Как узнать из-за чего отъедает столько памяти?
Столкнулся с тем что РПхост на пару с СКУЛЬ-сервантом отъели всю память. Почти 48 гигов. Не знаю, как определить причину такого поведения. На все что хватило мозгов - это запустить счетчик в консоли администрирования сервера 1С. Но по счетчику видно, что отъедается якобы около 5 гигов. Не подскажите как можно диагностировать утечку?
Прикрепленные файлы:



Ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
(1)
Что можно сделать:
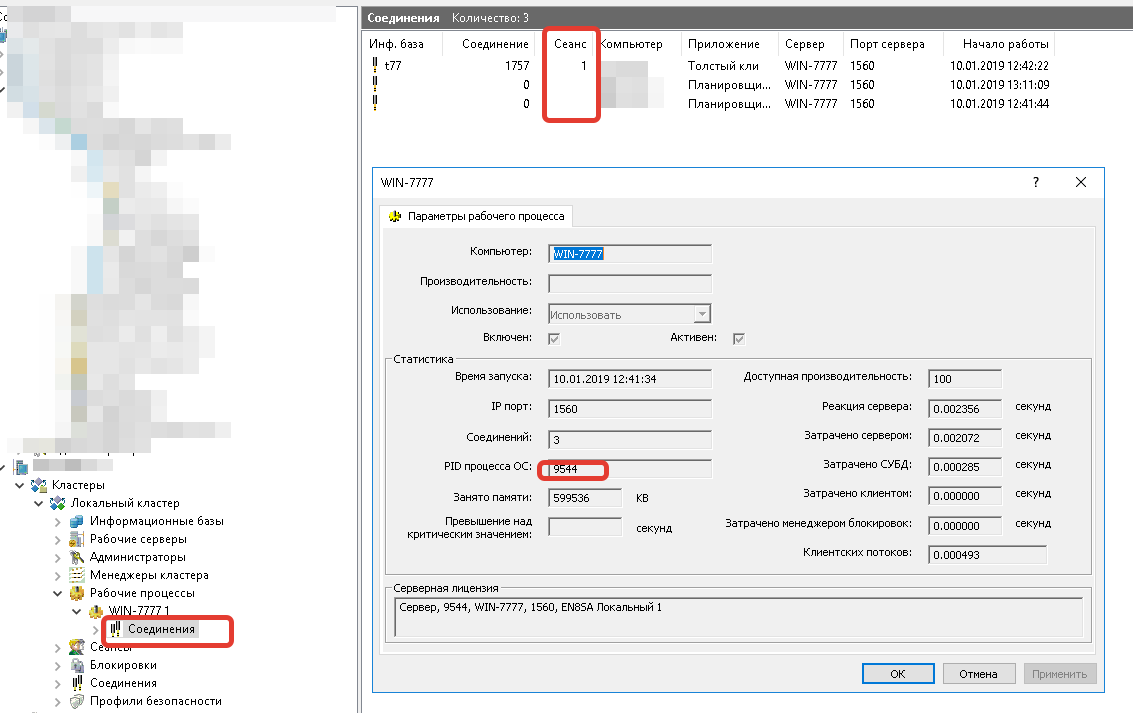
В диспетчере задач посмотреть ИД процесса рпхост.
По ИД найти рабочий процесс, соответствующий рпхосту.
В соединениях посмотреть номера сеансов.
А зная номер сеанса, можно проанализировать текущие сеансы в консоли, либо журнал регистрации в конкретной базе.
Не подскажите как можно диагностировать утечку?
Что можно сделать:
В диспетчере задач посмотреть ИД процесса рпхост.
По ИД найти рабочий процесс, соответствующий рпхосту.
В соединениях посмотреть номера сеансов.
А зная номер сеанса, можно проанализировать текущие сеансы в консоли, либо журнал регистрации в конкретной базе.
Прикрепленные файлы:

