Непонимание причины тормозящего запроса к списку документов. Индексы
Есть база 1C самописная на MS SQL 2019 (Windows x64). Есть документы Заявка. В базе сейчас примерно 24 млн. шт.
Есть форма списка документов, простой запрос с отбором в динамическом списке (динамическое считывание отключено или включено - один итог):
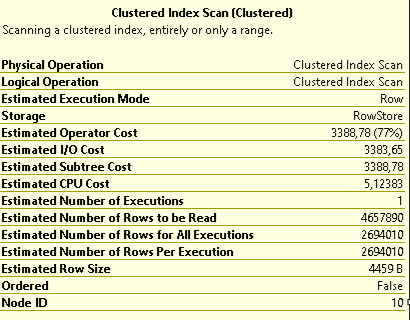
И вот в плане запроса всегда Clustered Index Scan по индексу [PK___Documen__AC8ED0C4EFF44EB5] с десятками миллионов Logical Reads/sec на каждое действие с формой списка Заявок.
SEL ECT TOP 1000
T1._IDRRef,
T1._Marked,
T1._Number,
T1._Date_Time,
T1._Posted,
T1._Fld3036
FR OM dbo._Document3004 T1
WHERE (T1._Fld3972 = 0x00) AND T1._Posted = 0x01 AND T1._Fld3263 = 0x01 AND (T1._Date_Time >= @P6)
Прошу подсказать, куда копать или что можно сделать?
Есть форма списка документов, простой запрос с отбором в динамическом списке (динамическое считывание отключено или включено - один итог):
ВЫБРАТЬ
ДокументЗаявка.Ссылка КАК Ссылка,
ДокументЗаявка.ПометкаУдаления КАК ПометкаУдаления,
ДокументЗаявка.Номер КАК Номер,
ДокументЗаявка.Дата КАК Дата,
ДокументЗаявка.Клиент КАК Клиент,
ИЗ
Документ.ДокументЗаявкаКАК ДокументЗаявка
ГДЕ
НЕ ДокументЗаявка.Тестовая
И ДокументЗаявка.Проведен
И ДокументЗаявка.Утвержден
И ДокументЗаявка.Дата >= ДАТАВРЕМЯ(2023, 1, 1)
ПоказатьИ вот в плане запроса всегда Clustered Index Scan по индексу [PK___Documen__AC8ED0C4EFF44EB5] с десятками миллионов Logical Reads/sec на каждое действие с формой списка Заявок.
SEL ECT TOP 1000
T1._IDRRef,
T1._Marked,
T1._Number,
T1._Date_Time,
T1._Posted,
T1._Fld3036
FR OM dbo._Document3004 T1
WHERE (T1._Fld3972 = 0x00) AND T1._Posted = 0x01 AND T1._Fld3263 = 0x01 AND (T1._Date_Time >= @P6)
Прошу подсказать, куда копать или что можно сделать?
Прикрепленные файлы:

Ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
(1)Кластерный индекс по каким полям построен?
Если типовой, то он только по дате, т.к. у вас отбор c ">=" + поля, не входящие в поля кластерного индекса, то вы и получите сканирование.
чтобы указанный запрос отрабатывал быстро, нужно строить кластерный индекс по всем полям из отбора в той последовательности, которая в отборе, либо поля в отборе расположить в такой же последовательности, что и в кластерном индексе.
Если типовой, то он только по дате, т.к. у вас отбор c ">=" + поля, не входящие в поля кластерного индекса, то вы и получите сканирование.
чтобы указанный запрос отрабатывал быстро, нужно строить кластерный индекс по всем полям из отбора в той последовательности, которая в отборе, либо поля в отборе расположить в такой же последовательности, что и в кластерном индексе.
(2)
Не "порите" чушь, в худшем случае получится KeyLookUp, который в данном случае оказывается просто "дороже" сканирования.
(2)
Откуда вы это берёте эту "дичь" :)
Порядок предикатов в запросе может быть ЛЮБЫМ.
Как поля в индексе надо располагать это отдельный вопрос, для "сферического коня" поля располагаются от самого селективного к не селективным.
2efin
1. DDL кластерного индекса в студию.
2. Статистику обновите на таблице dbo._Document3004 T1.
3. План запроса не ожидаемый, а реальный.
4. Если очень хочется, то создайте фильтрованный индекс а-ля
т.к. у вас отбор c ">=" + поля, не входящие в поля кластерного индекса, то вы и получите сканирование.
Не "порите" чушь, в худшем случае получится KeyLookUp, который в данном случае оказывается просто "дороже" сканирования.
(2)
нужно строить кластерный индекс по всем полям из отбора в той последовательности, которая в отборе, либо поля в отборе расположить в такой же последовательности, что и в кластерном индексе.
Откуда вы это берёте эту "дичь" :)
Порядок предикатов в запросе может быть ЛЮБЫМ.
Как поля в индексе надо располагать это отдельный вопрос, для "сферического коня" поля располагаются от самого селективного к не селективным.
2efin
1. DDL кластерного индекса в студию.
2. Статистику обновите на таблице dbo._Document3004 T1.
3. План запроса не ожидаемый, а реальный.
4. Если очень хочется, то создайте фильтрованный индекс а-ля
cre ate index _idx on dbo._Document3004 (_Date_Time ) where (T1._Fld3972 = 0x00) AND T1._Posted = 0x01 AND T1._Fld3263 = 0x01
include (
_IDRRef,
_Marked,
_Number,
_Posted,
_Fld3036)
Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот