

{kind=link}
Коллеги, во первых, всех с Наступающим Новым Годом! Желаю всем успехов и побольше хорошего настроения в новом году.
Тема многопоточности часто возникает на крупных предприятиях во время выполнения различных регламентных процедур. Например закрытие месяца или перенос данных из одной базы в другую. Бывают даже случаи, когда механизм обмена данными выполняясь в фоновом режиме постоянно в реальном времени, не успевает перенести все создаваемые объекты.
Это может стать серьезной проблемой. Увеличивать мощность сервера до бесконечности не всегда правильный вариант. Более правильно распараллелить процессы выгрузки и загрузки данных и выполнять их одновременно.
Ситуация усугубляется тем, что существующий обмен в современных типовых конфигурациях через универсальный формат работает, откровенно говоря, значительно медленнее старого доброго обмена данными в формате XML по правилам конвертации 2.0.
Многопоточный обмен данными
Казалось бы, все достаточно просто. Создаем потоки, делим данные на порции и выполняем обмен. Но не тут-то было. Подсистема БСП по обмену данными преподносит ряд очень неприятных сюрпризов, обойти которые иногда достаточно сложно.
В данной статье я хочу описать реализацию многопоточного обмена данными между типовыми конфигурациями ЕРП 2.4 и БП 3.0. Все «грабли» и неприятности с которыми пришлось столкнуться, а также способы их устранения.
Спасибо сотрудникам компании 2iS и их продукту 2iS:Интеграция 2.0, который является основным звеном разработки.
Отдельное спасибо сотрудникам компании РЕМИ в лице Дмитрия Кирилкина за помощь в тестировании и поиску «узких мест» механизма.
Я здесь не буду рассматривать подробно продукт 2iS:Интеграция. Продукт уже достаточно давно на рынке, имеет много документации, и тем кому интересно, тот может самостоятельно его изучить. Если кратко, 2iS:Интеграция позволяет выполнять различные встроенные в нее обработки во внешних информационных базах. Это может быть запуск механизмов обмена, формирование отчетов, обработка документов и выполнение любых необходимых операций. Подключение к информационным базам выполняется через COM. Это не единственный способ подключения, но он является основным.
Уже чувствую гневные возгласы на счет целесообразности использования COM и DCOM в эпоху HTTP и WEB сервисов, ODada и JSON. Скажу сразу, я с этим согласен с некоторыми оговорками. Но, в данной статье я не буду касаться этого вопроса, и приму его как данность. Тем, кому интересно узнать плюсы и минусы реализации взаимодействия через COM в 2iS:Интеграции, смотрите в этой статье.
В 2iS:Интеграции реализовано много полезных сервисов, таких как сохранение контекста подключения между сеансами обмена, обработка различных исключительных ситуаций, обратная связь для передачи информации о ходе выполнения и прочее.
Отдельно стоит отметить механизм разбиения данных на порции и выполнение обменов данными в многопоточном режиме. Многопоточный обмен через 2iS:Интеграцию уже успешно зарекомендовал себя в связке с правилами конвертации КД2 для выполнения обменов между распределенными базами (РИБ) и базами с отличающимися конфигурациями.
Связка же механизма многопоточности с обменом через универсальный формат выполнялась впервые. Ниже я расскажу об особенностях и нюансах.
Архитектурные особенности
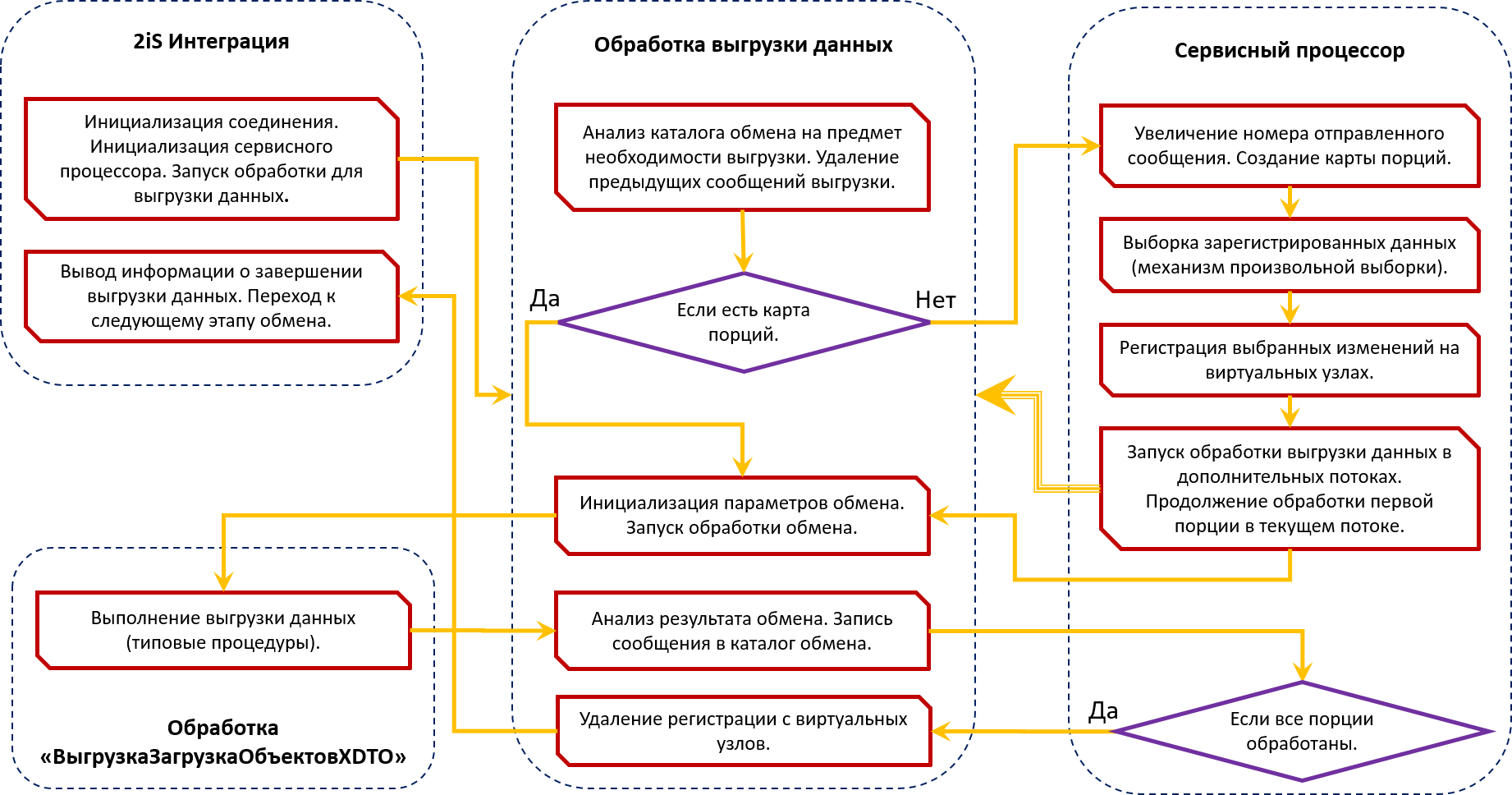
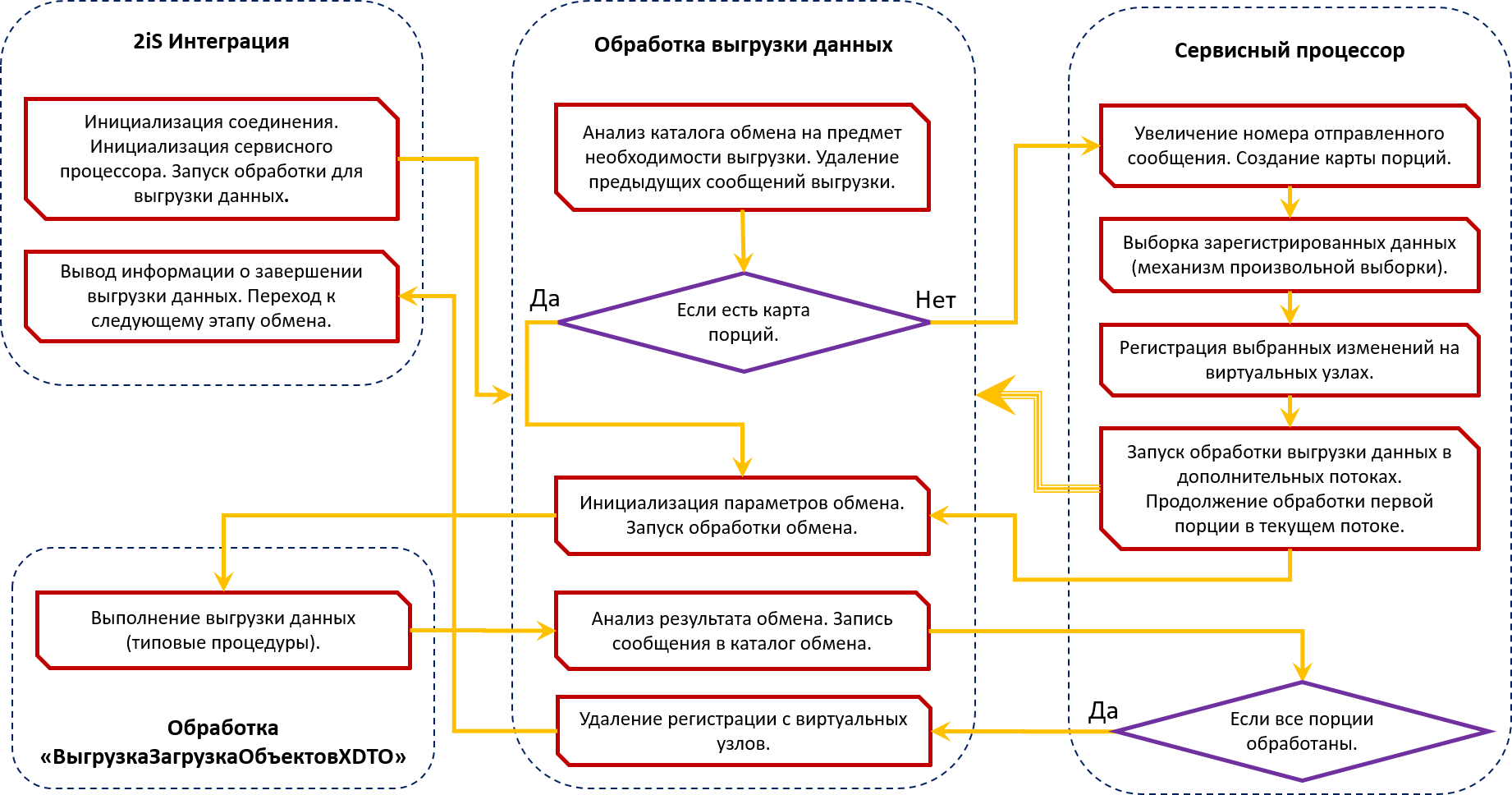
Общая схема процесса выгрузки данных
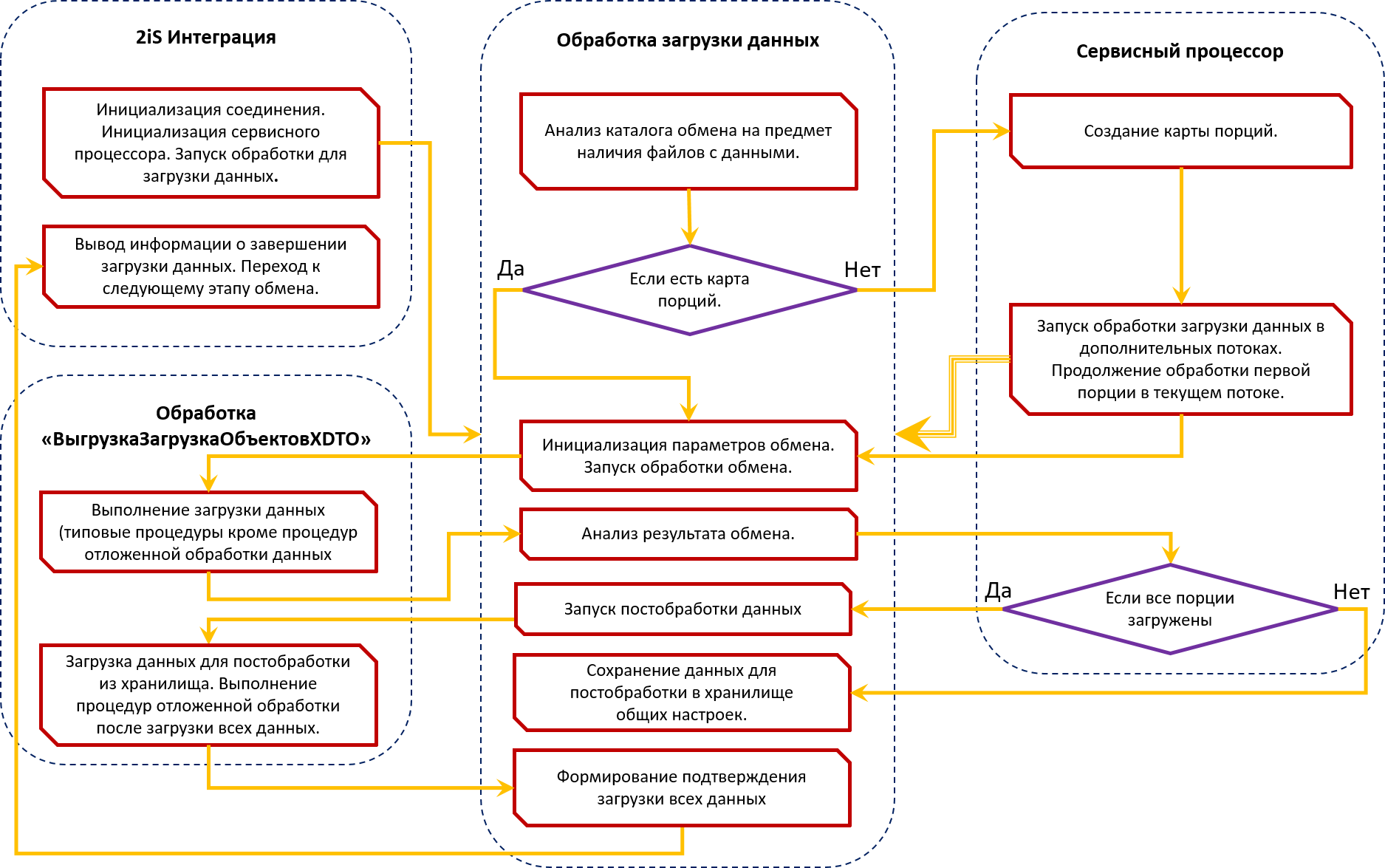
Общая схема процесса загрузки данных
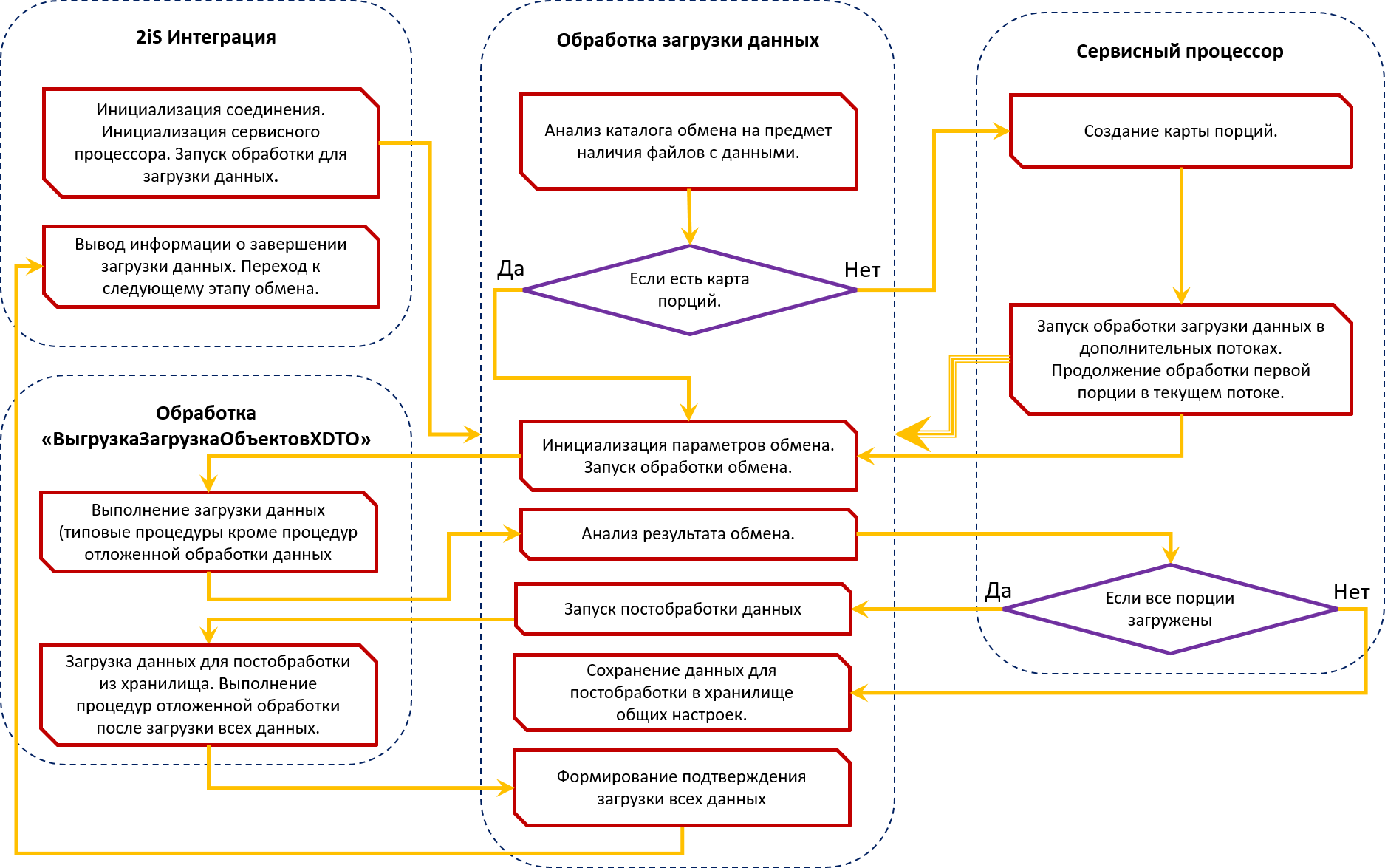
Основной и базовый механизм программного продукта 2iS:Интеграции, который выполняет все сервисные функции, такие как запуск обработок обмена, разбиение данных на порции, запуск и отслеживание выполнения в отдельных потоках, вывод информации о прогрессе выполнения - называется Сервисный процессор.
Я не буду останавливаться подробно на описании его функционала, так как это не является темой данной статьи. Отмечу только, некоторые полезные особенности, которые можно использовать для обмена данными.
Произвольный алгоритм выборки данных
Первая такая особенность предоставляет возможность использовать произвольный алгоритм для выборки данных и отнесения их к той или иной порции. Это очень полезно, если данные требуется выгружать в определенной последовательности или порциями определенного размера. Также есть возможность распределить документы разных организаций в разные порции. Как вы увидите дальше, это крайне необходимая вещь для выполнения обмена данными по правилам КД3.
Мы реализовали следующий алгоритм выборки данных:
- Объекты не являющиеся документами (элементы справочников, планов видов характеристик) – выгружаются всегда первыми и в полном объеме. Это необходимо для корректной загрузки и проведения документов.
- Данные, которые были выгружены ранее, и по ним не получено подтверждение загрузки – необходимо выгружать эти данные первыми, чтобы они не были потеряны в результате обмена. Потеря данных может произойти в случае, если будут выгружены другие данные и получено подтверждение по ним с более большим номером отправленного сообщения.
- Остальные объекты (документы) - в объеме не превышающем максимальный объем выгружаемых объектов.
Распределение данных по порциям
Сам механизм распределения по порциям происходит следующим образом:
- Считываются зарегистрированные данные. Все, или отобранные согласно алгоритму выборки.
- После этого выбранные данные регистрируются повторно на виртуальных узлах плана обмена. Фактически этих узлов не существует в информационной базе. В файлах обмена данными присутствует информация только об основном узле. Соответственно номер отправленного сообщения везде идентичный.
- После успешного выполнения всех потоков обработки данных регистрация на виртуальных узлах удаляется.
Такой алгоритм имеет дополнительные временные затраты на регистрацию объектов, но его использование позволяет обеспечить целостность данных в случае сбоев при выполнении одного из потоков.
Процесс выгрузки и загрузки данных
После распределения данных по порциям, сервисный процессор запускает обработку, выполняющую сам обмен данными. На самом деле есть еще промежуточные обработки, но для упрощения понимания процесса их можно пропустить.
За прототип обработки, которая выполняет сам обмен данными (выгрузку и загрузку) нами была взята типовая обработка «ВыгрузкаЗагрузкаОбъектовXDTO», которая есть во всех типовых конфигурациях.
Дальше есть два подхода к реализации:
- Перенести в обработку все механизмы БСП необходимые для обмена данными – в этом случае, мы не будем зависеть от изменений в типовых конфигурациях. Но значимые изменения, допустим поддержку нового универсального формата, придется переносить вручную.
- По возможности использовать процедуры обмена данными из общих модулей БСП – в этом случае, при обновлении типовых механизмов, нужно будет только проверить их совместимость с тем, что есть в обработке. Однако в данном случае придется вносить некоторые, хоть и минимальные изменения в типовых модулях БПС.
Нами был выбран второй вариант. При необходимости можно реализовать и первый, достаточно быстро.
В обоих вариантах можно использовать типовой модуль менеджера обмена через универсальный формат (в котором содержатся правила конвертации) или использовать модуль внешней обработки, которая должна быть загружена в 2iS:Интеграцию.
Сам универсальный формат, на данный момент, можно использовать только встроенный в информационную базу.
Основные проблемы реализации многопоточности
К большому сожалению, разработчики типового обмена данными, сделали его достаточно сложным. В типовых правилах очень активно используется создание виртуальных объектов при выгрузке, создание объектов «на лету» при загрузке, сохранение большого числа коллекций с объектами и их последующая обработка. По всей видимости они не задумывались над возможным использованием этого механизма в многопоточном режиме, а очень зря.
Ниже я приведу основные сложности, с которыми мы столкнулись, и варианты их устранения.
Выгрузка дополнительных «виртуальных» объектов
Достаточно часто в типовых правилах конвертации, построенных на КД3, при выгрузке данных создаются виртуальные элементы справочников. Это те элементы которые должны быть в базе получателя и которых нет в базе отправителя. Примером такого поведения может быть выгрузка из конфигурации ERP документа «Приобретение товаров и услуг». В файл обмена могут быть выгружены виртуальные договоры если в ERP поступление оформлено без указания договора (такое возможно в зависимости от настроек).
На этапе загрузки данных, система будет пытаться найти такие договоры в базе Приемнике по полям поиска. Если данные найдены, то они обновляются. Если не найдены – создаются новые элементы. При одновременной загрузке данных в разных потоках, могут возникнуть следующие проблемы:
- Возможное дублирование при создании новых элементов справочника, так как при поиске по полям поиска два потока могут начать поиск до записи нового элемента. Это приведет к записи одного и того же элемента дважды.
- Если элемент справочника будет найден по полям поиска одновременно в двух потоках то один из них не сможет его записать, так как после получения объекта он будет уже изменен и записан другим потоком (сработает оптимистическая блокировка).
Аналогичные проблемы могут возникнуть в случае, если в правилах конвертации на этапе загрузки данных предусмотрено создание новых объектов «на лету». Что тоже может встречаться в правилах конвертации.
Частично эта проблема решается путем распределения в разные потоки максимально не связанных между собой данных. Например документы по разным организациям можно помещать в разные порции. Если таким образом не получается решить проблему, остается корректировать правила конвертации, и устранять такое поведение.
Отложенная обработка объектов
Под отложенной обработкой я здесь понимаю сразу несколько операций, которые выполняются после загрузки всех данных. Подробнее читайте об этом в статье ED - процесс загрузки данных.
