приветствую!
После разделения одного tempdb на несколько файлов и перемещение их на другой диск, осталась проблема что размер первого больше всех, 10Гб. Было задано 8 по 1Гб. Показатели статов подтверждают что обращений максимально к нему. Файлы перемещены обычным ALT ER DATABASE tempdb.
В чем может быть проблема не равномерного использования? MS SQL 2014
После разделения одного tempdb на несколько файлов и перемещение их на другой диск, осталась проблема что размер первого больше всех, 10Гб. Было задано 8 по 1Гб. Показатели статов подтверждают что обращений максимально к нему. Файлы перемещены обычным ALT ER DATABASE tempdb.
В чем может быть проблема не равномерного использования? MS SQL 2014
Прикрепленные файлы:


Ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все

(6)
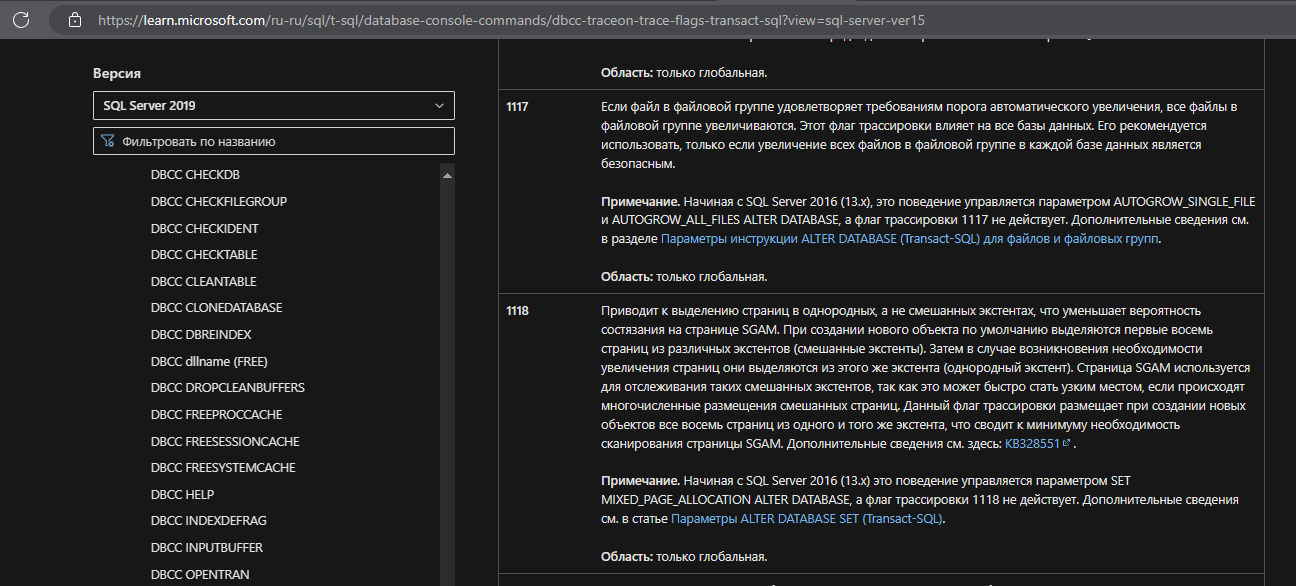
Судя по этому "Trace flag 1117 changes the behavior of file growth: if one data file in a filegroup grows, it forces other files in that filegroup to ALSO grow."
И этому "Not everyone likes to implement this trace flag, particularly because it impacts every database on the instance and not just tempdb"
"Поможет" он своеобразно - вырастут еще и остальные файлы.
Не понимаю в чем проблема - разного размера файлы в tempdb, скорее-всего (ну если не лезть совсем уж в крайности по размерам), не повлияют на производительность.
В чем тогда смысл?
А растет первый файл, например, если что-то "большое" делалось в единой транзакции, или началось несколько транзакций и MS SQL не "знал", что это "большие" транзакции и надо их разнести по своим файлам.
TraceFlag 1117
Судя по этому "Trace flag 1117 changes the behavior of file growth: if one data file in a filegroup grows, it forces other files in that filegroup to ALSO grow."
И этому "Not everyone likes to implement this trace flag, particularly because it impacts every database on the instance and not just tempdb"
"Поможет" он своеобразно - вырастут еще и остальные файлы.
Не понимаю в чем проблема - разного размера файлы в tempdb, скорее-всего (ну если не лезть совсем уж в крайности по размерам), не повлияют на производительность.
В чем тогда смысл?
А растет первый файл, например, если что-то "большое" делалось в единой транзакции, или началось несколько транзакций и MS SQL не "знал", что это "большие" транзакции и надо их разнести по своим файлам.
