшом тесте есть ситуация, когда он превысил 2 мс. Вполне могут где-то теряться пакеты. Попробуйте сетевушку поменять на самую простую для начала.
Буду пробовать завтра с утра. На кроссе места нет, плюс хотел гигабит попробовать дать, но с этим пока тоже проблема. Завтра буду пробовать переключить сетевые (их у сервера 4), посмотрю скорость и пинг в каждой.
Прикрепленные файлы:

(43) Тюнинг сетки тоже уже завтра, но если честно не совсем понимаю зачем это? Если только в рамках "танцев с бубном" ибо уже не знаю что сможет помочь. То есть у Windows с сетью все обстоит лучше чем у Linux, раз возможна такая тонкая доводка сети для ускорения "сетевого стека"? Сравниваю с виндовым быстродействием до перехода на Linux...
(45)
(44)
Ну тут странная фигня. Нужно смотреть, что в запросах, на которых все тормозит. Вы же читаете данные, а не пишите. Ну ключевые операции - там минимальное время должно на запись уходить. В общем смотрите, что в запросе по новостям и что за запрос в модуле кадрового учета. Что они там конкретно делают? Также поглядите, что там в логах постгреса.
То есть у Windows с сетью все обстоит лучше чем у Linux, раз возможна такая тонкая доводка сети для ускорения "сетевого стека"? Сравниваю с виндовым быстродействием до перехода на Linux...
У винды просто нет возможности большую часть этого тюнинга сети сделать. У Линуха обычно нет проблем с сетью (иначе как вообще работают 99% облачных сервисов?), но при этом есть множество возможностей проверить, что там и как и множество возможностей улучшить (например, перекинув обслугу сетевух на отдельные ядра, а постгрес и 1С - на другие ядра, это может неплохо так сократить время ответа). У Вас конкретно может быть проблема в дровах, например, в аппаратной части, в кабеле, в свиче, ... В миллионе мест, поэтому поменять сетевой адаптер, переткнуть его в другой свич/порт свича, поменять кабель - это очень простые процедуры, которые иногда могут помочь. Тем более Вы жалуетесь на то, что pgAdmin теряет сервер периодически, значит что-то в королевстве датском действительно не так...
(44)
Это просто запуск конфигурации (2 минуты) и открытие карточки сотрудника (2,5 минуты). Причем первый раз когда открывал окно замера производительности там было что-то по поводу загрузки новостей и это все было по времени от 60 до 70.
Ну тут странная фигня. Нужно смотреть, что в запросах, на которых все тормозит. Вы же читаете данные, а не пишите. Ну ключевые операции - там минимальное время должно на запись уходить. В общем смотрите, что в запросе по новостям и что за запрос в модуле кадрового учета. Что они там конкретно делают? Также поглядите, что там в логах постгреса.
(49)
Не, я-то давно знаю, что "Линукс бесплатен!" - это сказочка для скупых, но всегда приятно услышать опровержение мифа от одного из его жрецов.
P.S. Кстати, о жрецах. Есть мнение, что слова "жрец" и "жрать" - однокоренные: жрец - тот, кто жрет. :-)
У нас все работает
Угу, а что будет с конторой после увольнения работника - это ее проблемы.
у кого-то денег нет на экспертизу
Ахха, сначала - на экспертизу, потом - на решение проблемы, потом - на тюнинг, на поддержку... что там еще?
Не, я-то давно знаю, что "Линукс бесплатен!" - это сказочка для скупых, но всегда приятно услышать опровержение мифа от одного из его жрецов.
им лучше сидеть дома на MS
Разумеется, лучше - один раз заплатить MS и все будет работать "искаропки", а не искать "специалиста" и платить ему, потом - второму... третьему... и так далее, все больше и больше, пока не наступит просветление.
P.S. Кстати, о жрецах. Есть мнение, что слова "жрец" и "жрать" - однокоренные: жрец - тот, кто жрет. :-)
(50) да, мы уже поняли, что Вам в детстве утюг с Линухом упал на ногу.
Я 3 года назад людям поставил сервер с Линухом - за эти три года я ничего в части администрирования не делал, т.к. все в автомате работает (бэкапы и прочее). Да, пару раз им базу закатил из бэкапа, т.к. кто-то что-то удалил/загрузил. Т.е. есть контора, в которой стоит сервак с Линухом, у которой нет админа, у которой 3 года все работает без админа, т.к. все настроено как надо один раз.
Я 3 года назад людям поставил сервер с Линухом - за эти три года я ничего в части администрирования не делал, т.к. все в автомате работает (бэкапы и прочее). Да, пару раз им базу закатил из бэкапа, т.к. кто-то что-то удалил/загрузил. Т.е. есть контора, в которой стоит сервак с Линухом, у которой нет админа, у которой 3 года все работает без админа, т.к. все настроено как надо один раз.
(59)
Да и кто первым заговорил про утюг?
Вы же при этом абсолютно уверены, что всем, кроме Вас, на голову упал утюг
Вы - это "все"? Извините, Луи-Дьедонне, не признал вас в гриме...
Да и кто первым заговорил про утюг?
говорите об этом постоянно, пальцем кажете...
См. (48) - на кого я указал пальцем? Может, это вы (причем, только вы!) реагируете на всякий палец, как на средний, показанный вам персонально?
И как тут диагноз не поставить? Даже если не просят - он сам напрашивается.
Типичная проблема пациента ПНД - то, что он ставит собственный диагноз всем окружающим, которые ему чем-то не угодили
(60)
Типичная проблема пациента ПНД
Ну Вы про диагноз заговорили первым, ибо "трудный случай" - это, как я понял, для Вас именно он. У кого чего болит, тот о том и говорит - народная мудрость. А случай может быть трудным в принципе и без ПНД, но у Вас, как я понял, на нем все завязано.
Мне на самом деле очень жаль потраченного времени, моего и вашего. Столько усилий было, за тот месяц, что копался с сервером на Linux узнал больше чем за всю жизнь с Windows. А теперь вот так. Тем более что в сложившихся обстоятельствах сервер теперь никто не даст, и отработать связку из темы я не смогу. Во всяком случае на этой работе...
(51)
может уже поздно,
а кто прописывал айпи адреса и настройка сетевой инфраструктуры... как происходила ?
слон же может и оставаться. позже попробуете.
или будет виртуализация и винда...
ping -t 10.4.7.39
ping: invalid argument: '10.4.7.39'
root@verona:~# ping 10.4.7.39
PING 10.4.7.39 (10.4.7.39) 56(84) bytes of data.
64 bytes from 10.4.7.39: icmp_seq=1 ttl=63 time=0.396 ms
64 bytes from 10.4.7.39: icmp_seq=2 ttl=63 time=2.05 ms
64 bytes from 10.4.7.39: icmp_seq=3 ttl=63 time=16.0 ms
интересно.
выше видел, что у вас ipv6 задействован. может здесь причина ?
может уже поздно,
а кто прописывал айпи адреса и настройка сетевой инфраструктуры... как происходила ?
слон же может и оставаться. позже попробуете.
или будет виртуализация и винда...
ping -t 10.4.7.39
ping: invalid argument: '10.4.7.39'
root@verona:~# ping 10.4.7.39
PING 10.4.7.39 (10.4.7.39) 56(84) bytes of data.
64 bytes from 10.4.7.39: icmp_seq=1 ttl=63 time=0.396 ms
64 bytes from 10.4.7.39: icmp_seq=2 ttl=63 time=2.05 ms
64 bytes from 10.4.7.39: icmp_seq=3 ttl=63 time=16.0 ms
интересно.
выше видел, что у вас ipv6 задействован. может здесь причина ?
synchronous_commit = on и full_page_writes = on для HDD - хоть SAS, хоть SATA, даже если контроллер RAID с кэшем и батарейкой, могут ощутимо влиять в худшую сторону. Можно попробовать их выключить, заодно и fsync(для теста) и посмотреть что получится.
Ядра процессоров тоже желательно заставить работать в максимально возможном для них турбобусте.
Ядра процессоров тоже желательно заставить работать в максимально возможном для них турбобусте.
(63) Дело в том, что ранее на этом сервере была развернута Windows 2008 + MS SQL 2008 + Сервер 1С и ЗУП3 крутилась вполне нормально. Просто в рамках восстановления инфраструктуры думал построить сервер на связке из темы. Поэтому сильно удивился, когда не получилось из коробки.
(58) Все на новом сервере прописывал я. В последний день пробовал отключить ipv6 по инструкциям, но сходу не получилось (первый эффект - полное пропадание связи с сервером, второй эффект - netstat даже после нескольких перезагрузок упорно продолжал показывать задействование ipv6, хотя настройки приложений соответствующие были сделаны).
Посему и было принято решение "все взад", так как времени на подробное изучение вопроса мне никто не дал.
(58) Все на новом сервере прописывал я. В последний день пробовал отключить ipv6 по инструкциям, но сходу не получилось (первый эффект - полное пропадание связи с сервером, второй эффект - netstat даже после нескольких перезагрузок упорно продолжал показывать задействование ipv6, хотя настройки приложений соответствующие были сделаны).
Посему и было принято решение "все взад", так как времени на подробное изучение вопроса мне никто не дал.
(66)
ext4 noatime,nodiratime,nobarrier
поздно обратил внимание на файл fstab
на будущее обратите внимание со слоном.
при монтировании по умолчанию - тест показывает менее 10.
xeon 1225v2 16Gb ddr3
система дебиан на NVME
база на хдд 465Гб сата3 , подключена на скорости сата 2
если решитесь еще раз побороть слона - пишите здесь или в новой ветке.
там реально нужно в линуксе "фурычить" на среднем уровне понимания работы системы в целом.
ext4 noatime,nodiratime,nobarrier
поздно обратил внимание на файл fstab
на будущее обратите внимание со слоном.
при монтировании по умолчанию - тест показывает менее 10.
xeon 1225v2 16Gb ddr3
система дебиан на NVME
база на хдд 465Гб сата3 , подключена на скорости сата 2
если решитесь еще раз побороть слона - пишите здесь или в новой ветке.
там реально нужно в линуксе "фурычить" на среднем уровне понимания работы системы в целом.
Прикрепленные файлы:

Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот