

















{kind=link}
Достаточно часто перед пользователями, ответственными за наполнение и ведение баз данных, а также перед программистом, делающим перенос данных, встаёт задача поиска расхождений. Делается сверка данных и обнаруживается разница в ключевых показателях - например, в остатках по регистрам, в сальдо, в оборотах за период. Саму разницу достаточно легко обнаружить, применяя богатый набор встроенных, а также и внешних, отчётов. Но вот сузить область поиска, найдя конкретное подмножество документов, или хотя бы малый период, когда имели место расхождения, труднее - это приходится делать вручную, изменяя настройки отчётов, в первую очередь сужая период. Подобный поиск трудозатратен и времяёмок.
Предлагаемая обработка примитивна: она исполняет два произвольных запроса, подготовленных программистом, начиная с большого периода, и постепенно сужая область поиска по шкале времени. Сужение в текущей версии производится только по границам периода - если нашли разницу в году, то ищем, например, месяц, а внутри месяца - декаду, неделю, день, час. Когда разница результатов запроса локализована с точностью до часа, выявить документы, приведшие к ней, проще. Хотя бы изучением записей соответствующего регистра за этот час.
Поскольку запросы могут иметь весьма сложную логику, в т.ч. опирающуюся на расчёт начальных и конечных остатков, кэширование не предусмотрено, и за каждый период в ходе их сужения запросы выполняются заново к базе. Теоретически, можно продумать кэширование на уровне временных таблиц, но это усложнит настройку обработки, а так по готовым запросам её может применить и пользователь.
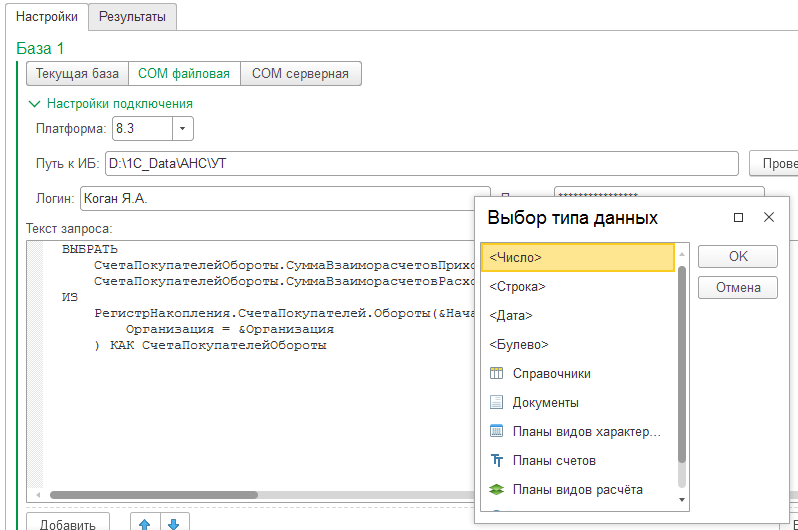
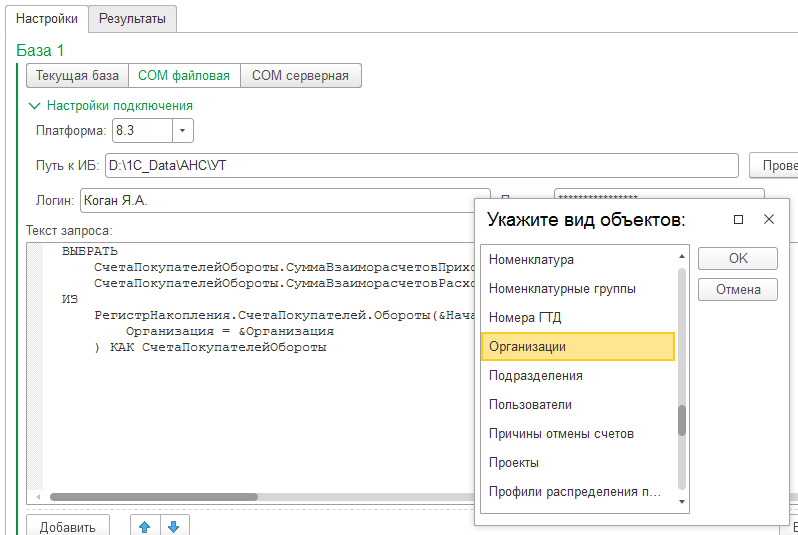
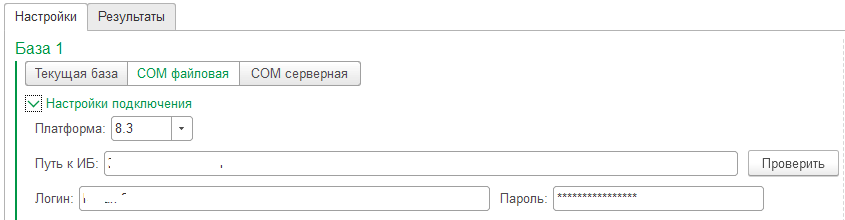
Сравнение может выполняться внутри одной базы (например, для поиска различий в оперативном и бухгалтерском учётах), между текущей базой и другой, или между двумя базами силами третьей базы. Обмен с другими базами реализован стандартным COM-обменом. К запросам могут быть переданы параметры; в случае COM-обмена ссылочные значения выбираются из простейших диалоговых окон (поддерживаются только стандартные реквизиты), или указываются GUID'ы этих значений.
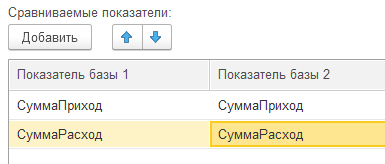
Для сравнения определяется ряд показателей, как итоговых значений запроса (обычно числовых, но можно и любые другие). Ссылочные значения принудительно приводятся к строковому виду методом String, поэтому желательно ещё в запросе разыменовывать их согласно логике задачи.
Результаты сравнения, если есть различия, выводятся в табличный документ; возможна настройка внешнего вида показа различий штатными средствами СКД.
Предусмотрено сохранение настроек между сеансами.
Обработка НЕ проверяет правильность имён параметров и сравниваемых полей, эта задача лежит на настройщике сравнения.
Тестировалось на 8.3.16.1224, но наверняка будет работать на более ранних релизах, начиная с 8.3.6.
С помощью этой нехитрой штуки я быстро отловил единственный непроведённый документ, на поиск которого через отчёты обеих систем иначе потратил бы больше сил и времени. Эффективно, когда разница лежит в последней секунде суток - обработка увидит её, а невнимательный после долгого поиска пользователь может и упустить.
Таких было множество, но - может, кому и пригодится.