






Исходные данные:
Конфигурация: Розница 2.2
Платформа 1С: 8.3.7.1970
Ориентировочное число узлов в конце проекта: 200
Ресурсы оборудования в центре: без существенных ограничений
Оборудование на точке: обсуждаемый вопрос.
Срок проекта: год.
Архитектура:
Сперва определились со схемой РИБ. Было принято решение ориентироваться на схему "звезда", пока это будет возможно; при достижении технологических ограничений - снежинка.
В торговых точках используется клиент-серверный вариант работы, с выделенным сервером, под управлением ОС Windows.
Сервер 1С будет использован в варианте "Сервер 1С МИНИ" https://1c.ru/news/info.jsp?id=17577
Сервер СУБД - MS SQL Express 2008 R2.
SQL Express 2008 R2 - последняя на текущий момент времени версия данной линейки SQL Server.
Ограничния:
- 2 ГБ ОЗУ
- 1 физический процессор
- 10 ГБ максимальный объём базы
Из всего вышеперечисленного напрягает в осном ограничение на максимальный объём БД.
Но это всего лишь означает, что нужно гработно организовать процедуру её очистки от устаревших данных на местах.
Под сервер 1С и MS SQL выделяется отдельный физичский сервер. На него будет ложиться основная нагрузка по обменам и проведению длительных операций.
Конечные клиентские компьютеры не заменяются, потому как будут работать с тонким клиентом и нагрузка на них будет минимальной.
Сервер в магазине - просто мощьный ПК. Но обязательным условием является наличие диска SSD - на котором расположены базы MS SQL.
Также сервер будет обсепечивать возможность проведения регламентных операций в ночное время и доступ к базе магазина без отрыва от работы.
Основные настройки
Со времен УТ 10.3, на которой у меня состоялся первый проект внедрения РИБ на 60 узлов, конечно, "утекло много воды".
1С не стояли на месте. Розница 2.2 теперь учитывает необходимость выборочной выгрузки данных.
В базу магазина будет выгружаться только та информация, которая имеет к нему отношение:
- Все справочники (кроме специализированных)
- Документы по данному магазину
Регистрация данных происходит по правилам регистрации, всё что можно кэшируется. Существенных замедлений именно на регистрации не наблюдается.
Другой вопрос, что так или иначе добавление узла в базу означает добавление ещё одной записи в таблицу регистрации на каждый общий элемент при его записи.
В настройке самой выгрузки ничего специфичного нет. Есть некоторые нюансы при настройке сценариев синхронизации:
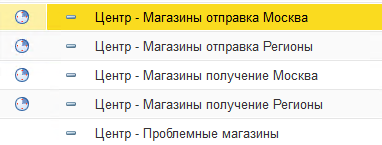
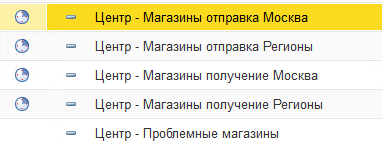
1) Нужно разделить на отдельные сценарии синхронизации на выгрузку и загрузку
Смысл в том, что выгрузка проходит долго и с блокировками, а загрузка достаточно беспроблемно. При этом часто бывает что данные нам нужно оперативно получать из розничных точек, отдавая при этом только несколько раз в день.
2) Выделить проблемные магазины и убрать их из общего сценария синхронизации. На них могут быть большие выгрузки - тормозиться при этом будет весь обмен, включая другие узлы. После решения проблем они доабвляются обратно
3) Создать несколько сценариев отправки и получения данных. Но тут главное поймать правильный баланс их количества.
Некоторые вещи в 1С не меняются. Тот самый метод "ВыбратьИзменения" может выполняться только последовательно (ещё с версии 8.1).
Следовательно, параллельность в выгрузке РИБ ограничена. На практике получается запускать параллельно 2-3 сценария.
Что касается сценариве получения - тут возможна куда большая параллельность, если нужна, конечно.
Что пришлось доработать
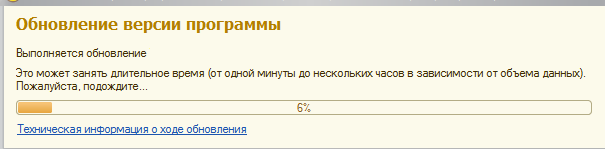
Конечно, грустно и печально, но пришлось основательно влазить в БСП. Самый главный косяк в штатной логике 1С РИБ - это обновления. После обновления появляется примерно такое окошко:

Это всё происходит в монопольном режиме. Кроме всего прочего, система ещё будет пытаться сделать обмен после обновления в монопольном режиме. К чему это все приводит - нетрудно догадаться.
Весь этот период времени магазин не может работать, на кассе стоят покупатели, компания теряет деньги.
Ещё одной проблемой обмена становятся регистры сведений. Выгрузка в XML каждой записи регистра сведений создаёт отдельный узел XML со служебными элементами и т.п.. Кроме того, функция "ВыбратьИзменений()" для регистра сведений в котором 100 записей получит результирующую таблицу в 100 строк, в то же время, есдли это справочник у которого 100 строк в табличной части выберется только одна запись. А это время монопольной блокировки. Так что если в РС много записей, которые регулярно регистрируются к обмену в другие магазины, то это, конечно, правильнее представить в виде справочника с табличной частью, который в крайнем случае при записи может формировать строки этого же регистра. В любом случае, регистры сведений в обменах - это зло.
Ещё одна важная деталь - из обмена польностью исключены дисконтные карты, а физлица - только сотрудники конкретного магазина. Зачем? Дисконтных карт скопилось уже близко к 3 млн. Для работы с ними используется внешняя online система. Если продолжать передавать дисконтные карты на все магазины - это в разы увеличит обмены, кроме того, может привести к превышению базой объёма в 10 ГБ.
Часть механизмов реализована online обращением в центральную базу: остатки в других магазинах, возврат по чеку из другого магазина, проверка валидности подарочного сертификата.
Тиражирование
Конечно, тиражирование ведётся ускоренными темпами.
Создание начального узла РИБ штатным образом сделало бы невозможным тиражирование в принципе.
Поэтому новый узел создаётся следующим образом:
1) Существует отдельная база с фейковым магазином
2) Эта база обменивается в РИБ всеми общими данными но не получает специализированных (документов)
3) Когда хотим создать новую базу - просто копируем эту
4) Потом устанавливаем настройки - магазин, префикс и т.п.
5) База для магазина готова.
На сервер разворачивается уже готовый пакет ПО, поэтому много врмени это не занимает. Потом на сервер заливается вновь созданная база, и он готов для отправки в магазин.
Преимущества тонкого клиента
Два существенных преимущества Розницы 2.2 (Тонкого клиента) которые "согрели душу":
1) Нет необходимости менять весь компьютерный парк в торговых точках. 90% операций выполяется на сервере, а сервер туда привозится "относительно мощный компьютер"
2) Техника имеет свойство отказываться работать, особенно часто это происходит с вновь установленным или уже изношенным оборудованием.
В этом случае действия теперь предельно просты - магазин переключается на работу в центральной базе.
Этот процесс занимает не более 5-10 минут, таким образом торговля не прерывается даже при существенных проблемах с оборудованием.
Поддержка и обновления
Наконец, дошли до самого интересного пункта - как же всё это поддерживать и обновлять?
Для нас обновления тоже долгое время были дилеммой:
1) Обновлять руками магазинов (не очень правильно, могут не получить изменения, будут звонки и проблемы) - так было ранее
2) Обновлять силами технической поддержки (нет столько ресурсов)
3) Написать *.cmd или 1С скрипт для обновления или взять готовый. Как показывает практика, такое решение всегда половинчатое (нестабильное ), а функциональности в нём получится заложить немного.
Какие у нас были задачи:
1) Обновление должно проходить в нескольких режимах и управляться централизованно
2) При обновлении возможно интерактивное взаимодействие с пользователем (сообщения, подтверждение, прогресс бар).
3) Обязательно должны приходить отчеты о состоянии и ошибках обновления
4) Должно быть резервное копирование
5) Система обновления должна уметь без проблем обновлять саму себя.
6) Система должна быть расширяема без особых проблем.
Конечно, задачи вышли далеко за перечень решаемых простыми методами. Поскольку без автоматизации с таким количеством конечных точек не обойтись, а ничего более-менее готового со схожим функционалом мы не нашли, пришлось заняться разработкой ПО, которое со временем приобрело название MU (MagicUpdater).
Основные функции:
1) Динамическое обновление базы (команда или по расписанию)
2) Статическое обнволение базы (команда или по расписанию)
3) автоматическое агентов на конечных компьютерах при их модификации
4) Проверка состояния агентов
5) Отчеты об обновлениях
6) резервное копирование
7) Административные действия с сервером 1C и MS SQL
8) Закрытие всех клиентских приложений 1С на компьютерах сети
9) Статическое обновление с акцептом на главной кассе
10) Отображение описания модификаций после обновления
11) Настройка порядка действий
12) Выполнение всех этих действий по расписанию
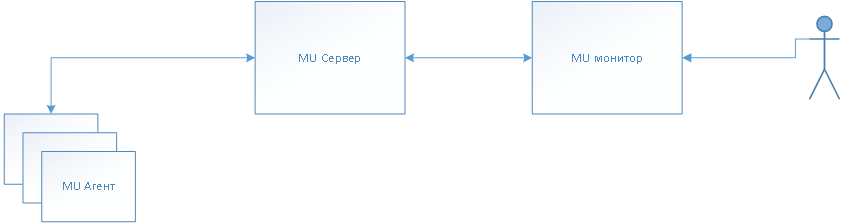
Примерная схем взаимодейтсвия:

Где MU Агент - это служба, устанавливается и настраивается в магазине. Собственно, она с центра получает команда на выполнение определенных дланных.
MU Сервер - Сервер, который принимает все запросы к системе.
MU монитор - то, что видят рядовые сотрудники технической поддержки - используется для просмотра логов и постановки заданий на обновление, либо прочих.
Получилось весьма неплохо, на мой взгляд. Теперь обновления проходят практически в автоматическом режиме.
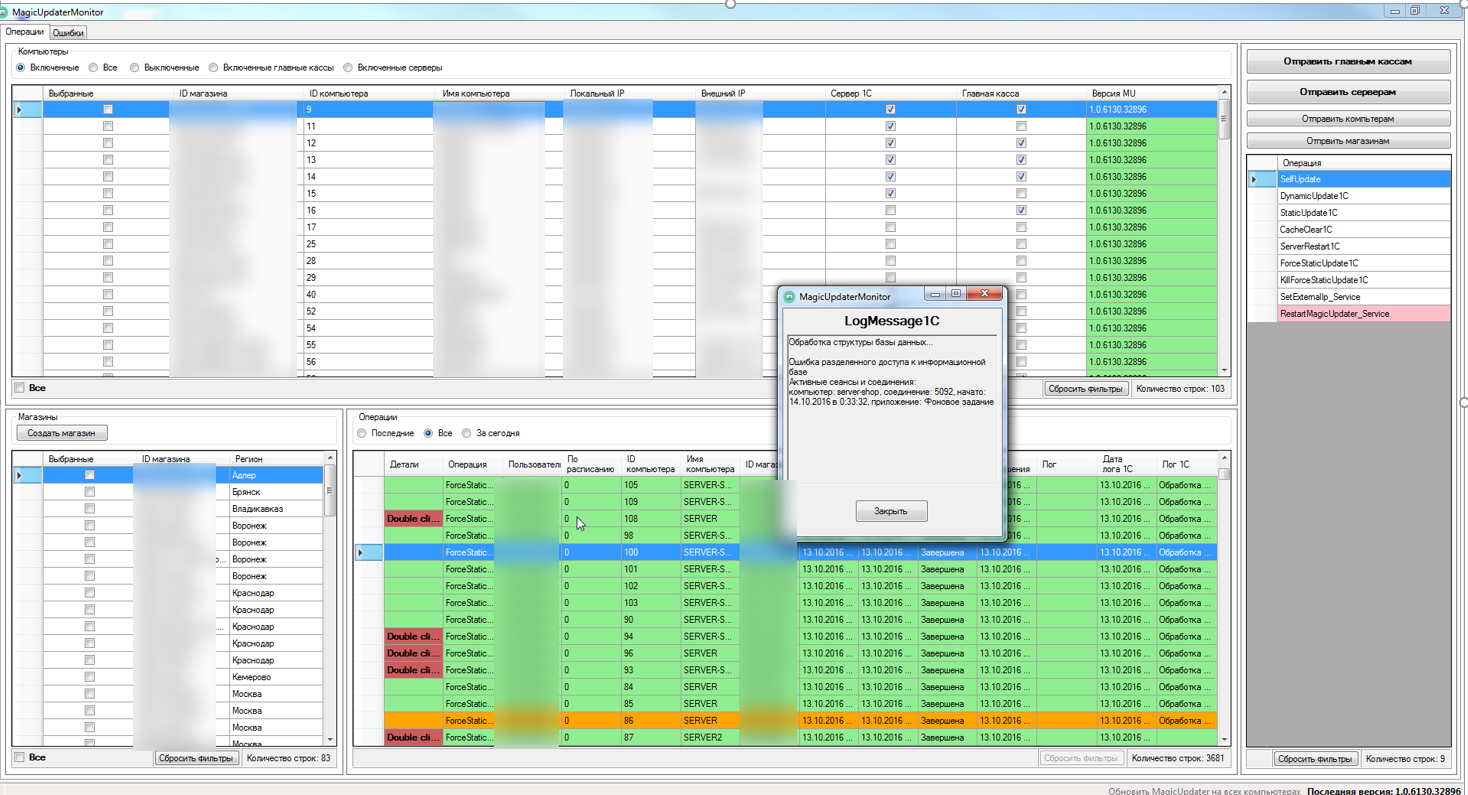
Вот так, к примеру, выглядит сообщение об ошибке после обновления:

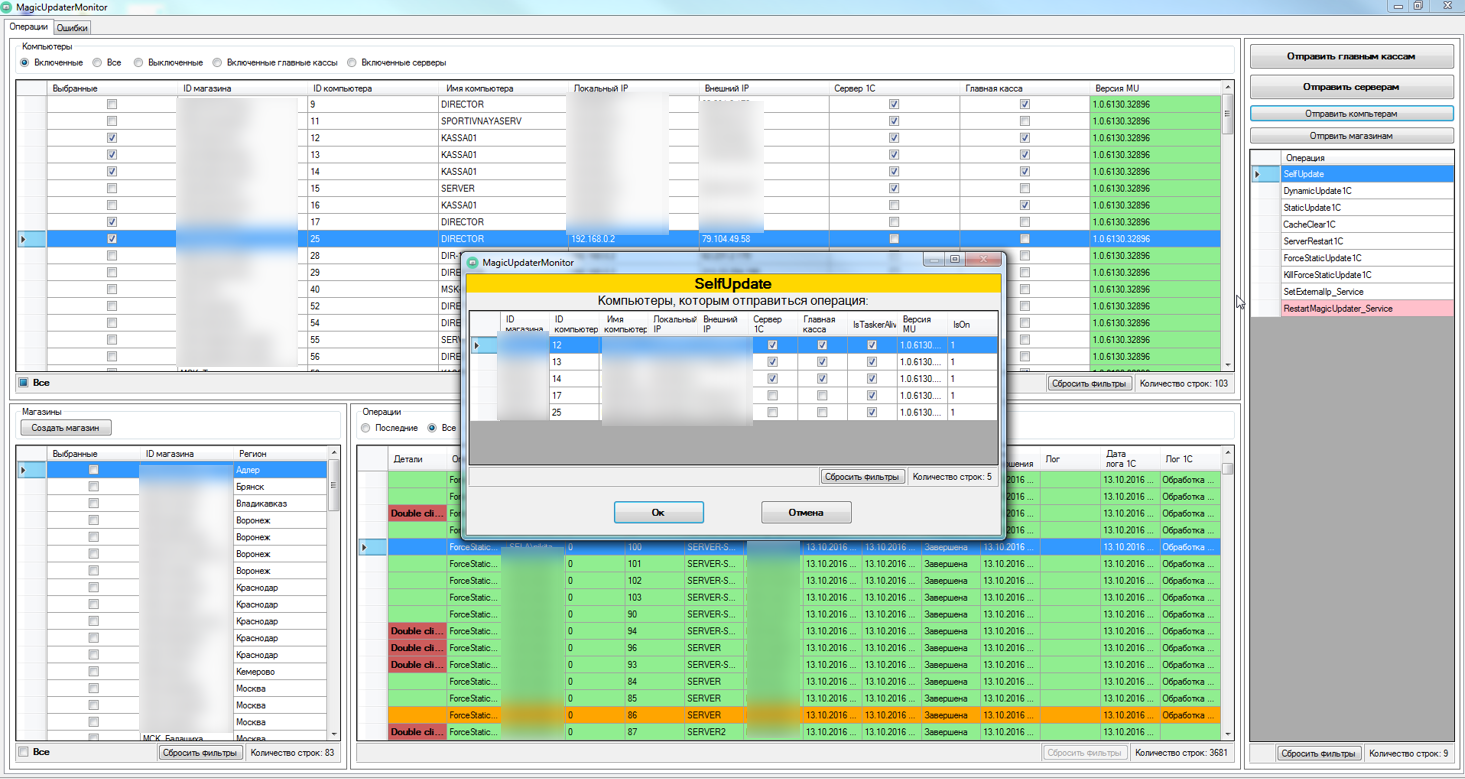
А вот таким образом мы осуществляем отправку команд на клиентские компьютеры
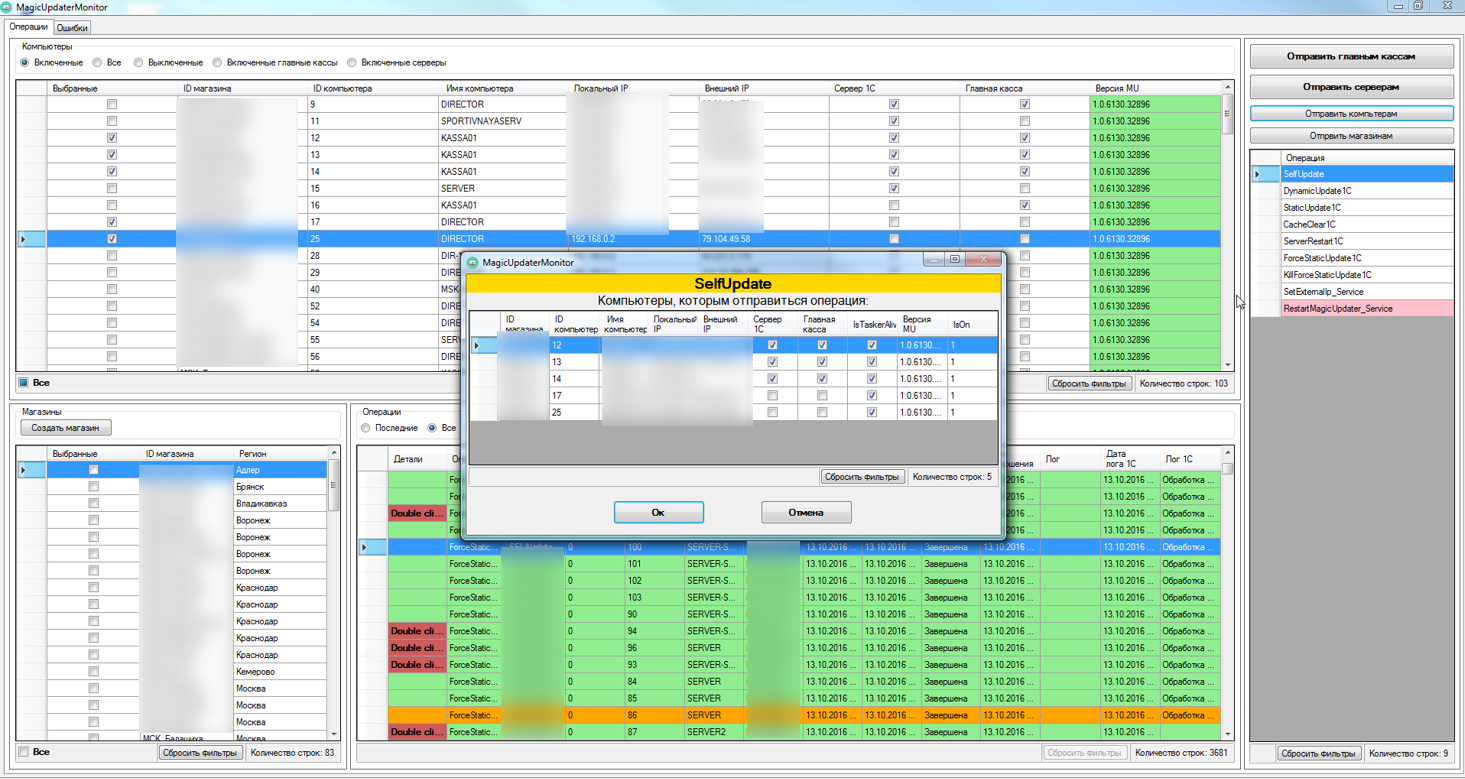
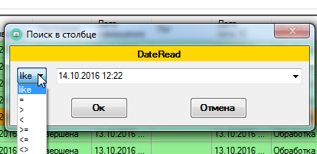
Приложения, конечно, не 1С-ные, но с достаточно приличным набором интерфейсных возможностей. Вот так, к примеру, выглядит отбор по дате:
Таким образом, у проекта появились неплохие шансы быть завершенным успешно. По крайней мере, на середине пути "полёт нормальный".
Если придём ещё к каким-либо решениям, которые могут показаться интересными, напишу отдельно.
P.S. и самое главное: Правильное планирование дальнейшей поддержки - один из ключевых факторов дальнейшего успеха подобных проектов. :)






{kind=link}