Перечислю коротко эти процедуры в порядке их выполнения:
- Пометка на удаление объектов – помечаются на удаление все объекты по которым получен признак удаления и не получена загрузка полного объекта,
- Удаление временных объектов, созданных по ссылкам – удаление объектов, которые были созданы или найдены по полям поиска, и не были загружены полностью,
- Отложенное заполнение объектов – выполнение алгоритмов отложенного заполнения объектов, которые могут быть указаны в правилах для каждого вида объектов,
- Обработка события «После конвертации» - выполнение произвольных операций после загрузки всех данных,
- Отложенное проведение документов – выполнение проведения загруженных документов,
- Отложенная запись объектов – выполнение записи загруженных объектов (не документов) с выполнением всех платформенных проверок и обработчиков.
Дело в том, что для корректного выполнения многих из этих процедур необходимо это делать после загрузки всех данных во всех порциях. Более того, выполнять эти процедуры необходимо единовременно имея все необходимые данные по загруженным объектам.
Приведу несколько примеров:
- Очень часто перед отложенным заполнением объектов выполняется сортировка всех загруженных объектов по определенному принципу. Соответственно, должен быть список всех загруженных объектов.
- При пометке на удаление объектов, или при удалении временных объектов созданных по ссылкам, они могут быть загружены полностью в других потоках.
- В алгоритме «После конвертации» есть процедуры такого вида «АктуализироватьПодчиненностьСчетовФактурВыданных». Выполнение этих процедур зависит от связных объектов, которые могут загружаться в других потоках.
Мы решили эту проблему следующим образом:
После окончания загрузки очередной порции данных, все необходимые нам коллекции из структуры «КомпонентыОбмена» помещаются в хранилище общих настроек. Соответственно, после обработки всех порций, все сохраненные данные считываются из настроек и формируется результирующая структура «КомпонентыОбмена». После чего выполняются все описанные выше операции.
КомпонентыОбмена – это структура, в которую помещаются все данные, необходимые для выполнения обмена. Структура доступна во всех алгоритмах обмена данными. Более подробно читайте в статьях:
Данный подход в целом корректен, но имеет один существенный недостаток. Дело в том, что таблица «ЗагруженныеОбъекты» структуры «КомпонентыОбмена» содержит в себе элементы типа «Объект». Элементы таких типов нельзя сохранить в хранилище общих настроек. Мы были вынуждены очищать поля с типом «Объект» и формировать потом объекты заново.
Проблема оказалась в том, что в некоторых случаях объекты могут содержать дополнительные свойства, которые теряются при повторном создании. Это неприятный момент, решить который можно лишь корректировкой правил конвертации и исключая подобные ситуации.
Резюме
Как видите, не все удалось решить доработкой самого механизма обмена данными. В ряде случаев необходимо корректировать сами правила конвертации, и это не очень хорошо.
Исходя из всего вышеописанного, можно сделать следующий вывод:
У нас есть рабочий функционал для выполнения обмена данными через универсальный формат в режиме многопоточности между современными типовыми конфигурациями. Но сделать это «из коробки» не получится. В любом случае потребуется дополнительная доработка правил конвертации. Насколько серьезная, это уже зависит от специфики конкретной компании.
Есть ли альтернатива?
Альтернативой описанному выше механизму может быть оптимизация типовых механизмов обмена данными и увеличение скорости работы обмена данными в однопоточном режиме. С учетом всех описанных выше сложностей, для кого-то это может быть более предпочтительным вариантом.
Варианты оптимизации, которые можно использовать:
- Кэширование данных из регистра сведений «Публичные идентификаторы синхронизируемых объектов».
- Отделение процесса отложенного проведения документов от основного процесса загрузки данных и выполнение его в отдельном потоке.
Коллеги, если у кого-то был опыт запуска обмена данными через ED в режиме многопоточности, или опыт по серьезной оптимизации алгоритмов типового обмена, пишите в комментариях, очень интересно.
Спасибо за внимание. Если информация, приведенная в статье оказалась полезной или натолкнула кого-то на интересные мысли, очень буду рад!
Другие статьи по механизмам обмена данными через универсальный формат: