Как в запросе выбрать из справочника несколько случайных элементов?
По теме из базы знаний
Найденные решения
Окончательно:
РезультатВыборки = Новый Массив;
ПервоначальнаяТаблица = Новый ТаблицаЗначений;
ПервоначальнаяТаблица.Колонки.Добавить("Товар", Новый ОписаниеТипов("СправочникСсылка.Номенклатура"));
Для СчЭлементов = 1 По 2 * НадоСлЭлементов Цикл
Номенклатура = Справочники.Номенклатура.ПолучитьСсылку(Новый УникальныйИдентификатор());
СслкаИД = Номенклатура.УникальныйИдентификатор(); // Нового().УникальныйИдентификатор();
ПервоначальнаяТаблица.Добавить().Товар = Номенклатура;
КонецЦикла;
Запросо = Новый Запрос;
Запросо.Текст = "ВЫБРАТЬ
| НедействительныеСсылки.Товар КАК Товар
|ПОМЕСТИТЬ Товары
|ИЗ
| &НедействительныеСсылки КАК НедействительныеСсылки
|
|ИНДЕКСИРОВАТЬ ПО
| Товар
|;
|
|//////////////////////////////////////////////////////////// ПоказатьОстальные ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
(2) sssss_aaaaa_2011, наверняка автор имеет в виду получение с помощью ГенераторСлучайныхЧисел: пронумеровать все элементы справочника от 1 до КоличествоЭлементов, получить нужное количество случайных номеров в диапазоне от 1 до КоличествоЭлементов, получить нужные элементы по этим случайным номерам.
(4) Lovish, нумерация элементов - очень трудоемкий этап. Трудоемкость растет квадратично по отношению к числу элементов справочника. Попробуйте для примера пронумеровать в запросе свой справочник номенклатуры или контрагентов - результата придется ждать очень долго.
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Контрагенты.Ссылка,
| Контрагенты.Код
|ИЗ
| Справочник.Контрагенты КАК Контрагенты
|ГДЕ
| Контрагенты.Код ПОДОБНО &СлучайнаяСекунда";
Запрос.УстановитьПараметр("СлучайнаяСекунда","%"+ Секунда(ТекущаяДата())+"%"); Показать
на инфостарте уже писали как случайное число сделать, в запрос параметр передать думаю не составит сложности
//НВЮ/ Получение Случайного Числа
//
// Параметры
// <Мин> - <Число> - Нижняя граница Равномерного Распределения
// <Макс> - <Число> - Верхняя граница Равномерного Распределения
//
// Возвращаемое значение:
// <Число> - Сгенерированное случайное число
//
Функция ПолучитьСлучайноеЧисло(Мин=0,Макс=100) Экспорт
//вместо Randomize
Для н = 1 По Макс Цикл
Уник = Новый УникальныйИдентификатор;
КонецЦикла;
//генерируем GUID
Уник = СокрЛП(Новый УникальныйИдентификатор);
//оставляем только цифры
Уник = СтрЗаменить(Уник,"-","");
Уник = СтрЗаменить(Уник,Символы.НПП,"");
Случ = 0;
//знаменатель должен иметь такую же разрядность
Знаменатель = 1;
Для н = 1 По (СтрДлина(Уник)) Цикл
ТекС = Сред(Уник,н,1);
Если ТекС="a" Тогда
Случ = Случ + Знаменатель*10;
ИначеЕсли ТекС="b" Тогда
Случ = Случ + Знаменатель*11;
ИначеЕсли ТекС="c" Тогда
Случ = Случ + Знаменатель*12;
ИначеЕсли ТекС="d" Тогда
Случ = Случ + Знаменатель*13;
ИначеЕсли ТекС="e" Тогда
Случ = Случ + Знаменатель*14;
ИначеЕсли ТекС="f" Тогда
Случ = Случ + Знаменатель*15;
ИначеЕсли ТекС="1" Тогда
Случ = Случ + Знаменатель;
ИначеЕсли ТекС="2" Тогда
Случ = Случ + Знаменатель*2;
ИначеЕсли ТекС="3" Тогда
Случ = Случ + Знаменатель*3;
ИначеЕсли ТекС="4" Тогда
Случ = Случ + Знаменатель*4;
ИначеЕсли ТекС="5" Тогда
Случ = Случ + Знаменатель*5;
ИначеЕсли ТекС="6" Тогда
Случ = Случ + Знаменатель*6;
ИначеЕсли ТекС="7" Тогда
Случ = Случ + Знаменатель*7;
ИначеЕсли ТекС="8" Тогда
Случ = Случ + Знаменатель*8;
ИначеЕсли ТекС="9" Тогда
Случ = Случ + Знаменатель*9;
КонецЕсли;
Знаменатель = Знаменатель * 16;
КонецЦикла;
Случ = Случ / Знаменатель; //здесь получается дробное случайное число от 0 до 1
//преобразуем его в случайное число из заданного интервала, округляем до целого
ЧислоИзИнтервала = Мин(Макс(Окр(Мин + (Макс-Мин)*Случ),Мин),Макс);
Возврат ЧислоИзИнтервала;
КонецФункции //ПолучитьСлучайноеЧисло() Показать
в самом запросе случаное не получить, в любом случае, случайные числа нужно получать отдельно и передавать в запрос в виде параметров или в виде таблицы значений с числами. а там уже у кого как фантазия работает.
(17) spezc, ну почему же - можно. Топикстартер стартанул таким тоном, что раскалываться не хотелось, но, видимо, что-то озвучить придётся :(
ГенераторСлучайныхЧисел не на волшебной пыльце работает, это обычные вычисления, которые можно проделать в запросе. Классический ГСЧ (дальше могу слегка напутать - последний раз занимался этим вопросом ещё в прошлом веке) это два нечётных (чтобы не накапливались нули в младших разрядах, что приведёт к вырождению ГСЧ) числа - seed и как_там_его_называют. Каждое обращение к ГСЧ происходит следующее:
Всего делов - передать в параметре запроса случайный seed, чтобы последовательные выполнения этого запроса приводили к разным результатам.
ГенераторСлучайныхЧисел не на волшебной пыльце работает, это обычные вычисления, которые можно проделать в запросе. Классический ГСЧ (дальше могу слегка напутать - последний раз занимался этим вопросом ещё в прошлом веке) это два нечётных (чтобы не накапливались нули в младших разрядах, что приведёт к вырождению ГСЧ) числа - seed и как_там_его_называют. Каждое обращение к ГСЧ происходит следующее:
как_там_его_называют=(seed*как_там_его_называют) % 2^разрядность;
Возврат как_там_его_называют;Всего делов - передать в параметре запроса случайный seed, чтобы последовательные выполнения этого запроса приводили к разным результатам.
(17) spezc, тут я и хотел разнообразные фантазии увидеть. Даже если ввести таблицу случайных чисел или случайный параметр - что дальше со справочником делать? Тут уже предложили через "подобно" отбирать, но тогда некоторые коды могут иметь преимущество при выборе. А хотелось бы бОльшей случайности.
А возможно, кто-то и источник энтропии в запросе подскажет где взять. Если работа многопользовательская, то можно время последнего записанного документа использовать, но это крайне не надежно.
А возможно, кто-то и источник энтропии в запросе подскажет где взять. Если работа многопользовательская, то можно время последнего записанного документа использовать, но это крайне не надежно.
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Контрагенты.Ссылка
|ИЗ
| Справочник.Контрагенты КАК Контрагенты
|ГДЕ
| Контрагенты.ЭтоГруппа = ЛОЖЬ";
Тз = Запрос.Выполнить().Выгрузить();
Тз.Колонки.Добавить("Сортировка",Новый ОписаниеТипов("Число"));
Для каждого строка из ТЗ цикл
ГСЧ = Новый ГенераторСлучайныхЧисел;
Строка.Сортировка= ГСЧ.СлучайноеЧисло(0, 4294967295);
КонецЦикла;
Запрос2 = Новый Запрос;
Запрос2.Текст =
"ВЫБРАТЬ
| кТ.Ссылка,
| кТ.Сортировка
|ПОМЕСТИТЬ КТВ
|ИЗ
| &Кт КАК кТ
|;
|
|//////////////////////////////////////////////////////////// Показать2 запрос выбирает случайные элементы =)
п.с. просьба сильно не бить ))
(26) Cool_vsi, это будет работать, но все же это не метод "в запросе".
Кроме того, если уж выбрали весь справочник в память, нужно сразу выбирать из него элементы генерацией пяти случайных чисел (проверив, что они различные). Это будет гораздо быстрее, чем для каждой строки получить случайное число (а если строк 10 тысяч?), а затем эту огромную таблицу перегонять в запрос.
Тут как раз и видна проблема: для того, чтобы выбрать всего пять элементов, приходится выбирать все элементы справочника.
Кроме того, если уж выбрали весь справочник в память, нужно сразу выбирать из него элементы генерацией пяти случайных чисел (проверив, что они различные). Это будет гораздо быстрее, чем для каждой строки получить случайное число (а если строк 10 тысяч?), а затем эту огромную таблицу перегонять в запрос.
Тут как раз и видна проблема: для того, чтобы выбрать всего пять элементов, приходится выбирать все элементы справочника.
(30) ildarovich, я сам удивился но работает быстро, меньше секунды для 7000 элементов, формально исходя из название темы все условия соблюдены ..а реально да , это не 1 запрос..насчет выборки всех элементов, думаю если в запросе сделать несколько виртуальных таблиц,в которых будут все элементы то по скорости будет не намного быстрее...да сам хочу посмотреть на чистый запрос в 1с, который быстро случайно выберет n элементов...
все что можно написать из 1С (по моему мнению) - это проиндексировать выборку случайными значениями и потом выбрать N элементов с учетом сортировки - способ затратный получается.
Проще сделать прямой запрос к базе и получить в зависимости от вида SQL (NEWID()), Рostgree (Random()), db2(не помню, но тоже что то c RAND()) набор ID - в случае файловой остается чистый 1с например - выборка.Следующий и ГСЧ.
не универсально конечно.. но и ресурсы не резиновые - создания таблиц порождающими запросами да если еще и не в один поток - быстро загонит бд в ступор
Проще сделать прямой запрос к базе и получить в зависимости от вида SQL (NEWID()), Рostgree (Random()), db2(не помню, но тоже что то c RAND()) набор ID - в случае файловой остается чистый 1с например - выборка.Следующий и ГСЧ.
не универсально конечно.. но и ресурсы не резиновые - создания таблиц порождающими запросами да если еще и не в один поток - быстро загонит бд в ступор
ВЫБРАТЬ
СотрудникиОрганизаций.Ссылка КАК НомерСтроки,
ПОДСТРОКА(СотрудникиОрганизаций.Код, 0, 10) КАК Строка
ПОМЕСТИТЬ Дано
ИЗ
Справочник.СотрудникиОрганизаций КАК СотрудникиОрганизаций
;
//////////////////////////////////////////////////////////// ПоказатьИспользование остатка от деления на случайное число как сортировку
(36) minimajack, я так понимаю что при сид=постоянное значению(попробовал разные варианты сид при одинаковых вариантах сид рез одинаков), то и выводиться будут тоже самое. Вариант 11 такойже только лаконичнее. Рандом число все-равно передается в запрос, и все пляшет от него.
(38) minimajack, общий принцип одинаковый, передаем случайное число получаем случайное, вариантов на самом деле очень много если передавать случайное число...я думаю всем интересен запрос, который сам будет генерировать случайный элементы без передачи в него случайных чисел, ваш вариант интересен с математической точки зрения...но с точки зрения скорости работы и принципа если есть вариант проще не стоит загоняться, ваш вариант проигрывает другим вариантом с прицыпом передачи в запрос случайного числа...
Если не передавать в запрос случайные значения, то можно только ориентироваться на какие-то изменения в базе. Например, как писалось выше на время создания, версию данных последнего документа или на количество каких-то записей. Но если с данными ничего не происходит, то вариантов нет.
(39) hibico, вообще говоря, можно создать небольшую временную таблицу, где хранить номер итерации, увеличивая его при каждой следующей случайной выборке.
Но, конечно, хочется чего-либо типа времени, объема свободной памяти, всего, что может быть настоящим источником энтропии. ...блокировки?...
Но, конечно, хочется чего-либо типа времени, объема свободной памяти, всего, что может быть настоящим источником энтропии. ...блокировки?...
(43) ildarovich, в доступных функциях запроса ничего не доступно, так что хоть тысячу раз запускай - ничего не изменится и во временных таблицах...причина этому - детерминированность алгоритмов - фактически это закон для компьютера. У нас не квантовые компьютеры - так что без внешнего источника энтропии - рыпаться бесполезно.
Если есть возможность сгенерировать до запроса, есть МенеджерКриптографии - там и парится не надо.
Если есть возможность сгенерировать до запроса, есть МенеджерКриптографии - там и парится не надо.
ВЫБРАТЬ
Контрагенты.Ссылка КАК Ссылка,
Контрагенты.Код КАК Код,
КОЛИЧЕСТВО(Контрагенты.Код) * 0 КАК Индекс
ПОМЕСТИТЬ ВТ_ДАННЫЕ
ИЗ
Справочник.Контрагенты КАК Контрагенты
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты1
ПО Контрагенты.Ссылка >= Контрагенты1.Ссылка
СГРУППИРОВАТЬ ПО
Контрагенты.Ссылка,
Контрагенты.Код
ИНДЕКСИРОВАТЬ ПО
Индекс
;
//////////////////////////////////////////////////////////// ПоказатьНашел!!! =))
Индексирование наше все )) для скульной базы работает
(61) reznic,
а без генератора случайных чисел можно?
можно, но тогда выборка не будет случайной, поэтому нельзя и как быть если ты не попадешь в номер элемента?
а для этого случайное число надо нормировать. Типа вот так: НомерЭлемента=СлучайноеЧисло*КоличествоЭлементов/МаксимальноеСлучайноеЧисло
Ну если передавать через параметр случайное число нельзя, тогда можно создать какой-то объект (или использовать существующий), например регистр сведений, и с какой-нибудь периодичностью заполнять его новым случайным числом (числами). А в запросе выбирать данный объект и на его основе делать выборку элементов.
(68) Cool_vsi, метод, приведенный в (26) слабо соответствует условиям задачи. Главное в условии - сделать выбор "в запросе". У вас же основные действия, а именно, добавление колонки со случайными числами, производятся вне запроса.
То есть последовательность у вас такова:
1) выбираем ВЕСЬ справочник в таблицу значений;
2) добавляем колонку и записываем в каждый элемент новой колонки случайное число;
3) возвращаем ВЕСЬ справочник с добавленной колонкой в запрос;
4) сортируем по рандомному столбцу;
5) отбираем первые 5.
Если убрать из вашего алгоритма явно избыточные (абсолютно лишние) действия, то должен остаться алгоритм:
1) выбираем ВЕСЬ справочник в таблицу значений;
2) выбираем с помощью ГСЧ из таблицы значений 5 разных элементов;
3) возвращаем выбранные случайные элементы в запрос.
то станет очевидным, где на самом деле делается случайный выбор.
Вот, например, в статье есть запрос, формирующий временную таблицу псевдослучайных чисел прямо в запросе. То есть проблемы получения таблицы псевдослучайных чисел в запросе нет. Проблема в том, чтобы соединить ее с таблицей справочника, не выводя их из запроса. Вы этот вопрос обошли, нарушив (по моему мнению) условия задачи.
С другой стороны, предложенный в (26) метод (с учетом поправок) очевиден и для практики совершенно нормален (единственно возможен?), если не задано условие "в запросе".
То есть последовательность у вас такова:
1) выбираем ВЕСЬ справочник в таблицу значений;
2) добавляем колонку и записываем в каждый элемент новой колонки случайное число;
3) возвращаем ВЕСЬ справочник с добавленной колонкой в запрос;
4) сортируем по рандомному столбцу;
5) отбираем первые 5.
Если убрать из вашего алгоритма явно избыточные (абсолютно лишние) действия, то должен остаться алгоритм:
1) выбираем ВЕСЬ справочник в таблицу значений;
2) выбираем с помощью ГСЧ из таблицы значений 5 разных элементов;
3) возвращаем выбранные случайные элементы в запрос.
то станет очевидным, где на самом деле делается случайный выбор.
Вот, например, в статье есть запрос, формирующий временную таблицу псевдослучайных чисел прямо в запросе. То есть проблемы получения таблицы псевдослучайных чисел в запросе нет. Проблема в том, чтобы соединить ее с таблицей справочника, не выводя их из запроса. Вы этот вопрос обошли, нарушив (по моему мнению) условия задачи.
С другой стороны, предложенный в (26) метод (с учетом поправок) очевиден и для практики совершенно нормален (единственно возможен?), если не задано условие "в запросе".
как вариант... не нравится мне все таки идея с запросом в котором все...
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Номенклатура.Ссылка,
| КОЛИЧЕСТВО(Номенклатура1.Код) КАК НомерСтроки
|ИЗ
| Справочник.Номенклатура КАК Номенклатура
| ПОЛНОЕ СОЕДИНЕНИЕ Справочник.Номенклатура КАК Номенклатура1
| ПО (Номенклатура.Код >= Номенклатура1.Код)
|
|СГРУППИРОВАТЬ ПО
| Номенклатура.Ссылка";
РезультатЗапроса = Запрос.Выполнить();
Выборка = РезультатЗапроса.Выбрать();
Граница = Выборка.Количество();
ГСЧ = Новый ГенераторСлучайныхЧисел(ТекущаяДата());
КоличествоСлучайных = 5;
сч = 1;
ТЗ = Новый ТаблицаЗначений;
ТЗ.Колонки.Добавить("Ссылка");
Пока сч <= КоличествоСлучайных Цикл
Индекс = ГСЧ.СлучайноеЧисло(1, Граница);
Выборка.НайтиСледующий(Новый Структура("НомерСтроки",Индекс));
НоваяСтрока = ТЗ.Добавить();
НоваяСтрока.Ссылка = Выборка.Ссылка;
сч = сч +1;
КонецЦикла;
Показать
(71) (75) caponid, совершенно лишняя нумерация справочника в запросе. Это тяжелая операция, которая требует соединения справочника с собой. Если разрешить себе выбор вне запроса (что не соответствует условию), то лучше делать так
Конечно, в практическом применении нужно учесть, что справочник может содержать менее 5 элементов и проверять зацикливание, ну и обеспечить выбор пяти РАЗЛИЧНЫХ ссылок вообще не через долгий подсчет, а через соответствие.
Запрос = Новый Запрос("ВЫБРАТЬ Ссылка, 0 КАК Отбор ИЗ Справочник.Номенклатура ГДЕ НЕ ЭтоГруппа");
ВсеСсылки = Запрос.Выполнить().Выгрузить();
ГСЧ = Новый ГенераторСлучайныхЧисел();
Пока ВсеСсылки.Итог("Отбор") < 5 Цикл
ВсеСсылки[ГСЧ.СлучайноеЧисло(0, ВсеСсылки.Количество() - 1)].Отбор = 1
КонецЦикла;
Запрос = Новый Запрос("ВЫБРАТЬ * ИЗ Справочник.Номенклатура ГДЕ Ссылка В (&ОтборныеСсылки)");
Запрос.УстановитьПараметр("ОтборныеСсылки", ВсеСсылки.Скопировать(Новый Структура("Отбор", 1)));
Запрос.Выполнить().Выгрузить().ВыбратьСтроку("Случайные элементы:")
Показать
Какие вообще есть варианты?
В общем случае внутри запроса 1С получить случайное число невозможно (в частном случае, есть разные варианты – например, считать количество каких-либо постоянно добавляемых элементов справочника или смотреть какой-то объект в базе, куда мы постоянно специально будем записывать случайное число).