(9)
Это и нужно, чтоб файлы росли одновременно и всегда оставались одинакового размера
(9)
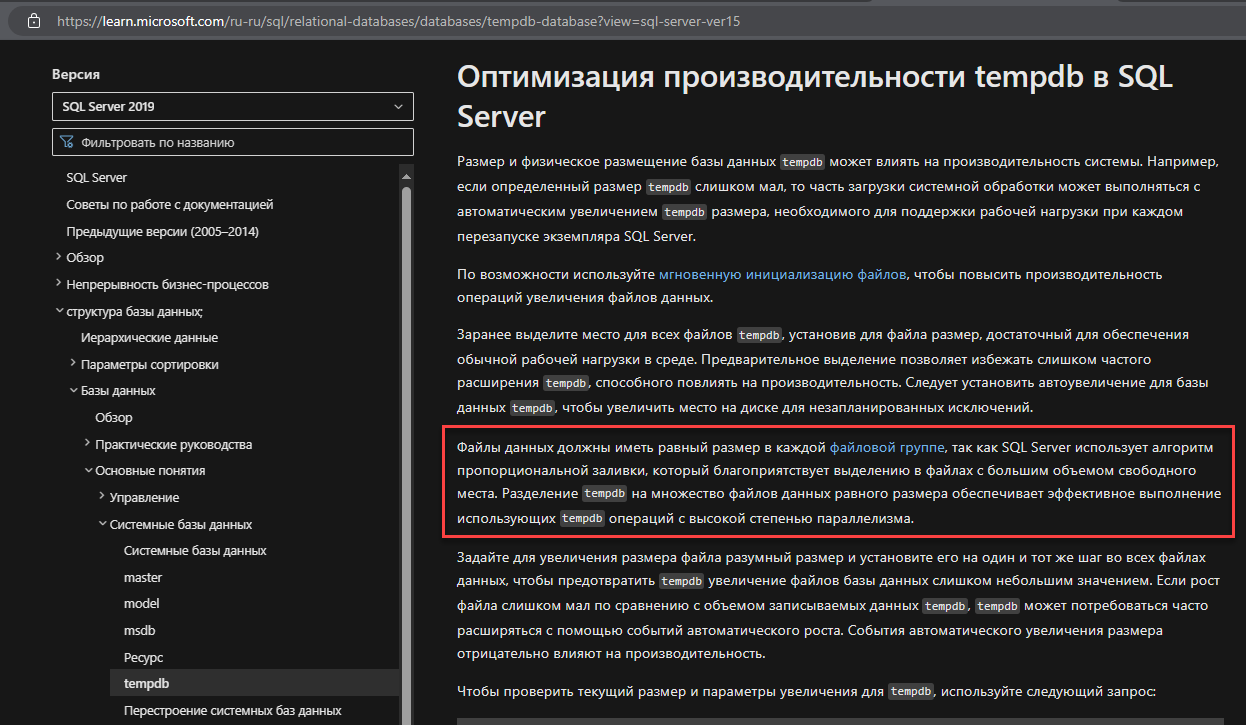
При создании временного объекта нужно аллоцировать под него страницы в tempdb, а при удалении - деаллоцировать. Делается это в служебных страницах, которые на время внесения изменения блокируются. При интенсивной работе с tempdb с какого-то момента к ним могут начать расти очереди. Но если добавить файлов в той же файловой группе, то на каждый файл будут свои служебные страницы.
Нюанс в том, что нагрузка между файлами распределятся не round-robin, а пропорционально их размеру, поэтому необходимо чтоб они были одинакового размера.
"Поможет" он своеобразно - вырастут еще и остальные файлы.
Это и нужно, чтоб файлы росли одновременно и всегда оставались одинакового размера
(9)
Не понимаю в чем проблема - разного размера файлы в tempdb, скорее-всего (ну если не лезть совсем уж в крайности по размерам), не повлияют на производительность.
В чем тогда смысл?
В чем тогда смысл?
При создании временного объекта нужно аллоцировать под него страницы в tempdb, а при удалении - деаллоцировать. Делается это в служебных страницах, которые на время внесения изменения блокируются. При интенсивной работе с tempdb с какого-то момента к ним могут начать расти очереди. Но если добавить файлов в той же файловой группе, то на каждый файл будут свои служебные страницы.
Нюанс в том, что нагрузка между файлами распределятся не round-robin, а пропорционально их размеру, поэтому необходимо чтоб они были одинакового размера.
(10)
Т.е. если вместо одного файла в 10гб и 2-х по 8 получить, все три по 10, да еще получить подобное не только для tempdb - будет хорошо?
"Нюанс в том, что нагрузка между файлами распределятся не round-robin, а пропорционально их размеру" - можно пруф?
Не понимаю логики, когда нагрузка ложиться на самый большой в файл, ибо единственный эффект, который мы получим - так это увеличение вероятностей тех самых блокировок.
Могу подозревать, что все же применяется Weighted Round Robin (ну, или, если не путаю Weighted Least Connections), в котором вес определяется свободными страницами в конкретном файле или числом открытых транзакций (возможно еще учитывается протекание процессов деаллокации), а не размером файла - тут могу только гадать.
Это и нужно, чтоб файлы росли одновременно и всегда оставались одинакового размера
Т.е. если вместо одного файла в 10гб и 2-х по 8 получить, все три по 10, да еще получить подобное не только для tempdb - будет хорошо?
... Но если добавить файлов в той же файловой группе...
- с этим никто не спорит.
"Нюанс в том, что нагрузка между файлами распределятся не round-robin, а пропорционально их размеру" - можно пруф?
Не понимаю логики, когда нагрузка ложиться на самый большой в файл, ибо единственный эффект, который мы получим - так это увеличение вероятностей тех самых блокировок.
Могу подозревать, что все же применяется Weighted Round Robin (ну, или, если не путаю Weighted Least Connections), в котором вес определяется свободными страницами в конкретном файле или числом открытых транзакций (возможно еще учитывается протекание процессов деаллокации), а не размером файла - тут могу только гадать.
(11)
Ну, что поделать, серебряной пули нет, чем-то надо жертвовать. Размениваем дисковое пространство на уменьшение ожидания. Плюс этот флаг меняет поведение приращения в пределах одной файловой группы, а на пользовательских базах новые файлы обычно создают в разных. Так же напомню, что с 2016-й версии он включен по умолчанию и вроде никто особо не жаловался
(11)
Proportional fill algorithm, и, строго говоря, да, там на основе количества свободных страниц. Но, по большому счёту, суть-то та же. При старте инстанса файлы пусты, вопрос в размерах. Или при приросте одного файла из группы - скорее всего и свободных страниц в нём будет больше (ну, тут и от настроек прироста зависит, конечно)
Т.е. если вместо одного файла в 10гб и 2-х по 8 получить, все три по 10, да еще получить подобное не только для tempdb - будет хорошо?
Ну, что поделать, серебряной пули нет, чем-то надо жертвовать. Размениваем дисковое пространство на уменьшение ожидания. Плюс этот флаг меняет поведение приращения в пределах одной файловой группы, а на пользовательских базах новые файлы обычно создают в разных. Так же напомню, что с 2016-й версии он включен по умолчанию и вроде никто особо не жаловался
(11)
Могу подозревать, что все же применяется Weighted Round Robin (ну, или, если не путаю Weighted Least Connections), в котором вес определяется свободными страницами в конкретном файле или числом открытых транзакций (возможно еще учитывается протекание процессов деаллокации), а не размером файла - тут могу только гадать.
Proportional fill algorithm, и, строго говоря, да, там на основе количества свободных страниц. Но, по большому счёту, суть-то та же. При старте инстанса файлы пусты, вопрос в размерах. Или при приросте одного файла из группы - скорее всего и свободных страниц в нём будет больше (ну, тут и от настроек прироста зависит, конечно)
(11)
Да, правильно "свободным местом", Д. Короткевич в каком-то вебинаре рассказывал.
У 2019 эта проблема решена, запись идёт "как бы равномерно по всем файлам" (во всяком случае синтетические тесты это показывают)
Могу подозревать, что все же применяется Weighted Round Robin (ну, или, если не путаю Weighted Least Connections), в котором вес определяется свободными страницами в конкретном файле или числом открытых транзакций (возможно еще учитывается протекание процессов деаллокации), а не размером файла - тут могу только гадать.
Да, правильно "свободным местом", Д. Короткевич в каком-то вебинаре рассказывал.
У 2019 эта проблема решена, запись идёт "как бы равномерно по всем файлам" (во всяком случае синтетические тесты это показывают)
(13)
Подозреваю, что и в этом случае данные единой транзакции не разносятся по нескольким файлам и если место в файле, куда начали писать исчерпано, все равно получим прирост на n блоков и разный размер.
Но проверять желания нет, не думаю, что это значимо сказывается на производительности.
В крайнем случае никто не запрещает в "ненагруженное время" DBCC SHRINKDATABASE (tempdb, '<target_percent>');
У 2019 эта проблема решена, запись идёт "как бы равномерно по всем файлам"
Подозреваю, что и в этом случае данные единой транзакции не разносятся по нескольким файлам и если место в файле, куда начали писать исчерпано, все равно получим прирост на n блоков и разный размер.
Но проверять желания нет, не думаю, что это значимо сказывается на производительности.
