.png)
.png)
.png)
.png)
.png "документ")
.png "Duplicate Object")
.png "Rename")
.png "colomn")
.png "Колонка _fld1097")
Итак. Программисты 80lvl скорее всего знают все и даже больше, чем описано в статье, поэтому эта публикация будет ориентирована в первую очередь на новичков. А так как у новичка скорее всего ни репутации и стартмани - все скрипты я не буду прикреплять, а выложу в статье.
Поехали. Предположим в вашей конфигурации есть некий документ, с 5 табличными частями. В СУБД (в нашем примере PosgreSQL, но все ниже сказанное справедливо и других СУБД) такой документ предстанет в виде 6 таблиц
.png)
Предположим вам необходимо добавить реквизит в табличную часть _document39_vt415, узнать какая именно табличная часть можно либо специальными обработками, либо просто посмотрев несколько записей из таблицы в самой СУБД. Что произойдет далее, точнее что сделает платформа 1С, она создаст копии всех 6 (!) таблиц документа и начнет копирование в них данных из старых таблиц - начнется реструктуризация. Процесс этот, мягко говоря, не быстрый. Почему я вообще пишу эту статью, потому что в моем случаи: количество документов (записей в _document39 было 1М) и записей в табличных частях 25М, процесс реструктуризации документа средствами 1С занял 48 часов. Так вот мы попытаемся обмануть платформу.
Продолжаем, добавляем реквизит в табличную часть в конфигураторе, у меня это число длинной 10, точность 0 (во время всех манипуляций его можно не закрывать), сохраняем, но не обновляем. Переименовываем все таблицы документа в pgAdmin или чем вы там пользуетесь (у меня это пара pgAdmin и EMS SQL Manager PostgreSQL), например _document39 в _document39_src
.png)
И создаем копии наших переименованных таблиц (пустые) с первоначальными именами, в нашем примере делаем пустую копию _document39_src с именем _document39.
.png)
Копии я создавал в EMS SQL Manager лишь потому, что в нем это проще, но можно и в pgAdmin. В нем надо в контекстном меню таблицы выбрать Скрипты - CREATE и в окне SQL редактора изменить имя таблицы на новое.
Если посмотреть в предприятии, у нас нет ни одного документа.
Теперь, когда 1С считает, что у нас нет документов, в конфигураторе жмем обновить, реструктуризация проходить мгновенно (если возникнут ошибки, жмем обновить еще раз, до тех пор, пока не появится окно о принятии изменений).
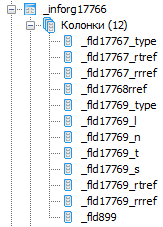
Смотрим какое имя получила новая колонка таблицы, которая соответствует новому реквизиту.
.png)
У меня это _fld1097. Возвращаемся к нашей исходной таблице, которую мы переименовали в _document39_src, добавляем новую колонку в нее
.png)
Ставим значение по умолчанию, здесь 0 и жмем ОК. Весь процесс занял около 1 часа (в 48 раз быстрее). После того как колонка создана, стираем значение по умолчанию и переименовываем таблицу обратно (у нас в _document39)
Запускаем предприятие и проверяем. Радуемся или плачем.
Итак, это мы добавили реквизит, рассмотрим теперь случай, если нам надо изменить тип реквизита, например, было число (5, 2), надо число (10, 4), или добавить индексов.
Тут есть два варианта.
Вариант первый. Создаем копии таблиц и заливаем в них данные из основной таблицы
SELECT * INTO _document39_copy FROM _document39;
SELECT * INTO _document39_vt415_copy FROM _document39_vt415;
SELECT * INTO _document39_vt431_copy FROM _document39_vt431;
SELECT * INTO _document39_vt434_copy FROM _document39_vt434;
SELECT * INTO _document39_vt437_copy FROM _document39_vt437;
SELECT * INTO _document39_vt444_copy FROM _document39_vt444;
После этого очищаем исходные таблицы, т.е. доходим до момента, когда 1С думает, что у нас нет записей в таблицах документ. Делаем все необходимые изменения в конфигураторе и обновляем. Теперь нам надо вернуть данные назад
NSERT INTO _document39(
_idrref, _version, _marked, _date_time, _numberprefix, _number,
_posted, _fld556, _fld392rref, _fld393rref, _fld394, _fld395,
_fld579, _fld396, _fld397, _fld398rref, _fld399, _fld400, _fld401rref,
_fld1018rref, _fld403, _fld402rref, _fld404rref, _fld405, _fld538rref,
_fld406, _fld407, _fld408rref, _fld409rref, _fld410rref, _fld411rref,
_fld412rref, _fld413, _fld414)
select * from _document39_copy; -- ~60min (1.5 M records)
INSERT INTO _document39_vt431(
_document39_idrref, _keyfield, _lineno432, _fld433rref)
select * from _document39_vt431_copy;
INSERT INTO _document39_vt434(
_document39_idrref, _keyfield, _lineno435, _fld436rref)
select * from _document39_vt434_copy;
INSERT INTO _document39_vt437(
_document39_idrref, _keyfield, _lineno438, _fld439rref, _fld440rref,
_fld441, _fld442rref)
select * from _document39_vt437_copy;
INSERT INTO _document39_vt444(
_document39_idrref, _keyfield, _lineno445, _fld446rref)
select * from _document39_vt444_copy; --3 min
INSERT INTO _document39_vt415(
_document39_idrref, _keyfield, _lineno416, _fld426rref, _fld423,
_fld419rref, _fld421, _fld420, _fld536, _fld425, _fld418, _fld422,
_fld428rref, _fld427rref, _fld417rref, _fld429, _fld424)
select * from _document39_vt415_copy; --16588297 строк, 18.5 h
Запускаем предприятие и проверяем. Радуемся или плачем.
Вариант второй. Кто-то считает, что INSERT INTO работает медленно, поэтому можно использовать следующие скрипты, работающие не с копиями таблицы а с файлами на диске
COPY BINARY _document39
TO 'e:/_document39';
COPY BINARY _document39_vt431
TO 'e:/_document39_vt431';
COPY BINARY _document39_vt434
TO 'e:/_document39_vt434';
COPY BINARY _document39_vt437
TO 'e:/_document39_vt437';
COPY BINARY _document39_vt444
TO 'e:/_document39_vt444';
COPY BINARY _document39_vt415
TO 'e:/_document39_vt415';
где 'e:/_document39' это файл в корне диска е.
Скрипт загружающий данные обратно
COPY BINARY _document39
FROM 'e:/_document39';
COPY BINARY _document39_vt431
FROM 'e:/_document39_vt431';
COPY BINARY _document39_vt434
FROM 'e:/_document39_vt434';
COPY BINARY _document39_vt437
FROM 'e:/_document39_vt437';
COPY BINARY _document39_vt444
FROM 'e:/_document39_vt444';
COPY BINARY _document39_vt415
FROM 'e:/_document39_vt415';
На этом, пожалуй все.
Как видно, процесс это все равно долгий (около 18 часов у меня). Что мы получили, около 19 часов против 48 при изменении типа реквизита и добавлении индексов, и около 1 часа против 48 часов при добавлении реквизита.
PS. У меня есть подозрение, что на других СУБД реструктуризация средствами платформы будет быстрей. К тому же у меня стоял старый PosgresSQL, еще 8.2.4-3.1

.png){kind=link}