Следовательно, при выполнении запроса придётся каждый раз передавать случайное число (назову его Rand), т.е. при инициализации запроса одним и тем же случайным числом мы получим одни и те же "случайные" данные.
Итак, мы передали в запрос случайное число, что дальше?
Чтобы решение было универсальным мы можем привязаться только к стандартным реквизитам (других в справочнике просто может и не быть).
Из стандартных реквизитов подходит нам всего два - это уникальный "код" и относительно случайное "наименование". (С "ссылкой" мы никаких операций в запросе не сможем провести, поэтому она не подходит. Остальные реквизиты не обеспечивают практически никакой случайности, хотя если добавить и их, то случайность как минимум не понизится, но это замедлит процесс вычисления.)
Какой бы путь мы не выбрали нам всё равно придётся генерировать некий ключ на основе реквизитов "код" и "наименование" (в документах была бы ещё и "дата"). И ключ этот должен быть числовой, чтобы далее взаимодействовать с Rand.
Алгоритм вычисления ключа: Допустим и "наименование" и "код" имеют тип "строка". Чтобы обеспечить перевод строк в числа, нам понадобится временная таблица кодировки символов (с полями "Символ" и "Число") и функция "ПОДСТРОКА". Таким образом, выбирая символ, мы сразу сопоставляем ему число. Ну а далее из этих чисел по какой-нибудь хитрой формуле считаем ключ. Например, перемножаем все числа между собой (что-то у меня фантазия ещё не разогрелась).
Имея у каждого элемента справочника уникальный числовой ключ и случайное число, которым мы инициализировали запрос, выбрать случайные несколько элементов уже проще. Например, считаем поле «Порядок» как остаток от деления «ключа» на «Rand» (с помощью функции «Выразить»). Далее упорядочиваем по полю «Порядок» и выбираем первые N.
В общем случае внутри запроса 1С получить случайное число невозможно (в частном случае, есть разные варианты – например, считать количество каких-либо постоянно добавляемых элементов справочника или смотреть какой-то объект в базе, куда мы постоянно специально будем записывать случайное число).
Следовательно, при выполнении запроса придётся каждый раз передавать случайное число (назову его Rand), т.е. при инициализации запроса одним и тем же случайным числом мы получим одни и те же "случайные" данные.
Итак, мы передали в запрос случайное число, что дальше?
Чтобы решение было универсальным мы можем привязаться только к стандартным реквизитам (других в справочнике просто может и не быть).
Из стандартных реквизитов подходит нам всего два - это уникальный "код" и относительно случайное "наименование". (С "ссылкой" мы никаких операций в запросе не сможем провести, поэтому она не подходит. Остальные реквизиты не обеспечивают практически никакой случайности, хотя если добавить и их, то случайность как минимум не понизится, но это замедлит процесс вычисления.)
Какой бы путь мы не выбрали нам всё равно придётся генерировать некий ключ на основе реквизитов "код" и "наименование" (в документах была бы ещё и "дата"). И ключ этот должен быть числовой, чтобы далее взаимодействовать с Rand.
Алгоритм вычисления ключа: Допустим и "наименование" и "код" имеют тип "строка". Чтобы обеспечить перевод строк в числа, нам понадобится временная таблица кодировки символов (с полями "Символ" и "Число") и функция "ПОДСТРОКА". Таким образом, выбирая символ, мы сразу сопоставляем ему число. Ну а далее из этих чисел по какой-нибудь хитрой формуле считаем ключ. Например, перемножаем все числа между собой (что-то у меня фантазия ещё не разогрелась).
Имея у каждого элемента справочника уникальный числовой ключ и случайное число, которым мы инициализировали запрос, выбрать случайные несколько элементов уже проще. Например, считаем поле «Порядок» как остаток от деления «ключа» на «Rand» (с помощью функции «Выразить»). Далее упорядочиваем по полю «Порядок» и выбираем первые N.
(72) Патриот, все логично, примерно так у меня и сделано. Я, в общем-то, задал вопрос для проверки: не пропустил ли я какой-либо более простой вариант решения этой задачи или нет ли какой свежей идеи. Ссылку на свое решение специально не привел, чтобы не затормозить приток идей.
Для меня обсуждение оказалось полезным по нескольким причинам:
- в комментарии (11) предложена свежая идея использование оператора "ПОДОБНО". Если бы можно обеспечить "ортогональность" сравнения через "ПОДОБНО" кодов справочника с несколькими базисными строками (чтобы результат сравнения делил справочник примерно пополам и для каждой базисной строки деление было бы независимым), то можно было бы развить этот подход;
- в комментарии (23) приведена полезная ссылка, которая напомнила, как можно ускорить решение, сократив затраты на сортировку. В результате смог еще ускорить свое решение;
- в комментарии (45) приведена одна из возможностей нахождения источника энтропии в запросе (правда, не надежная) и остается небольшая надежда, что, вдруг, есть и другие.
Для меня обсуждение оказалось полезным по нескольким причинам:
- в комментарии (11) предложена свежая идея использование оператора "ПОДОБНО". Если бы можно обеспечить "ортогональность" сравнения через "ПОДОБНО" кодов справочника с несколькими базисными строками (чтобы результат сравнения делил справочник примерно пополам и для каждой базисной строки деление было бы независимым), то можно было бы развить этот подход;
- в комментарии (23) приведена полезная ссылка, которая напомнила, как можно ускорить решение, сократив затраты на сортировку. В результате смог еще ускорить свое решение;
- в комментарии (45) приведена одна из возможностей нахождения источника энтропии в запросе (правда, не надежная) и остается небольшая надежда, что, вдруг, есть и другие.
(73) anterehin,
1. отнимая от текущей даты константу случайность не повысится, т.е. легче просто взять текущую дату.
2. текущую дату надо в запрос передать, т.к. внутри её не вычислить.
3. "Дата регистрации организации" скорее всего есть не в каждой базе, т.е. это ограничивает универсальность
1. отнимая от текущей даты константу случайность не повысится, т.е. легче просто взять текущую дату.
2. текущую дату надо в запрос передать, т.к. внутри её не вычислить.
3. "Дата регистрации организации" скорее всего есть не в каждой базе, т.е. это ограничивает универсальность
или вот еще вариант
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| КОЛИЧЕСТВО(Номенклатура.Ссылка) КАК ИндексВыборки
|ИЗ
| Справочник.Номенклатура КАК Номенклатура
|ГДЕ
| НЕ Номенклатура.ЭтоГруппа";
ТЗ = Запрос.Выполнить().Выгрузить();
Граница = ТЗ[0].ИндексВыборки;
ТЗ.Очистить();
ГСЧ = Новый ГенераторСлучайныхЧисел(ТекущаяДата());
КоличествоСлучайных = 5;
сч = 1;
Пока сч <= КоличествоСлучайных Цикл
Индекс = ГСЧ.СлучайноеЧисло(0, Граница);
НоваяСтрока = ТЗ.Добавить();
НоваяСтрока.ИндексВыборки = Индекс;
сч = сч +1;
КонецЦикла;
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ВнешняяТаблица.ИндексВыборки
|ПОМЕСТИТЬ ВТВыборки
|ИЗ
| &ТЗ КАК ВнешняяТаблица
|;
|
|//////////////////////////////////////////////////////////// Показать
Я сделал-бы что-то вроде:
В результате всё решается в один запрос, без промежуточных таблиц и без анализа значений реквизитов справочника (в конце концов, разработчик может установить для кода или для наименования нулевую длину, и тогда просто нечего будет анализировать).
Запрос = Новый Запрос;
Запрос.Текст = "Выбрать Спр.Ссылка ИЗ Справочник.Контрагенты ГДЕ ..."; // Условие не пишу. Любое, которое нужно
Выборка = Запрос.Выполнить.Выбрать();
МассивСлучайныхЧисел = ПолучитьМассивСлучайныхЧисел();
// Функция "ПолучитьМассивСлучайныхЧисел()" должна возвращать массив случайных чисел
// от 0 (включая) до 1 (не включая) в нужном для задачи количестве.
// Как сгенерировать случайное число - обсуждать не хочу, в этой ветке предложено много хороших вариантов,
// кроме того в интернете очень много алгоритмов на эту тему.
Для каждого СлучайноеЧисло из МассивСлучайныхЧисел Цикл
СлучайнаяСсылка = Выборка.Получить( Цел( СлучайноеЧисло * Выборка.Количество() ) );
Сообщить( Строка( СлучайнаяСсылка ) );
КонецЦикла;
ПоказатьВ результате всё решается в один запрос, без промежуточных таблиц и без анализа значений реквизитов справочника (в конце концов, разработчик может установить для кода или для наименования нулевую длину, и тогда просто нечего будет анализировать).
РезультатВыборки = Новый Массив;
Для СчЭлементов = 1 По НадоСлЭлементов Цикл
Номенклатура = Справочники.Номенклатура.ПолучитьСсылку(Новый УникальныйИдентификатор());
СслкаИД = Номенклатура.УникальныйИдентификатор(); // Нового().УникальныйИдентификатор();
Запросо = Новый Запрос;
Запросо.Текст = "ВЫБРАТЬ ПЕРВЫЕ 1
| ЕСТЬNULL(Номенклатура.Ссылка, ПервыйЭлемент.Ссылка) КАК Номенклатура
|ИЗ
| Справочник.Номенклатура КАК Номенклатура
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ (ВЫБРАТЬ ПЕРВЫЕ 1
| Номенклатура.Ссылка КАК Ссылка
| ИЗ
| Справочник.Номенклатура КАК Номенклатура
| ГДЕ
| Номенклатура.ЭтоГруппа = ЛОЖЬ) КАК ПервыйЭлемент
| ПО (ИСТИНА)
|ГДЕ
| Номенклатура.Ссылка >= &Ссылка
| И НЕ Номенклатура.Ссылка В (&Массиво)
| И Номенклатура.ЭтоГруппа = ЛОЖЬ";
Запросо.УстановитьПараметр("Ссылка", Номенклатура);
Запросо.УстановитьПараметр("Массиво", РезультатВыборки);
РезЗапроса = Запросо.Выполнить();
Если Не РезЗапроса.Пустой() Тогда
Номенклатура = РезЗапроса.Выгрузить()[0].Номенклатура;
РезультатВыборки.Добавить(Номенклатура);
КонецЕсли;
КонецЦикла;
СлучайныеТовары.ЗагрузитьЗначения(РезультатВыборки);
СлучайныеТовары.СортироватьПоЗначению(НаправлениеСортировки.Возр);
ПоказатьКажется, что первый элемент будет часто попадаться - но это лишь дыра в воображении. И тесты и разброс GUID-ов показывают, что все очень равномерно. Могут возникнуть трудности с количеством элементов сравнимым с мощностью справочника (быстродействие) - серия последовательных запросов ведет себя медленнее одного запроса сразу с таблицей внутри,
который можно сделать следуя данной методике: нагенерировав гуидов, представив их ссылками на справочник, запихнув в таблицу и связав со справочником выбирая максимум по существующим ссылкам в группировках по придуманным.
Сейчас попробую :)
РезультатВыборки = Новый Массив;
ПервоначальнаяТаблица = Новый ТаблицаЗначений;
ПервоначальнаяТаблица.Колонки.Добавить("Товар", Новый ОписаниеТипов("СправочникСсылка.Номенклатура"));
Для СчЭлементов = 1 По НадоСлЭлементов Цикл
Номенклатура = Справочники.Номенклатура.ПолучитьСсылку(Новый УникальныйИдентификатор());
СслкаИД = Номенклатура.УникальныйИдентификатор(); // Нового().УникальныйИдентификатор();
ПервоначальнаяТаблица.Добавить().Товар = Номенклатура;
КонецЦикла;
Запросо = Новый Запрос;
Запросо.Текст = "ВЫБРАТЬ
| НедействительныеСсылки.Товар КАК Товар
|ПОМЕСТИТЬ Товары
|ИЗ
| &НедействительныеСсылки КАК НедействительныеСсылки
|
|ИНДЕКСИРОВАТЬ ПО
| Товар
|;
|
|//////////////////////////////////////////////////////////// Показать700 товаров менее чем за 2 секунды, есть повторения, но не первого элемента,
можно задавать 1300 товаров, сворачивать и 700 обрезать.
... результат в таблице, ВЫБРАТЬ РАЗЛИЧНЫЕ ... и
Файловая база 13 секунд 1300 неуникальных, 878 уникальных.
Окончательно:
РезультатВыборки = Новый Массив;
ПервоначальнаяТаблица = Новый ТаблицаЗначений;
ПервоначальнаяТаблица.Колонки.Добавить("Товар", Новый ОписаниеТипов("СправочникСсылка.Номенклатура"));
Для СчЭлементов = 1 По 2 * НадоСлЭлементов Цикл
Номенклатура = Справочники.Номенклатура.ПолучитьСсылку(Новый УникальныйИдентификатор());
СслкаИД = Номенклатура.УникальныйИдентификатор(); // Нового().УникальныйИдентификатор();
ПервоначальнаяТаблица.Добавить().Товар = Номенклатура;
КонецЦикла;
Запросо = Новый Запрос;
Запросо.Текст = "ВЫБРАТЬ
| НедействительныеСсылки.Товар КАК Товар
|ПОМЕСТИТЬ Товары
|ИЗ
| &НедействительныеСсылки КАК НедействительныеСсылки
|
|ИНДЕКСИРОВАТЬ ПО
| Товар
|;
|
|//////////////////////////////////////////////////////////// Показать
(87) vugluscr1991, - отлично!
Нужно сказать, что такой способ я не стал пробовать из-за того, что запрос, в котором было "УПОРЯДОЧИТЬ ПО Ссылка" вернул мне явно не случайный порядок. Теперь думаю, что если сформировать справочник, генерируя ему уникальные идентификаторы подобным образом, то порядок был бы случайным. Нужно будет проверить.
Получается, что 2 (13) секунды 700 случайных элементов (пусть с повторением). А сколько всего элементов было в справочнике?
Нужно сказать, что такой способ я не стал пробовать из-за того, что запрос, в котором было "УПОРЯДОЧИТЬ ПО Ссылка" вернул мне явно не случайный порядок. Теперь думаю, что если сформировать справочник, генерируя ему уникальные идентификаторы подобным образом, то порядок был бы случайным. Нужно будет проверить.
Получается, что 2 (13) секунды 700 случайных элементов (пусть с повторением). А сколько всего элементов было в справочнике?
(96) vugluscr1991, не очень быстро для такого объема справочника. Улучшенный вариант того запроса, что описан в примере 3 в статье выдает 700 случайных элементов из справочника 15000 элементов примерно за 0,5 секунды.
Так что, если тщательно протестировать ваш метод на предмет равномерности распределения и там все будет хорошо, то его область применения - малые выборки.
Так что, если тщательно протестировать ваш метод на предмет равномерности распределения и там все будет хорошо, то его область применения - малые выборки.
(98) ildarovich,
03.04.2015 20:31:14
Новый Запрос;
Выполнить();
03.04.2015 20:31:31
113 579 элементов в справочнике
700 случайных
Средне настроенный MS SQL на серверной платформе (аппаратное железо)
Дальнейшие тесты на платформе (умножение на 2 для случайных ссылок исключено из алгоритма 700 берем и количество уникальных смотрим):
200 000 элементов: 17 секунд 674 уникальных
66 000 элементов: 8 секунд 630 уникальных
9 000 элементов: 2 секунды 568 уникальных
1 000 элементов: менее секунды 77 уникальных
03.04.2015 20:31:14
Новый Запрос;
Выполнить();
03.04.2015 20:31:31
113 579 элементов в справочнике
700 случайных
Средне настроенный MS SQL на серверной платформе (аппаратное железо)
Дальнейшие тесты на платформе (умножение на 2 для случайных ссылок исключено из алгоритма 700 берем и количество уникальных смотрим):
200 000 элементов: 17 секунд 674 уникальных
66 000 элементов: 8 секунд 630 уникальных
9 000 элементов: 2 секунды 568 уникальных
1 000 элементов: менее секунды 77 уникальных
(99) vugluscr1991, спасибо за результаты. Вообще метод мне понравился тем, что для выбора одного (или нескольких) элемента он очень быстр. Но при более глубоких размышлениях обнаружил в нем серьезный "математический" дефект - он никак не обеспечивает равной вероятности выбора различных элементов справочника.
Дело в том, что вероятность выбора одного элемента будет пропорционально расстоянию до следующего элемента (если представить ссылку как большое целое число, задающее положение элемента на числовой оси). Это расстояние складывается случайным образом при формировании идентификаторов элементов справочника, но остается фиксированным при наших выборках. И может быть очень разным для разных пар соседних элементов. Если сразу за конкретным элементом расположен следующий, а после него - большое расстояние, то этот первый элемент имеет очень мало шансов быть выбранным. И если распределение сгенерированных случайно ссылок на числовой оси более - менее равномерно, то вот расстояние между соседними элементами распределено неравномерно (кажется, по закону Пуассона или близкому к нему). Так что добиться равновероятности, не распределяя ссылки равномерно (что мы сделать не можем), не получится. Поэтому правильный алгоритм, видимо, вынужден быть линейным по времени - предусматривать обработку каждой ссылки. Или опираться на готовую сплошную нумерацию элементов.
Как-то так.
Дело в том, что вероятность выбора одного элемента будет пропорционально расстоянию до следующего элемента (если представить ссылку как большое целое число, задающее положение элемента на числовой оси). Это расстояние складывается случайным образом при формировании идентификаторов элементов справочника, но остается фиксированным при наших выборках. И может быть очень разным для разных пар соседних элементов. Если сразу за конкретным элементом расположен следующий, а после него - большое расстояние, то этот первый элемент имеет очень мало шансов быть выбранным. И если распределение сгенерированных случайно ссылок на числовой оси более - менее равномерно, то вот расстояние между соседними элементами распределено неравномерно (кажется, по закону Пуассона или близкому к нему). Так что добиться равновероятности, не распределяя ссылки равномерно (что мы сделать не можем), не получится. Поэтому правильный алгоритм, видимо, вынужден быть линейным по времени - предусматривать обработку каждой ссылки. Или опираться на готовую сплошную нумерацию элементов.
Как-то так.
(100) ildarovich,
думаю, что все не так опасно, как кажется на первый взгляд. Я задумывался об этом при построении решения и вероятность того, что элементы окажутся "рядом" - также крайне мала. Неравномерность распределения обусловлена неравномерностью сгенерированых ГУИДов, а они друг от друга отстоят на расстояния несравнимые с количеством элементов даже в миллионных справочниках.
Это по началу в платформе 1С были трудности, связанные с индексированием ГУИДов и справочники заполненные скажем в 1С версии 8.0 (я точные номера версий не знаю) будут иметь ГУИДы из системы (хорошие и очень далекие друг от друга), потом (пусть "условно" в 8.1) 1С изменили поведение генерации ГУИДов, сделав их похожими друг на друга и расположив очень близко (у меня есть такие справочники, заполненные так, что на120 000 элементов в выборке 700 различных было всего 77 попутал, 77 различных было на справочнике в 752 элемента) я не уверен на все 100%, но в таких справочников ГУИД элемента делали из ГУИДа типа + максимум + 1 и индексироваться такие справочники стали веселей, но выглядели слишком грустно с точки зрения уникальности (тут, кстати, можно и конспирологию включить, на тему того, что заказчики хотели однозначной идентификации компьютера и ОС создавшей любой элемент любого справочника, или хотябы отсутствие повторов в принципе) и вот по результатам наблюдений я не вижу в 8.2 и в 8.3 общих частей у сгенерированных ГУИДов - похоже они (1С) решили проблнму индексации таких чисел и вернулись к системным ГУИДам, которые в свою очередь имеют прекрасное распределение (лучше чем многие "ГСЧ на коленке").