В крайнем случае никто не запрещает в "ненагруженное время" DBCC SHRINKDATABASE (tempdb, '<target_percent>');
(14)
Зависит от нагрузки. Я раз пять наблюдал вживую tempdb contention, не больше. В основном это были очень нагруженные сервера с количеством баз за сотню и выравнивание файлов помогало всегда. Подозреваю, что на среднестатистической 1с-ной инсталляции такое словить сложнее, но если есть возможность заранее сделать нормальные настройки согласно рекомендациям - почему бы и нет? Даже если не пригодится, всё лучше, чем траблшутить внезапные тормоза на ровном месте
Но проверять желания нет, не думаю, что это значимо сказывается на производительности.
Зависит от нагрузки. Я раз пять наблюдал вживую tempdb contention, не больше. В основном это были очень нагруженные сервера с количеством баз за сотню и выравнивание файлов помогало всегда. Подозреваю, что на среднестатистической 1с-ной инсталляции такое словить сложнее, но если есть возможность заранее сделать нормальные настройки согласно рекомендациям - почему бы и нет? Даже если не пригодится, всё лучше, чем траблшутить внезапные тормоза на ровном месте
(15)
Мы же не про необходимость разнесения по нескольким файлам, а про необходимость выравнивания их размера?
Пусть первоначальный размер файла в файловой группе 10Гб, с запасом,и есть 3-и файла по 10Гб.
Потом что-то разово пошло не так и первый файл вырос до 20Гб, было бы очень странно в подарок получить "лишние" 20Гб за счет 2-х оставшихся файлов.
С этим надо как-то разбираться, а не разрешать расти базе на пустом месте.
tempdb это не про in-memory, поэтому можем получить тормоза связанные с работой с бОльшими файлами или даже out of disk space, вместо tempdb contention.
Впрочем, не буду спорить, моих познаний во внутренних механизмах MS SQL явно не достаточно.
Просто, с точки зрения программирования, не понимаю, почему то, что может решаться небольшой оптимизацией алгоритмов выделения свободных страниц, надо решать методом топора.
tempdb contention
Мы же не про необходимость разнесения по нескольким файлам, а про необходимость выравнивания их размера?
Пусть первоначальный размер файла в файловой группе 10Гб, с запасом,и есть 3-и файла по 10Гб.
Потом что-то разово пошло не так и первый файл вырос до 20Гб, было бы очень странно в подарок получить "лишние" 20Гб за счет 2-х оставшихся файлов.
С этим надо как-то разбираться, а не разрешать расти базе на пустом месте.
tempdb это не про in-memory, поэтому можем получить тормоза связанные с работой с бОльшими файлами или даже out of disk space, вместо tempdb contention.
Впрочем, не буду спорить, моих познаний во внутренних механизмах MS SQL явно не достаточно.
Просто, с точки зрения программирования, не понимаю, почему то, что может решаться небольшой оптимизацией алгоритмов выделения свободных страниц, надо решать методом топора.
(14)
MSSQL 2019 нет, на
Имеем картину одновременного равномерного увеличения файлов tempDB в одной транзакции
Код
результат
Подозреваю, что и в этом случае данные единой транзакции не разносятся по нескольким файлам и если место в файле, куда начали писать исчерпано, все равно получим прирост на n блоков и разный размер.
MSSQL 2019 нет, на
sel ect @@version
Microsoft SQL Server 2022
Имеем картину одновременного равномерного увеличения файлов tempDB в одной транзакции
Код
use tempDB
CRE ATE TABLE [dbo].[t](
[ID] [INT] identity primary key NOT NULL,
[f1] [char](4000) NOT NULL
)
GO
ins ert into dbo.t (f1)
sele ct top (100000) b.[name] fr om master.dbo.spt_values a cross join master.dbo.spt_values b where a.type = 'P' Показатьрезультат
Прикрепленные файлы:



все 8 гигов кончились, нужно было расти, стоит авто увеличение на первом, вот он и начал увеличиваться, а так как максимального размера нет, то и растет.
И вообще зачем темпдб разбивать, сейчас же все на ссд, а это ему не нужно
И вообще зачем темпдб разбивать, сейчас же все на ссд, а это ему не нужно


(4)
Это не про скорость дисков история, это про конкурентный доступ к служебным страницам (GAM, SGAM), они всё равно в памяти лежат. Больше файлов - больше служебных страниц, меньше борьбы за них.
И вообще зачем темпдб разбивать, сейчас же все на ссд, а это ему не нужно
Это не про скорость дисков история, это про конкурентный доступ к служебным страницам (GAM, SGAM), они всё равно в памяти лежат. Больше файлов - больше служебных страниц, меньше борьбы за них.
Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот