
{kind=link}
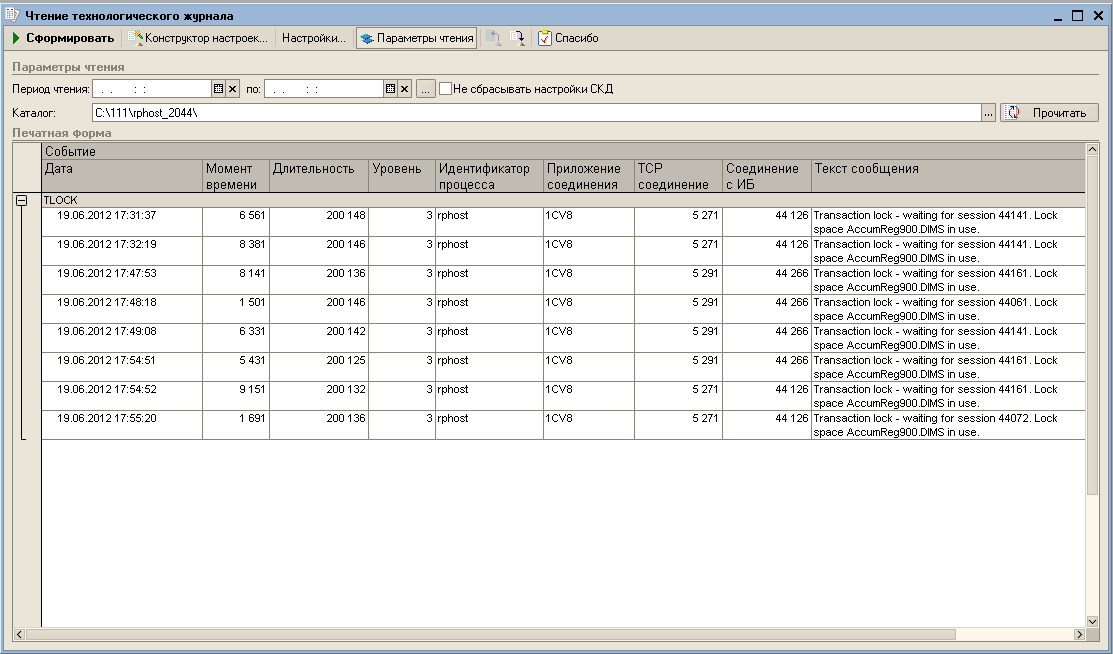
Так как парсеров логов технологического журнала найти не смог - пришлось писать обработку самому.
Для формирования отчета используется схема компоновки данных - соответственно настраивайте выходную форму как захочется.
Обновление 13.09.2012:
- Переделал код в одну строку. Прирост к скорости чтения до 30%.
Обновление 28.09.2012:
- Алгоритм обработки полностью переписан. Старая версия обработки оставлена на всякий пожарный.
- Значительно увеличена скорость чтения данных.
- Убран индикатор чтения строк. Вместо него добавлено количество обработанных файлов в статус формы.
- Убран заголовок отчета
- Зафиксированы максимальная высота и ширина ячеек.
- Расширен список считываемых событий.
- Период чтения данных расширен до секунд.
- Добавлен флаг "НеСбрасыватьНастройкиСКД". Если он установлен - при чтении файла не сбрасываются настройки компановки, установленные пользователем. При выключенном состоянии в отчет попадают только непустые события.
Обновление 13.09.2012:
- Удалил старую версию обработки (многие путались и скакачивали ее).
- Обновил скриншот.
- Для ленивых добавил версию под 8.2.