(19) К сожалению, не обратил внимание, что в "сеансах" отображается такая развернутая аналитика. Возможно там что-то бы и показало. Но посмотреть уже не могу - "решил" вопрос (возможно временно) перезагрузив сервер. На будущее, если столкнусь с подобным снова, буду иметь ввиду. спасибо!
(20) Ага. В консоли видно практически все, что нужно для оперативного исправления ситуации.
Плюс еще журнал регистрации, чтобы понять, например, что пользователь запустил какой-то отчет, потом ему надоело ждать, он снял через диспетчер задач процесс 1С и заново зашел.
А отчет все формируется и формируется, сервак чето тормозит.
И никто ничего не делает уже, ни у кого ничего не запущено, а сервак тормозит.
С одним рабочим процессом конечно проще.
Но с несколькими устойчивее ситуация получается.
Если надо грохнуть уже сам процесс рпхоста на сервере, то с одним рабочим процессом отвалятся все. А с несколькими только те, кто на этом рабочем процессе висит.
Т.е. негатива от пользователей будет меньше.
Плюс еще журнал регистрации, чтобы понять, например, что пользователь запустил какой-то отчет, потом ему надоело ждать, он снял через диспетчер задач процесс 1С и заново зашел.
А отчет все формируется и формируется, сервак чето тормозит.
И никто ничего не делает уже, ни у кого ничего не запущено, а сервак тормозит.
С одним рабочим процессом конечно проще.
Но с несколькими устойчивее ситуация получается.
Если надо грохнуть уже сам процесс рпхоста на сервере, то с одним рабочим процессом отвалятся все. А с несколькими только те, кто на этом рабочем процессе висит.
Т.е. негатива от пользователей будет меньше.
(1)
Попробуйте в счетчике администрирования поставить другую длительность сбора, сейчас у Вас - "серверный вызов", можно поставить, к примеру - 7200000 (это два часа) . Так Вы увидите другую картину и это может натолкнет на мысли о коварном пользователе или фоновом задании )
чик в консоли администрирования сервера 1С. Но по счетчику видно, что отъедается якобы около 5 гигов. Не подскажите как можно диагностировать утечку?
Попробуйте в счетчике администрирования поставить другую длительность сбора, сейчас у Вас - "серверный вызов", можно поставить, к примеру - 7200000 (это два часа) . Так Вы увидите другую картину и это может натолкнет на мысли о коварном пользователе или фоновом задании )
Прикрепленные файлы:


(13) Да, можно. Штатный перезапуск рабочего процесса выглядит как создание нового, перенос сеансов и убитие старого. Бывали случаи, когда при настроенном регламентном перезапуске и проблемами с переносом сеансов рабочие процессы плодились в неприличных количествах :) Не за один день, ессно.
(13)Главное чтобы бекап был настроен и работал. А то тут сегодня была тема где УПП с РИБ год без бекапа крутилась и докрутилась в итоге... :) А так да, переход с одного рабочего процесса на другой автоматизирован, но контроль за сервером и его самостоятельностью в любом случае должен быть (это к (14)).
(5) Попробуйте включить в опциях кластера выделять под каждую базу отдельный rphost. Несмотря на некоторый перерасход памяти будет легче мониторить проблемные ситуации. Они хотя бы будут разделены по базам. Это можно делать "на лету". Менеджер кластера попробует перераспределить сессии на новые rphost. Если есть проблемные сессии, это скоро станет очевидным. В конце концов проблемный rphost можно будет прибить руками и это не затронет сессии на других процессах. Желательно только обеспечить некоторый запас свободной памяти перед такой операцией. Ну, заставить скуль чуток отдать, например.
Одна умная тетенька, по совместительству работающая консультантом в Microsoft по вопросам SQL говорила на занятиях - "Сколько памяти не дай SQL серверу - он все сожрет" Но так же она говорила про то что если SQL не задействует какой либо объем памяти очень долго - то он должен ее освобождать. Что собственно на практике замечено небыло :). Поэтому при настройке SQL надо указывать сколько максимально ему можно жрать памяти.
Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот