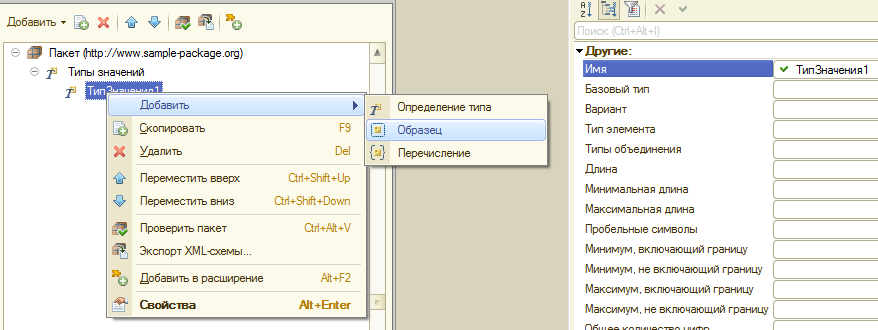
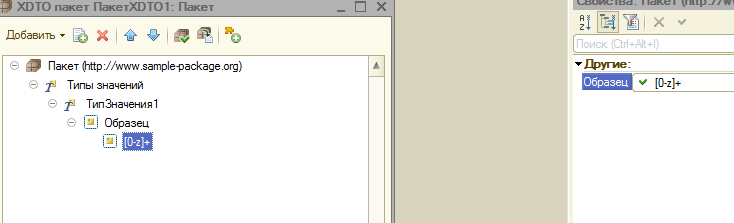
Здравствуйте, товарищи!
Дабы не затягивать, сразу приведу код. Кто хочет разобраться, в чем тут, собственно, дело, пусть читает статьи по XDTO. О регулярных выражениях расскажу ниже, но статей на эту тему и так масса.
Код:
&НаКлиенте
Функция ПроверитьСтроку(Строка, Фасет)
Чтение = Новый ЧтениеXML;
Чтение.УстановитьСтроку(
"<Model xmlns=""http://v8.1c.ru/8.1/xdto"" xmlns:xs=""http://www.w3.org/2001/XMLSchema"" xmlns:xsi=""http://www.w3.org/2001/XMLSchema-instance"" xsi:type=""Model"">
|<package targetNamespace=""sample-my-package"">
|<valueType name=""testtypes"" base=""xs:string"">
|<pattern>" + Фасет + "</pattern>
|</valueType>
|<objectType name=""TestObj"">
|<property xmlns:d4p1=""sample-my-package"" name=""TestItem"" type=""d4p1:testtypes""/>
|</objectType>
|</package>
|</Model>");
Модель = ФабрикаXDTO.ПрочитатьXML(Чтение);
МояФабрикаXDTO = Новый ФабрикаXDTO(Модель);
Пакет = МояФабрикаXDTO.Пакеты.Получить("sample-my-package");
Тест = МояФабрикаXDTO.Создать(Пакет.Получить("TestObj"));
Попытка
Тест.TestItem = Строка;
Возврат Истина
Исключение
Возврат Ложь
КонецПопытки;
КонецФункции
&НаКлиенте
Процедура Модель(Команда)
Сообщить(ПроверитьСтроку("01.01.2012","\d{2}\.\d{2}\.\d{4}"));
Сообщить(ПроверитьСтроку("01.01.20121","\d{2}\.\d{2}\.\d{4}"));
КонецПроцедуры
Все.
Для тех, кому мало...
Итак, лет этак эндцать назад программисты решили упростить поиск, замену и проверку на соответвие различных строк, т.к. им, полагаю, надоело каждый раз писать что-то типа:
Если Сред(стрДата,1,1) < "0" ИЛИ Сред(стрДата,1,1) > "9" Тогда Ошибка = Истина;
КонецЕсли;
Если Сред(стрДата,2,1) < "0" ИЛИ Сред(стрДата,2,1) > "9" Тогда Ошибка = Истина;
КонецЕсли;
Если Сред(стрДата,3,1) <> "." Тогда Ошибка = Истина;
КонецЕсли;
//...
В итоге во всех нормальных языках программирования были реализованы библиотеки, содержащие процедуры и функции для работы с регулярными выражениями, и жизнь разработчиков качественно улучшилась, ибо тот монструозный код можно было заменить на куда более простой:
Ошибка = НЕ ПроверитьСтроку(СтрДата, "\d{2}\.\d{2}\.\d{4}");
Да, грамотным разработчикам стало ой как просто. Но что делать остальным? Правилный ответ, конечно, - учиться, учиться и еще раз учиться! )))
Итак, самое простое, что нужно, чтобы освоить шаблоны проверки:
. - любой символ
+ - один или более раз, пример ".+" - один или более любой символ.
* - ноль или более раз, пример ".*" - любое количество любых символов (даже ни одного).
[n-m] - символ от m до n, пример: "[0-9]+" - одна или более цифр(а).
\d - цифра, пример \d+ - одна или более цифр(а).
\D - не цифра.
\s - пробельный символ - ТАБ, пробел, перенос строки, возврат каретки и т.п.
\S - непробельный символ.
\w - буква, цифра, подчеркивание.
\W - не буква, не цифра и не подчеркивание соответственно.
^ - начало текста, например "^\d+" - строка начинается с цифры.
$ - конец текста, например "\D+$" - строка заканчивается НЕ цифрой.
{m,n} - шаблон для от m до n символов, например "\d{2,4}" - от двух до четырех цифр. Можно указать одну и всего цифру для строгого соответвия.
\ - экранирует спецсимволы. Например, "\." - символ точки.