думаю, что все не так опасно, как кажется на первый взгляд. Я задумывался об этом при построении решения и вероятность того, что элементы окажутся "рядом" - также крайне мала. Неравномерность распределения обусловлена неравномерностью сгенерированых ГУИДов, а они друг от друга отстоят на расстояния несравнимые с количеством элементов даже в миллионных справочниках.
Это по началу в платформе 1С были трудности, связанные с индексированием ГУИДов и справочники заполненные скажем в 1С версии 8.0 (я точные номера версий не знаю) будут иметь ГУИДы из системы (хорошие и очень далекие друг от друга), потом (пусть "условно" в 8.1) 1С изменили поведение генерации ГУИДов, сделав их похожими друг на друга и расположив очень близко (у меня есть такие справочники, заполненные так, что на
(101) vugluscr1991, это я понимаю. Это технологические моменты. Я говорю уже о другом. Пусть ГУИДы идеальные. Они будут распределены равномерно. Но случайно! Между ними не будет одинакового расстояния! Оно будет тоже случайным и разным. Напимер, есть пять водителей (см.рисунок). Вместо ГУИД возьмем настоящее случайное число от 0 до 1 (функция СЛЧИС() EXCEL). Получается расстояние от ГУИДа водителя Бухарикова до ГУИДа Подкаблучникова таково, что первого будут проверять в ДВА РАЗА реже, чем второго, если для проверки перед рейсом выбирать водителя вашим методом. Если вы думаете, что когда водителей будет 200000 ситуация изменится - это не так. Расстояния будут микроскопические, но под микроскопом такими же разными. И вероятность проверки самого "везучего" по сравнению с самым "невезучим" будет еще сильнее отличаться.
Прикрепленные файлы:
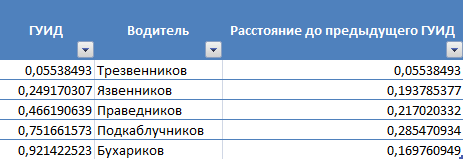
(102) ildarovich,
это именно так в теории вероятности, которая работает в предположениях закона больших чисел. А рабочими условиями закона больших чисел является не только мощность пространства событий (первое большое число), но и количество испытаний (практика, второе большое число). Я пишу о том, что в случае большого количества испытаний - Вы правы на все 100% будут "невезучие" водители, расположенные слишком близко к везучим. Но провести такое количество испытаний (мое предположение) Вы не в силах, если не будете создавать для этого специальную испытательную программу и подключать к этому вычислительные мощности. Ваши практические выборки имеют малое число испытаний (даже если это миллионы, ибо ГУИДы по разрядности значительно больше), поэтому элемент случайности на таких выборках реализован максимально.
Если же делать выборки в количестве годном к тому, чтобы считать его большим числом, тогда можно будет доказать "невезучесть" определенных водителей, но лишь в этих непрактических лабораторных условиях.
И вообще, на мой взгляд, если выборка равномерно закрывает пространство событий - то это повод для критики её случайности с философских позиций: глядя на процесс испытаний и зная, что ГСЧ идеален мы начинаем предсказывать заполнение пустых областей пространства событий результатами испытаний, а в идеально случайном процессе должен отсутствовать всякий детерминизм. Это означает, что кроме источника энтропии, должен быть также большой запас неопределенности. Что мы и имеем в результате малого количества испытаний в пространстве ГУИДов.
это именно так в теории вероятности, которая работает в предположениях закона больших чисел. А рабочими условиями закона больших чисел является не только мощность пространства событий (первое большое число), но и количество испытаний (практика, второе большое число). Я пишу о том, что в случае большого количества испытаний - Вы правы на все 100% будут "невезучие" водители, расположенные слишком близко к везучим. Но провести такое количество испытаний (мое предположение) Вы не в силах, если не будете создавать для этого специальную испытательную программу и подключать к этому вычислительные мощности. Ваши практические выборки имеют малое число испытаний (даже если это миллионы, ибо ГУИДы по разрядности значительно больше), поэтому элемент случайности на таких выборках реализован максимально.
Если же делать выборки в количестве годном к тому, чтобы считать его большим числом, тогда можно будет доказать "невезучесть" определенных водителей, но лишь в этих непрактических лабораторных условиях.
И вообще, на мой взгляд, если выборка равномерно закрывает пространство событий - то это повод для критики её случайности с философских позиций: глядя на процесс испытаний и зная, что ГСЧ идеален мы начинаем предсказывать заполнение пустых областей пространства событий результатами испытаний, а в идеально случайном процессе должен отсутствовать всякий детерминизм. Это означает, что кроме источника энтропии, должен быть также большой запас неопределенности. Что мы и имеем в результате малого количества испытаний в пространстве ГУИДов.
(103) vugluscr1991, конечно, в этом вопросе есть элемент "философии".
Но, прежде чем рассуждать философски, отмечу несколько фактических ошибок в ваших рассуждениях:
1) "Большое" количество испытаний при которым становится заметной неравномерность распределения, на самом деле не такое уж и большое. Оно никак не связано с разрядностью ГУИДов. А только с количеством элементов справочника. Например, для приведенного примера за год не должно встретится ни одного месяца, когда Подкаблучникова проверяли реже чем Бухарикова. Это означает, что мы просто зря тратили ресурсы на слишком частую проверку одного и того же человека (искали под фонарем). Это конкретные экономические потери. То есть порядок числа испытаний, при котором проявляется неравномерность - тот же, что и число элементов справочника.
Не знаю, какой формулой это доказать. Хотя ... , например: сколько нужно испытаний, чтобы с вероятностью больше 50% (другая цифра) хотя бы раз был выбран каждый элемент справочника. а) при методе, обеспечивающим равную вероятность выбора; б) при выборе отрезка между случайными ГУИДами. Формула будет зависеть только от числа элементов справочника и должна показать колоссальную разницу этих чисел. (чуть позже приведу)
2) А вот это просто заблуждение (распространенное)
Собственно, жестко спорить я не хочу. Метод имеет право на жизнь. Нужно только отчетливо представлять его недостатки. Кстати, при большом желании неравномерность распределения ведь можно и скорректировать, выбирая элементы "с запасом" и дополнительно отбирая их потом случайным образом с вероятностью, обратно пропорциональной (? - нужно еще уточнить) размеру отрезка между ГУИДами. Проблема только в определении величины этого запаса. Поэтому все же лучше будет выбирать по одному.
Но, прежде чем рассуждать философски, отмечу несколько фактических ошибок в ваших рассуждениях:
1) "Большое" количество испытаний при которым становится заметной неравномерность распределения, на самом деле не такое уж и большое. Оно никак не связано с разрядностью ГУИДов. А только с количеством элементов справочника. Например, для приведенного примера за год не должно встретится ни одного месяца, когда Подкаблучникова проверяли реже чем Бухарикова. Это означает, что мы просто зря тратили ресурсы на слишком частую проверку одного и того же человека (искали под фонарем). Это конкретные экономические потери. То есть порядок числа испытаний, при котором проявляется неравномерность - тот же, что и число элементов справочника.
