
Фирма «1С» приглашает пользователей 1cfresh.com участвовать в пилотном проекте по тестированию сервиса распознавания сканов и фотографий документов из «1С:Бухгалтерии».
Что известно о новом сервисе
На данный момент работа с сервисом «Распознавание Документов» анонсирована для облачной «1С:Бухгалтерии», опубликованной в сервисе 1С:Фреш. В каталоге решений на начальной странице приложения будет доступна установка расширения «Библиотека распознавания для Бухгалтерии Предприятия, редакция 1.1».
Предполагается, что пользователи сервиса смогут оцифровывать бумажные документы, чтобы вводить их данные в программу с минимальными трудозатратами, просто загружая комплект сканов или фотографий документов в сервис.
Сервис «Распознавание Документов» позволит:
- распознавать и готовить к вводу типовые счета-фактуры, УПД, Торг-12, акты и счета на оплату, а также некоторые нетиповые виды актов и счетов;
- контролировать повторную загрузку ранее отсканированного документа;
- наглядно проверить каждую деталь без необходимости держать перед собой бумажный оригинал;
- проверять корректность заполнения сумм документа.
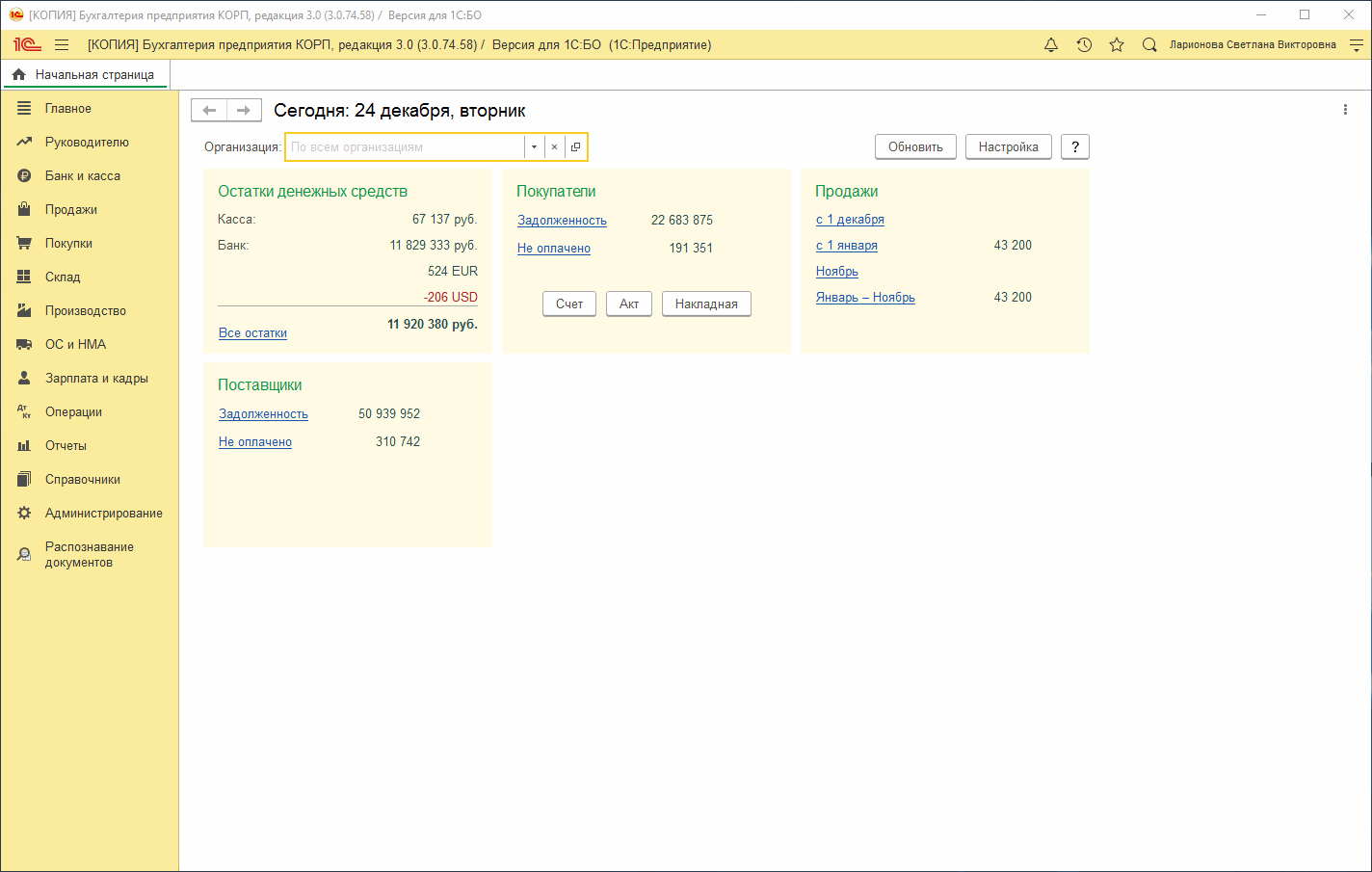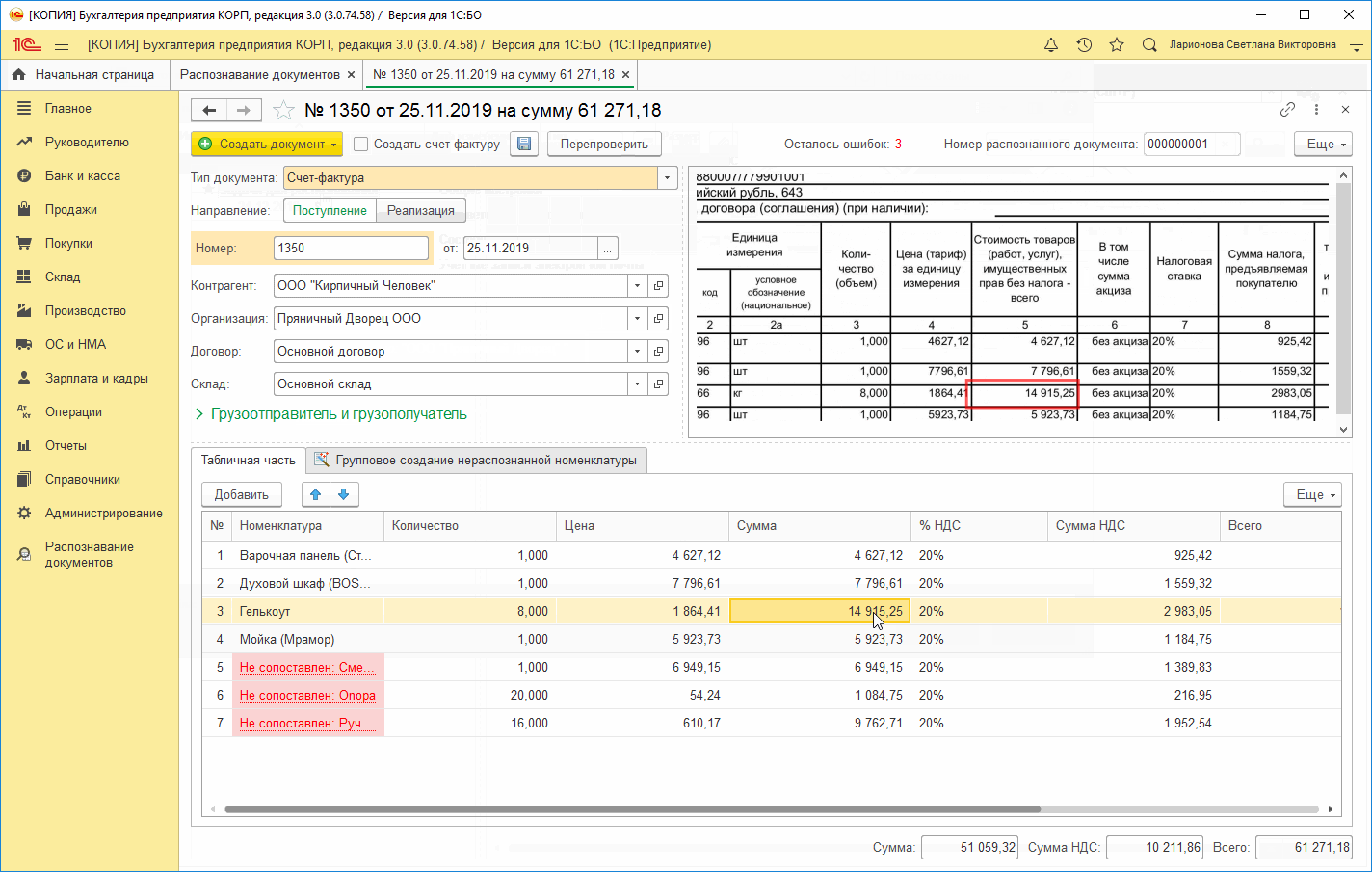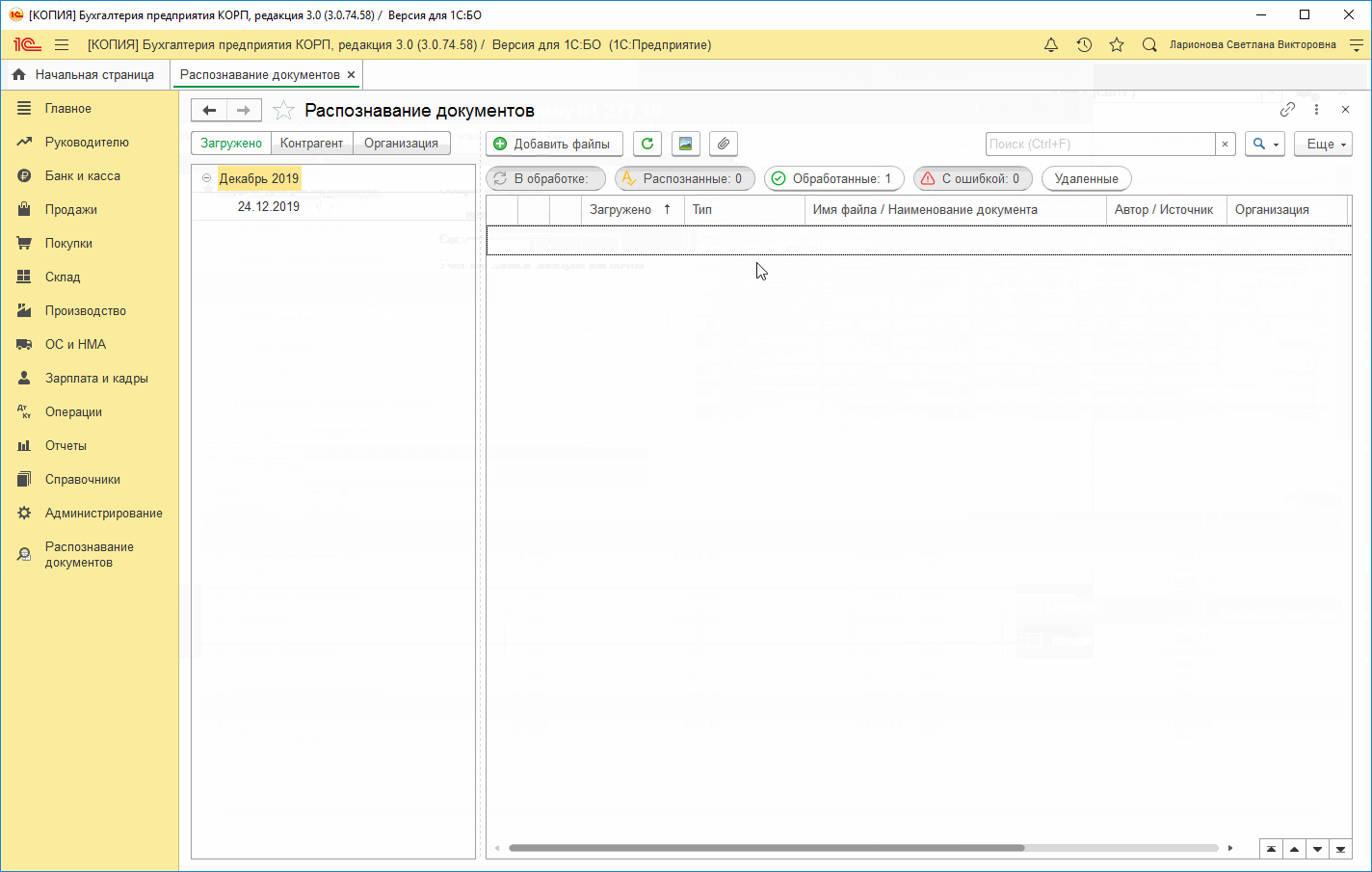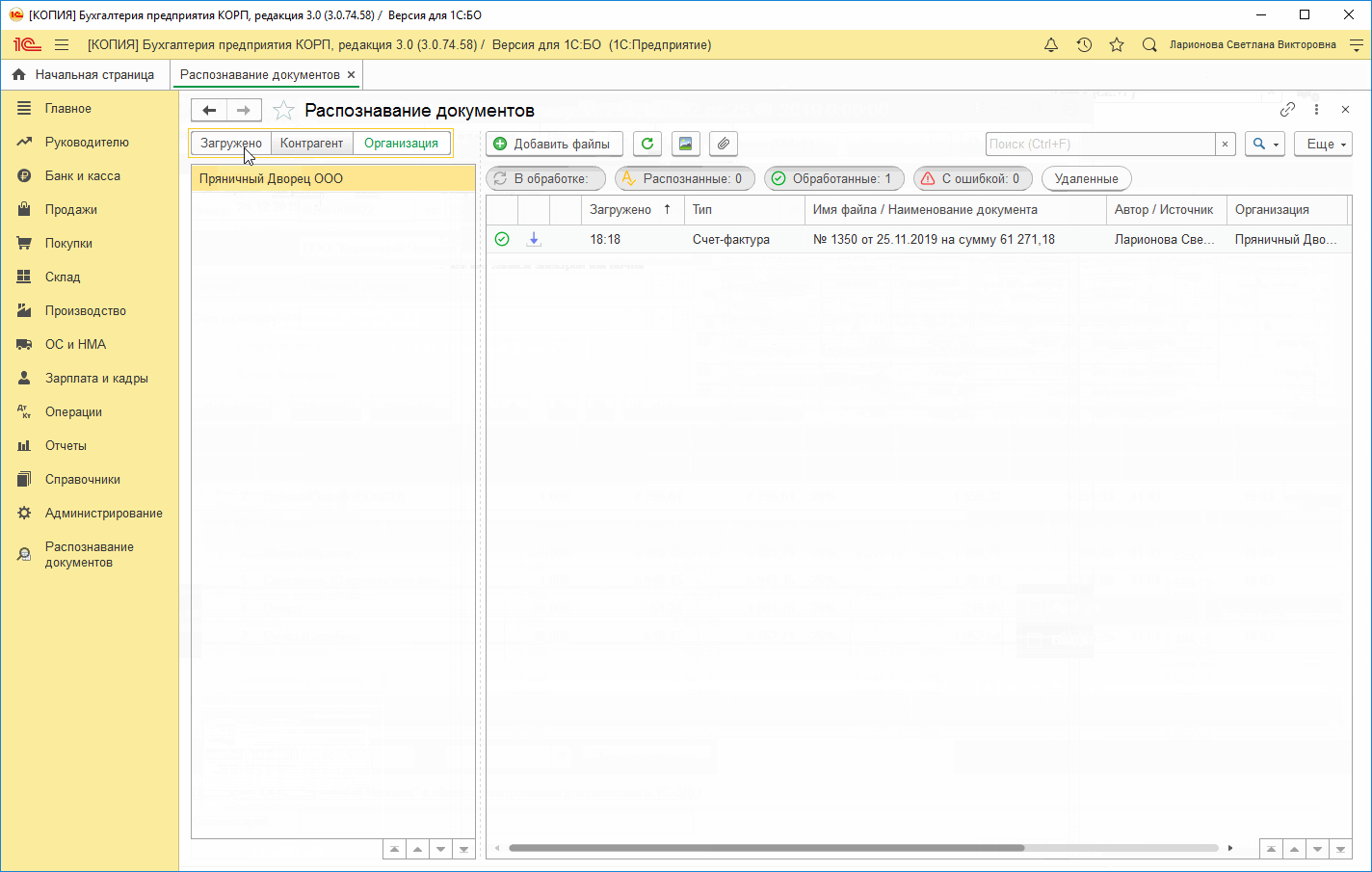
Иллюстрация с сайта www.1cfresh.com
Кто может участвовать в пилотном тестировании
На сайте облачного сервиса 1С:Фреш оговариваются критерии отбора участников для пилотного тестирования. Они касаются объема вводимых документов и готовности предоставлять обратную связь о пилотном тестировании:
-
рабочие процессы участника пилотного тестирования должны включать задачи регулярного внесения документов в приложение 1С на основе бумажных оригиналов, копий, сканов или фотографий;
-
участник должен делиться некоторыми сведениями о своем документообороте:
-
количеством обрабатываемых бумажных документов;
-
видами обрабатываемых бумажных документов;
-
временными затратами на внесение бумажных документов;
-
-
не реже, чем раз в две недели, предоставлять обратную связь о впечатлениях об использовании, регулярных и разовых проблемах, а также оценить полезность сервиса.
Подробная информация о пилотном проекте по использованию сервиса «Распознавание документов»