Не знаю, какой формулой это доказать. Хотя ... , например: сколько нужно испытаний, чтобы с вероятностью больше 50% (другая цифра) хотя бы раз был выбран каждый элемент справочника. а) при методе, обеспечивающим равную вероятность выбора; б) при выборе отрезка между случайными ГУИДами. Формула будет зависеть только от числа элементов справочника и должна показать колоссальную разницу этих чисел. (чуть позже приведу)
2) А вот это просто заблуждение (распространенное)
выборка равномерно закрывает пространство событий - то это повод для критики её случайности с философских позиций: глядя на процесс испытаний и зная, что ГСЧ идеален мы начинаем предсказывать заполнение пустых областей пространства событий результатами испытаний, а в идеально случайном процессе должен отсутствовать всякий детерминизм. Это означает, что кроме источника энтропии, должен быть также большой запас неопределенности
Люди, знающие теорию вероятностей, знают, что при независимости испытаний то, что монетка 20 раз подряд выпадет одной стороной, не означает, что это изменит ее вероятность выпасть той же стороной в следующем испытании. Они не начинают так предсказывать. Следующий результат с независимой вероятностью попадет в пустую или занятую область. Это - азбука! Энтропия и неопределенность - синонимы.
Собственно, жестко спорить я не хочу. Метод имеет право на жизнь. Нужно только отчетливо представлять его недостатки. Кстати, при большом желании неравномерность распределения ведь можно и скорректировать, выбирая элементы "с запасом" и дополнительно отбирая их потом случайным образом с вероятностью, обратно пропорциональной (? - нужно еще уточнить) размеру отрезка между ГУИДами. Проблема только в определении величины этого запаса. Поэтому все же лучше будет выбирать по одному.
(104) ildarovich,
да заблуждение распространенное, но именно такого я не писал, я писал о практической разности энтропии (как характеристики исходных данных для испытаний) с неопределенностью испытаний, которые должны произойти в будущем до получения их большого числа.
"20 раз подряд орел" - это не заблуждение, а оговорка (исходя из контекста высказывания), когда не верно говорят о вероятности следующей решки, оперируя при этом понятием математическим "вероятность" и имея в виду ожидание (не математическое, а азартно-практическое) этого исхода (решки). Даже профессиональные математики путают термины и контексты, чего же мы хотим от людей не имеющих в активном аппарате точных определений.
Я тоже пишу не с целью спорить, просто делюсь своим видением случайности: если Бухарикова не будут проверять из-за короткого интервала между ГУИДами - это и есть случайность, а если идеальный ГСП равномерно закрасит нам квадрат (1,1) - это предопределено.
что монетка 20 раз подряд выпадет одной стороной ...
да заблуждение распространенное, но именно такого я не писал, я писал о практической разности энтропии (как характеристики исходных данных для испытаний) с неопределенностью испытаний, которые должны произойти в будущем до получения их большого числа.
"20 раз подряд орел" - это не заблуждение, а оговорка (исходя из контекста высказывания), когда не верно говорят о вероятности следующей решки, оперируя при этом понятием математическим "вероятность" и имея в виду ожидание (не математическое, а азартно-практическое) этого исхода (решки). Даже профессиональные математики путают термины и контексты, чего же мы хотим от людей не имеющих в активном аппарате точных определений.
Я тоже пишу не с целью спорить, просто делюсь своим видением случайности: если Бухарикова не будут проверять из-за короткого интервала между ГУИДами - это и есть случайность, а если идеальный ГСП равномерно закрасит нам квадрат (1,1) - это предопределено.
(105) vugluscr1991, спасибо, теперь я лучше понял вашу мысль. Кажется, вы считаете, что выбор будет более случайным (по настоящему случайным), если мы сначала случайно выберем закон распределения, а потом, в соответствии с этим случайным законом - само случайное число. Не согласен с этим. В теории информации есть четкая количественная мера случайности (неопределенности, энтропии) - это Сумма(Pj*log(Pj)). Она максимальна при равной вероятности исходов P1 = P2 = ... = Pn. И никакое дополнительное услучайнивание здесь не поможет.
С чем я соглашусь, так это с тем, что для конкретной одной проверки можно выбирать объект хоть считая число согласных в его фамилии, хоть число лепестков на ромашке.
Но как только вы встроете этот механизм в тиражное решение, которым пользуются тысячи предприятий, тут и проявится методологическая ошибка метода. У вас на выявление одного нетрезвого водителя будет уходить 1000 рублей, к примеру. А у конкурентов, пользующихся в своем программном продукте правильной (научно обоснованной) стратегией - 500. Разница есть.
При этом до сих пор мы говорили об "играх с природой" (есть такой термин в теории статистических решений), то есть предполагалась не заинтересованность "противника". Если же говорить об играх с противоположными интересами (с нулевой суммой): о борьбе с несунами, об игре против казино, то там проигрыш будет более резким. Несуны быстро соберут статистику и и поймут, кого проверяют чаще, чтобы с большей выгодой для себя распределять (также рандомизированно) нелегальный груз между собой. Или в казино ставить на чаще выпадающее число.
Кстати, говорят, есть программа, которая определяет (в зависимости от содержания сопроводительных документов) будет ли открываться и проверяться конкретная фура таможенниками. Интересно, есть ли там рандомизация и правильная ли она?
С чем я соглашусь, так это с тем, что для конкретной одной проверки можно выбирать объект хоть считая число согласных в его фамилии, хоть число лепестков на ромашке.
Но как только вы встроете этот механизм в тиражное решение, которым пользуются тысячи предприятий, тут и проявится методологическая ошибка метода. У вас на выявление одного нетрезвого водителя будет уходить 1000 рублей, к примеру. А у конкурентов, пользующихся в своем программном продукте правильной (научно обоснованной) стратегией - 500. Разница есть.
При этом до сих пор мы говорили об "играх с природой" (есть такой термин в теории статистических решений), то есть предполагалась не заинтересованность "противника". Если же говорить об играх с противоположными интересами (с нулевой суммой): о борьбе с несунами, об игре против казино, то там проигрыш будет более резким. Несуны быстро соберут статистику и и поймут, кого проверяют чаще, чтобы с большей выгодой для себя распределять (также рандомизированно) нелегальный груз между собой. Или в казино ставить на чаще выпадающее число.
Кстати, говорят, есть программа, которая определяет (в зависимости от содержания сопроводительных документов) будет ли открываться и проверяться конкретная фура таможенниками. Интересно, есть ли там рандомизация и правильная ли она?
Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот