Проблема
В разгар перехода на PostgreSQL (далее PG) к нам обратились коллеги из отдела развития информационных систем собственных производств за решением распространенной проблемы: в ERP «Закрытие месяца» на MSSQL идёт 2 часа, а на PG — 11 часов. Требовалось сократить этот срок хотя бы до 3 часов. К слову, все зависало на конкретном пункте: «Распределение затрат и расчет себестоимости».
Конфигурация 1С:ERP Агропромышленный комплекс 2 (2.5.8), полностью на поддержке, расширения хоть и были, но закрытие месяца не затрагивали. Сервер PG 14.5.3 x64 скачан с сайта 1С, установлен на linux сервер под CentOS 7 (CPU 8 ядер, ОЗУ 64ГБ). Версия сервера 1С 8.3.21.1393 x64. Размер базы около 90ГБ.
Обновление до последнего релиза не исправило ситуацию, поэтому приступили непосредственно к анализу и разбору.
Для начала решили обойтись техжурналом и найти контекст, где именно возникает проблема. И так как по симптомам явно какие-то запросы начали выполняться очень долго, настроили техжурнал от 10 мин, чтобы не разбирать ненужную мелочевку.
Перед запуском закрытия месяца для базы был выполнен необходимый регламент: Vacuum, Analyze, Freeze. В дальнейшем он будет повторяться перед каждым тестом в обязательном порядке.
Техжурнал показал интересную картину. Обнаружили 3 запроса, которые выполнялись по 2.5 - 3 часа.

2 запроса — дубль одного и того же.
Проблемные запросы находятся в следующих местах:
- РасчетСебестоимостиКорректировкаСтоимости.ТекстСуммыПрочихРасходов
- РасчетСебестоимостиРешениеСЛУ.ТекстВтТаблицаСвязейПостатейныеРасходы
Первым делом под подозрение попал PG и linux сервер, на котором он установлен. Linux и сам PG были настроены по всем известным рекомендациям. Всё перепроверили, ошибок не нашли. Далее обратились за помощью в корпподдержку 1С — рекомендовали поиграться с default_statistics_target (количество записей, просматриваемых при сборе статистики по таблицам). Увеличив дефолтный параметр со 100 до 1000, не получили положительных изменений. И если при значении 100, первый проблемный запрос появлялся где-то через 20 минут от начала расчета себестоимости, причем всегда и при любых тестах, то со значением 1000 это время возросло до 40 минут. Явно сказывается расчет статистики на временных таблицах. Увеличивать его смысла уже не было, даже 1000 точно не будем ставить при таких просадках.
Так как простые методы не помогали, и явно под подозрением уже были сами запросы, то захотелось посмотреть на планы.
Это был первый серьезный опыт решения подобных проблем, так как процесс перехода на PG был только в начальной стадии и пока не приходилось ни анализировать долгие запросы PG, ни снимать планы PG, разве что только в теории)
Auto_explain
Для снятия плана воспользовались стандартной библиотекой auto_explain. Почему-то считали, что это будет так же просто и легко, как в MSSQL, но нас поджидал сюрприз.
Нет никаких отборов, кроме длительности запросов. Даже по имени базы. Это, мягко говоря, немного шокировало. Отбор по базе казался, ну как бы, настолько очевидным, что когда его тут не обнаружилось, то решили, что, наверное, не та библиотека, ну или делаем что-то не то. Но, увы, все так. А если это общий сервер для тестирования и там много баз? По ним всем собирать все запросы, серьезно?
И как следствие, это получение планов уже оптимизированных запросов, которые могут выполняться достаточно быстро, и отбор по длительности придется отключить для получения всего и вся со всех баз. При этом включение и отключение отбора делается настройками (ALTER SYSTEM SET…), и тут главное — не забыть все вернуть обратно.
Нам, конечно, немного повезло: запросы были длительные, сервер специально выделили для разбора этой проблемы. Получить все, что нужно, сможем, но все равно такая ситуация немного омрачала, и в первую очередь, для расследования будущих проблем, где не будет таких идеальных условий.
Но была одна особенность, которую мы не брали в расчет, да и не сразу к этому пришли: все это был open source. А значит можно не только заглянуть под капот, но внести изменения, дописать, переписать и т. д.
В таком ключе никогда не подходили к решению проблем, как-то всегда было уже обкатано, и если чего-то нет или нельзя, то значит нельзя.
Естественно, из любопытства пошли смотреть на код auto_explain. Он входит в состав официального дистрибутива, который можно скачать с сайта PG (https://www.postgresql.org).
Весь код был в одном файле-модуле auto_explain.c, открыв который, увидели всего около 500 строк кода, где большая часть — это инициализация и подготовка, а основная логика — 70 строк. И это все? Ну как бы привыкли к многотысячным модулям в 1С, но тут все казалось уж слишком простым. Модуль написан на языке СИ, опыта работы с ним, увы, не было, но все казалось очень знакомым: переменные, структуры, условия, циклы и т. д. Где и что поправить, нашли сразу, и конечно, появилась гениальная идея: собрать свой auto_explain с блэкджеком и отборами.
В модуле обнаружили сам текст запроса, поэтому не стали ограничиваться только отбором по имени базы — посчитали очень полезным искать конкретный запрос по вхождению некоторого ключа в текст. В данном случае не будем рассматривать возможные просадки при поиске текста в тексте (есть подозрения, что они могут быть, так как запросы у 1С имеют немыслимые размеры) — при использовании такого типа отбора важно получить сам план, остальное вторично.
Включение и отключение новых отборов (ALTER SYSTEM SET…) повесили на новые параметры, которые также прописываются в этом модуле.
Код модуля auto_explain.c
/*-------------------------------------------------------------------------
*
* auto_explain.c
*
*
* Copyright (c) 2008-2021, PostgreSQL Global Development Group
*
* IDENTIFICATION
* contrib/auto_explain/auto_explain.c
*
*-------------------------------------------------------------------------
*/
#include "postgres.h"
#include <limits.h>
#include "access/parallel.h"
#include "commands/explain.h"
#include "executor/instrument.h"
#include "jit/jit.h"
#include "utils/guc.h"
#include "libpq/libpq.h" /*add*/
#include "miscadmin.h" /*add*/
PG_MODULE_MAGIC;
/* GUC variables */
static int auto_explain_log_min_duration = -1; /* msec or -1 */
static bool auto_explain_log_analyze = false;
static bool auto_explain_log_verbose = false;
static bool auto_explain_log_buffers = false;
static bool auto_explain_log_wal = false;
static bool auto_explain_log_triggers = false;
static bool auto_explain_log_timing = true;
static bool auto_explain_log_settings = false;
static int auto_explain_log_format = EXPLAIN_FORMAT_TEXT;
static int auto_explain_log_level = LOG;
static bool auto_explain_log_nested_statements = false;
static double auto_explain_sample_rate = 1;
static char *auto_explain_base_name = NULL; /*add*/
static char *auto_explain_query_text_like = NULL; /*add*/
static const struct config_enum_entry format_options[] = {
{"text", EXPLAIN_FORMAT_TEXT, false},
{"xml", EXPLAIN_FORMAT_XML, false},
{"json", EXPLAIN_FORMAT_JSON, false},
{"yaml", EXPLAIN_FORMAT_YAML, false},
{NULL, 0, false}
};
static const struct config_enum_entry loglevel_options[] = {
{"debug5", DEBUG5, false},
{"debug4", DEBUG4, false},
{"debug3", DEBUG3, false},
{"debug2", DEBUG2, false},
{"debug1", DEBUG1, false},
{"debug", DEBUG2, true},
{"info", INFO, false},
{"notice", NOTICE, false},
{"warning", WARNING, false},
{"log", LOG, false},
{NULL, 0, false}
};
/* Current nesting depth of ExecutorRun calls */
static int nesting_level = 0;
/* Is the current top-level query to be sampled? */
static bool current_query_sampled = false;
#define auto_explain_enabled() \
(auto_explain_log_min_duration >= 0 && \
(nesting_level == 0 || auto_explain_log_nested_statements) && \
current_query_sampled)
/* Saved hook values in case of unload */
static ExecutorStart_hook_type prev_ExecutorStart = NULL;
static ExecutorRun_hook_type prev_ExecutorRun = NULL;
static ExecutorFinish_hook_type prev_ExecutorFinish = NULL;
static ExecutorEnd_hook_type prev_ExecutorEnd = NULL;
void _PG_init(void);
void _PG_fini(void);
static void explain_ExecutorStart(QueryDesc *queryDesc, int eflags);
static void explain_ExecutorRun(QueryDesc *queryDesc,
ScanDirection direction,
uint64 count, bool execute_once);
static void explain_ExecutorFinish(QueryDesc *queryDesc);
static void explain_ExecutorEnd(QueryDesc *queryDesc);
/*
* Module load callback
*/
void
_PG_init(void)
{
/* Define custom GUC variables. */
DefineCustomIntVariable("auto_explain.log_min_duration",
"Sets the minimum execution time above which plans will be logged.",
"Zero prints all plans. -1 turns this feature off.",
&auto_explain_log_min_duration,
-1,
-1, INT_MAX,
PGC_SUSET,
GUC_UNIT_MS,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("auto_explain.log_analyze",
"Use EXPLAIN ANALYZE for plan logging.",
NULL,
&auto_explain_log_analyze,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("auto_explain.log_settings",
"Log modified configuration parameters affecting query planning.",
NULL,
&auto_explain_log_settings,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("auto_explain.log_verbose",
"Use EXPLAIN VERBOSE for plan logging.",
NULL,
&auto_explain_log_verbose,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("auto_explain.log_buffers",
"Log buffers usage.",
NULL,
&auto_explain_log_buffers,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("auto_explain.log_wal",
"Log WAL usage.",
NULL,
&auto_explain_log_wal,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("auto_explain.log_triggers",
"Include trigger statistics in plans.",
"This has no effect unless log_analyze is also set.",
&auto_explain_log_triggers,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomEnumVariable("auto_explain.log_format",
"EXPLAIN format to be used for plan logging.",
NULL,
&auto_explain_log_format,
EXPLAIN_FORMAT_TEXT,
format_options,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomEnumVariable("auto_explain.log_level",
"Log level for the plan.",
NULL,
&auto_explain_log_level,
LOG,
loglevel_options,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("auto_explain.log_nested_statements",
"Log nested statements.",
NULL,
&auto_explain_log_nested_statements,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("auto_explain.log_timing",
"Collect timing data, not just row counts.",
NULL,
&auto_explain_log_timing,
true,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomRealVariable("auto_explain.sample_rate",
"Fraction of queries to process.",
NULL,
&auto_explain_sample_rate,
1.0,
0.0,
1.0,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
/*add*/
DefineCustomStringVariable("auto_explain.base_name",
"Set database filter.",
NULL,
&auto_explain_base_name,
NULL,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
/*add*/
DefineCustomStringVariable("auto_explain.query_text_like",
"Set query text filter.",
NULL,
&auto_explain_query_text_like,
NULL,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
EmitWarningsOnPlaceholders("auto_explain");
/* Install hooks. */
prev_ExecutorStart = ExecutorStart_hook;
ExecutorStart_hook = explain_ExecutorStart;
prev_ExecutorRun = ExecutorRun_hook;
ExecutorRun_hook = explain_ExecutorRun;
prev_ExecutorFinish = ExecutorFinish_hook;
ExecutorFinish_hook = explain_ExecutorFinish;
prev_ExecutorEnd = ExecutorEnd_hook;
ExecutorEnd_hook = explain_ExecutorEnd;
}
/*
* Module unload callback
*/
void
_PG_fini(void)
{
/* Uninstall hooks. */
ExecutorStart_hook = prev_ExecutorStart;
ExecutorRun_hook = prev_ExecutorRun;
ExecutorFinish_hook = prev_ExecutorFinish;
ExecutorEnd_hook = prev_ExecutorEnd;
}
/*
* ExecutorStart hook: start up logging if needed
*/
static void
explain_ExecutorStart(QueryDesc *queryDesc, int eflags)
{
/*
* At the beginning of each top-level statement, decide whether we'll
* sample this statement. If nested-statement explaining is enabled,
* either all nested statements will be explained or none will.
*
* When in a parallel worker, we should do nothing, which we can implement
* cheaply by pretending we decided not to sample the current statement.
* If EXPLAIN is active in the parent session, data will be collected and
* reported back to the parent, and it's no business of ours to interfere.
*/
if (nesting_level == 0)
{
if (auto_explain_log_min_duration >= 0 && !IsParallelWorker())
current_query_sampled = (random() < auto_explain_sample_rate *
((double) MAX_RANDOM_VALUE + 1));
else
current_query_sampled = false;
}
if (auto_explain_enabled())
{
/* Enable per-node instrumentation iff log_analyze is required. */
if (auto_explain_log_analyze && (eflags & EXEC_FLAG_EXPLAIN_ONLY) == 0)
{
if (auto_explain_log_timing)
queryDesc->instrument_options |= INSTRUMENT_TIMER;
else
queryDesc->instrument_options |= INSTRUMENT_ROWS;
if (auto_explain_log_buffers)
queryDesc->instrument_options |= INSTRUMENT_BUFFERS;
if (auto_explain_log_wal)
queryDesc->instrument_options |= INSTRUMENT_WAL;
}
}
if (prev_ExecutorStart)
prev_ExecutorStart(queryDesc, eflags);
else
standard_ExecutorStart(queryDesc, eflags);
if (auto_explain_enabled())
{
/*
* Set up to track total elapsed time in ExecutorRun. Make sure the
* space is allocated in the per-query context so it will go away at
* ExecutorEnd.
*/
if (queryDesc->totaltime == NULL)
{
MemoryContext oldcxt;
oldcxt = MemoryContextSwitchTo(queryDesc->estate->es_query_cxt);
queryDesc->totaltime = InstrAlloc(1, INSTRUMENT_ALL, false);
MemoryContextSwitchTo(oldcxt);
}
}
}
/*
* ExecutorRun hook: all we need do is track nesting depth
*/
static void
explain_ExecutorRun(QueryDesc *queryDesc, ScanDirection direction,
uint64 count, bool execute_once)
{
nesting_level++;
PG_TRY();
{
if (prev_ExecutorRun)
prev_ExecutorRun(queryDesc, direction, count, execute_once);
else
standard_ExecutorRun(queryDesc, direction, count, execute_once);
}
PG_FINALLY();
{
nesting_level--;
}
PG_END_TRY();
}
/*
* ExecutorFinish hook: all we need do is track nesting depth
*/
static void
explain_ExecutorFinish(QueryDesc *queryDesc)
{
nesting_level++;
PG_TRY();
{
if (prev_ExecutorFinish)
prev_ExecutorFinish(queryDesc);
else
standard_ExecutorFinish(queryDesc);
}
PG_FINALLY();
{
nesting_level--;
}
PG_END_TRY();
}
/*
* ExecutorEnd hook: log results if needed
*/
static void
explain_ExecutorEnd(QueryDesc *queryDesc)
{
if (queryDesc->totaltime && auto_explain_enabled())
{
MemoryContext oldcxt;
double msec;
const char *dbname = NULL; /*add*/
/*
* Make sure we operate in the per-query context, so any cruft will be
* discarded later during ExecutorEnd.
*/
oldcxt = MemoryContextSwitchTo(queryDesc->estate->es_query_cxt);
/*
* Make sure stats accumulation is done. (Note: it's okay if several
* levels of hook all do this.)
*/
InstrEndLoop(queryDesc->totaltime);
/* Log plan if duration is exceeded. */
msec = queryDesc->totaltime->total * 1000.0;
/* Base name.*/
/*add*/
if (MyProcPort)
dbname = MyProcPort->database_name;
if (dbname == NULL || *dbname == '\0')
dbname = _("[unknown]");
if (msec >= auto_explain_log_min_duration
&& (auto_explain_base_name == NULL || strcmp(auto_explain_base_name,dbname) == 0) /*add*/
&& (auto_explain_query_text_like == NULL || strstr(queryDesc->sourceText,auto_explain_query_text_like) != NULL) /*add*/
)
{
ExplainState *es = NewExplainState();
es->analyze = (queryDesc->instrument_options && auto_explain_log_analyze);
es->verbose = auto_explain_log_verbose;
es->buffers = (es->analyze && auto_explain_log_buffers);
es->wal = (es->analyze && auto_explain_log_wal);
es->timing = (es->analyze && auto_explain_log_timing);
es->summary = es->analyze;
es->format = auto_explain_log_format;
es->settings = auto_explain_log_settings;
ExplainBeginOutput(es);
ExplainQueryText(es, queryDesc);
ExplainPrintPlan(es, queryDesc);
if (es->analyze && auto_explain_log_triggers)
ExplainPrintTriggers(es, queryDesc);
if (es->costs)
ExplainPrintJITSummary(es, queryDesc);
ExplainEndOutput(es);
/* Remove last line break */
if (es->str->len > 0 && es->str->data[es->str->len - 1] == '\n')
es->str->data[--es->str->len] = '\0';
/* Fix JSON to output an object */
if (auto_explain_log_format == EXPLAIN_FORMAT_JSON)
{
es->str->data[0] = '{';
es->str->data[es->str->len - 1] = '}';
}
/*
* Note: we rely on the existing logging of context or
* debug_query_string to identify just which statement is being
* reported. This isn't ideal but trying to do it here would
* often result in duplication.
*/
ereport(auto_explain_log_level,
(errmsg("duration: %.3f ms plan:\n%s",
msec, es->str->data),
errhidestmt(true)));
}
MemoryContextSwitchTo(oldcxt);
}
if (prev_ExecutorEnd)
prev_ExecutorEnd(queryDesc);
else
standard_ExecutorEnd(queryDesc);
}
С доработками разобрались, но как теперь получить библиотеку?
Интернет, конечно, все показал и рассказал — вот небольшая инструкция, но для CentOS7 (также могут отличаться предустановленные компоненты). Все делаем через терминал на linux сервере, где стоит PG.
- Чтобы было меньше проблем с зависимыми пакетами, подключаем дополнительный репозиторий, иначе в основных просто не будет каких-либо пакетов
yum install centos-release-scl
- Устанавливаем подходящий под версию PG пакет devel. У нас была версия от 1С, поэтому пакет скачивали с сайта 1С. Он находится в дополнительных модулях (Дистрибутив СУБД PostgreSQL для Linux x86 (64-bit) (дополнительные модули) одним архивом (RPM))
yum install postgresql14-1c-devel-14.5-3.el7.x86_64.rpm
- Ставим ещё несколько пакетов для компиляции:
yum install gcc
yum install openssl-devel
- Копируем на сервер, в какую-нибудь папку, наш доработанный модуль и make файл (лежит там же, где и модуль, переделывать его не надо)

- Устанавливаем переменную окружения: export PATH=/usr/pgsql-14/bin/:$PATH
Компилируем модуль: make USE_PGXS=1
Тут важно отменить, что компиляция идет за счет уже установленного PG — за это как раз и отвечает USE_PGXS=1 (почему пошли именно таким путем, история умалчивает)
При компиляции не должно быть никаких error, warning и т. д.
В результате мы должны увидеть нашу библиотеку:
Копируем ее в каталог lib и заменяем существующую:

На этом подготовительные работы завершены, включаем (pgadmin или psql):
ALTER SYSTEM SET auto_explain.base_name = 'zl_tst_pg_2'
ALTER SYSTEM SET auto_explain.query_text_like = 'KEY-111'
ALTER SYSTEM SET auto_explain.log_min_duration = 0
Наслаждаемся планами только по запросам с конкретным ключом:

Не успели приступить к решению основных проблем, как уже что-то написали на СИ и собрали свою библиотеку 😊 Но мы пока и не подозревали, как это пригодится в дальнейшем.
А что там с закрытием месяца?
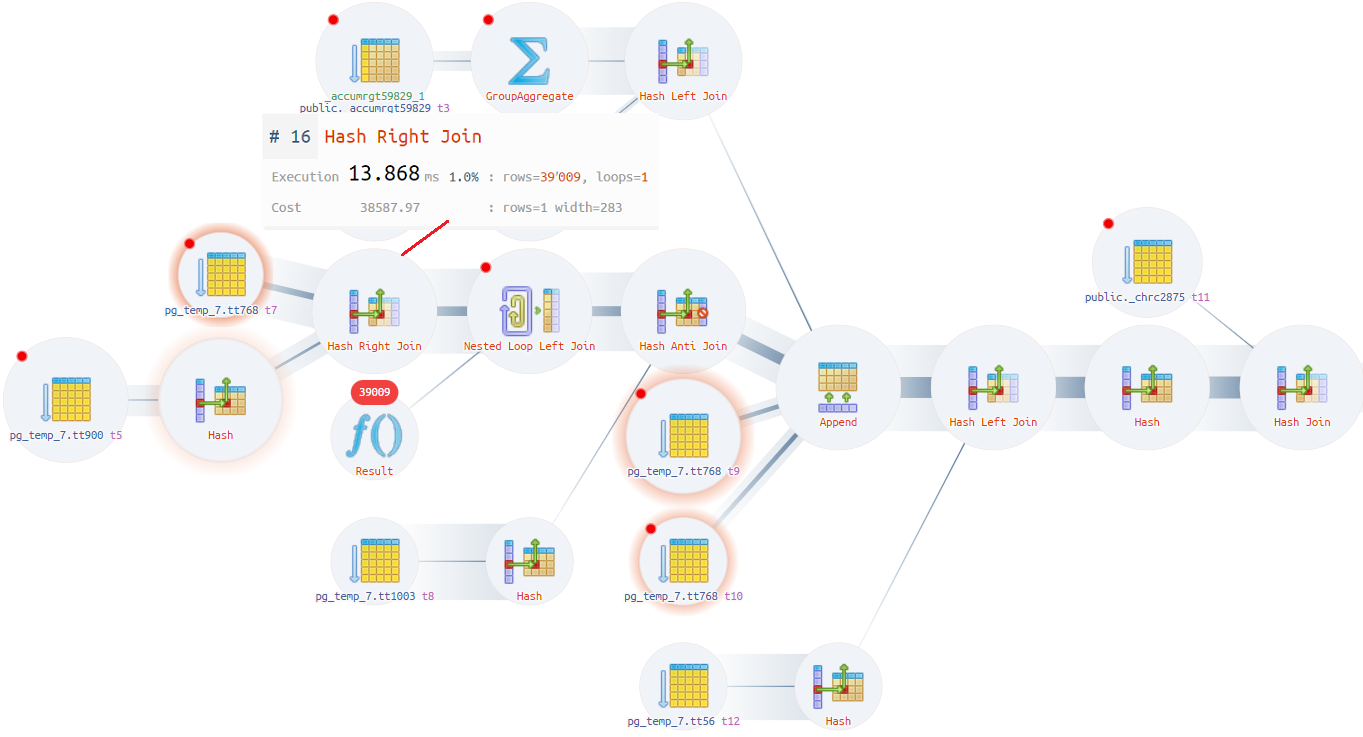
Планы удалось получить, суть проблемы была одна, поэтому посмотрим на один из них:

Loop join ожидает, что будет 1 строка, а получает 39 тысяч строк, отчего надолго «уходит в себя», так как на временной таблице нет индекса и приходится идти в скан (Seq Scan), а там около 200 тысяч строк.
Чтобы не править запрос, ради эксперимента выключили loop (enable_nestloop = off), по одной из рекомендаций на ИТС (https://its.1c.ru/db/metod8dev/content/4692/hdoc). Вдруг всё пройдёт как надо на одних hash join, и тогда при закрытии месяца достаточно выключить loop, а после включить его обратно.
Запустили закрытие месяца, которое выполнилось за 4.5 часа. По распределению времени получили такой расклад:
Ожидалось, что время на весь процесс будет приближено к 2 часам, как на MSSQL. Так как по-прежнему не выполнялось требование в 3 часа, продолжили искать решение проблемы.
Оптимизировали проблемные запросы через расширение и «в лоб»: все неугодное вынесли во временные таблицы и оптимизатор перестал ошибаться при построении плана запроса.
Закрытие, уже с включенным loop и оптимизированными запросами, распределилось так:
Картинка стала интереснее. Получается, что без loop отражение в рег.учете просаживается в 3.5 раза. Конечно, не ожидали фантастического результата, но чтоб так! Заодно экспериментальным путем доказали, что loop лучше не выключать.
План оптимизированных запросов снимать не стали: запрос уже будет выглядеть по-другому, да и результат понятен.
Особо заострять внимание на проблемах запросов не будем, можно только сказать, что в основном это внутренние соединения, которые по факту не уменьшали количество строк, но сильно влияли на оценку стоимости оператора плана запроса, и есть подозрения, что можно было и левое соединение там сделать. А также проблемы, связанные с составными типами, особенно в соединениях с несоставными. Ну и отсутствие индексов, куда же без этого.
Подведем небольшой итог по возможным решениям проблемы:
- Править проблемные запросы через расширение. Слезно просить 1С в очередном обновлении все исправить. А до тех пор поддерживать работоспособность расширения из релиза в релиз. Также надо учесть, что это все были проблемы конкретного случая — сколько такого вылезет в момент эксплуатации, представить тяжело.
- Точечное отключение loop на проблемных запросах. Отключать предполагалось через триггер PG, а давать команду все так же через расширение и записью в таблицу, на которую навешен триггер. В этом случае не придется разбирать сам запрос: если тормозит, просто отключаем loop. Этот способ больше для экстренных случаев, когда решение нужно здесь и сейчас.
- Отключение loop со сканом. А что, если не просто отключать loop, а только там, где он идет в скан? Все-таки loop хорош, когда использует индекс, особенно для больших таблиц, как в нашем случае.
Реализовать 3 вариант уже не казалось фантастикой (спасибо auto_explain), и идея звучала хоть и радикально, но что-то в этом было. Любопытство и сильный интерес взяли верх.
Пишем свою библиотеку plan_optimizer_1c для отключения loop join
Но как понять, как его отключать и откуда начинать копать? Хорошо, что есть зацепка — это параметр enable_nestloop.
Он используется лишь в одном модуле costsize.c. Вот, кстати, как именно происходит то самое отключение:
if (!enable_nestloop)
startup_cost += disable_cost;
Другими словами, стоимость просто задирается в космос. И если не будет вообще никаких вариантов кроме loop, то возьмется loop, хоть он и отключен.
Конечно, было бы замечательно тут рядышком написать свое условие, и дело сделано. Но сборка собственного PG не была целью, хотелось бы пока иметь сборку от 1С с их поддержкой, а все доработки делать надстройками.
Покопав еще немного, нашли подходящий для себя хук (это специальные места, в которых мы можем ворваться в код — разработчики великодушно все предусмотрели). Список доступных хуков можно посмотреть тут: https://github.com/taminomara/psql-hooks/blob/master/Detailed.md
Но была проблема — хук был уже после проработки всех вариантов соединения. Т. е. PG сначала прорабатывает merge, loop, hash, а уже потом вызывается хук, в котором можно было работать со списком проработанных вариантов. Но PG в такой список не добавлял все возможные варианты, а вытеснял, те, что были дорогими. В общем, если PG посчитает что loop дешевле hash, то hash он даже не будет добавлять.
Решение было таковым: найти в этом списке loop со сканом, сильно увеличить стоимость оценки и еще раз проработать вариант с hash.
Тут тоже не обошлось без подводных камней. Тот метод, что прорабатывает hash, не объявлен в заголовочных файлах (которые с расширением .h), а значит компилятор его не найдет. Приняли решение перетянуть сам метод в свою библиотеку. Естественно, он попросил еще несколько, и в совокупности получили около 4 методов. Все они находятся в модуле joinpath.c. Думаю, ничего страшного в этом нет, все равно компилируем под конкретную версию PG.
В самом алгоритме отключения решили все-таки отталкиваться от индексов: отключаем loop, где он не идет в индекс, при этом учитываем, что в индекс может пойти через Memoize и Materialize. Получается, что все остальное считается для нас сканом. Возможно, не все случаи и операторы заложили — посчитали, что на данном этапе этого достаточно.
Дополнительно не стали трогать loop, который хоть и по скану, но в маленькую таблицу. Приблизительно оценили маленькую таблицу в 1000 строк и задали значение пока что жестко в условии.
Код модуля plan_optimizer_1c.c (за основу был взят естественно auto_explain)
/*-------------------------------------------------------------------------
*
* plan_optimizer_1c.c
*
*-------------------------------------------------------------------------
*/
#include "postgres.h"
#include "optimizer/pathnode.h"
#include "optimizer/paths.h"
#include "optimizer/cost.h"
#include "utils/guc.h"
#include <time.h>
PG_MODULE_MAGIC;
static double tuples_threshold = 1000;
/*log info*/
static int log_freq_sec = 60;
static time_t log_time;
static long join_total = 0;
static long loop_total = 0;
static long loop_index_total = 0;
static long loop_memo_index_total = 0;
static long loop_mat_index_total = 0;
static long loop_other_total = 0;
static long loop_replace_total = 0;
static long loop_other_threshold_total = 0;
/* GUC variables */
static bool nestloop_on_scan_to_hash = false;
static bool enable_log_join = false;
static set_join_pathlist_hook_type prev_set_join_pathlist_hook = NULL;
void _PG_init(void);
void _PG_fini(void);
static void set_join_pathlist(PlannerInfo *root,
RelOptInfo *joinrel,
RelOptInfo *outerrel,
RelOptInfo *innerrel,
JoinType jointype,
JoinPathExtraData *extra);
static void agg_tuples(PlannerInfo *root, Path *path, double *tuples);
/* dependent methods */
#define PATH_PARAM_BY_PARENT(path, rel) \
((path)->param_info && bms_overlap(PATH_REQ_OUTER(path), \
(rel)->top_parent_relids))
#define PATH_PARAM_BY_REL_SELF(path, rel) \
((path)->param_info && bms_overlap(PATH_REQ_OUTER(path), (rel)->relids))
#define PATH_PARAM_BY_REL(path, rel) \
(PATH_PARAM_BY_REL_SELF(path, rel) || PATH_PARAM_BY_PARENT(path, rel))
static void hash_inner_and_outer(PlannerInfo *root, RelOptInfo *joinrel,
RelOptInfo *outerrel, RelOptInfo *innerrel,
JoinType jointype, JoinPathExtraData *extra);
static inline bool clause_sides_match_join(RestrictInfo *rinfo,
RelOptInfo *outerrel,
RelOptInfo *innerrel);
/*
* Module load callback
*/
void
_PG_init(void)
{
DefineCustomBoolVariable("plan_optimizer_1c.nestloop_on_scan_to_hash",
"Replace nestloop on scan to hash join",
NULL,
&nestloop_on_scan_to_hash,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
DefineCustomBoolVariable("plan_optimizer_1c.enable_log_join",
"Log join statistics",
NULL,
&enable_log_join,
false,
PGC_SUSET,
0,
NULL,
NULL,
NULL);
EmitWarningsOnPlaceholders("plan_optimizer_1c");
/* Install hooks. */
prev_set_join_pathlist_hook = set_join_pathlist_hook;
set_join_pathlist_hook = set_join_pathlist;
log_time = time(NULL);
}
/*
* Module unload callback
*/
void
_PG_fini(void)
{
set_join_pathlist_hook = prev_set_join_pathlist_hook;
}
/*
* set_join_pathlist_hook
*/
static void
set_join_pathlist(PlannerInfo *root,
RelOptInfo *joinrel,
RelOptInfo *outerrel,
RelOptInfo *innerrel,
JoinType jointype,
JoinPathExtraData *extra)
{
if (prev_set_join_pathlist_hook)
prev_set_join_pathlist_hook(root, joinrel, outerrel, innerrel,
jointype, extra);
if (nestloop_on_scan_to_hash && enable_hashjoin)
{
bool is_loop_log = false;
bool is_loop_index_log = false;
bool is_loop_memo_index_log = false;
bool is_loop_mat_index_log = false;
bool is_loop_other_log = false;
bool is_loop_replace_log = false;
bool is_loop_other_threshold_log = false;
bool replace_nestloop = false;
ListCell *p1;
int iter = 0;
foreach(p1, joinrel->pathlist)
{
Path *current_path = (Path *) lfirst(p1);
JoinPath *current_joinpath = (JoinPath *) current_path;
Path *inner_path = current_joinpath->innerjoinpath;
iter += 1;
if (current_joinpath->path.pathtype == T_NestLoop)
{
bool is_loop_index = false;
bool is_loop_memo_index = false;
bool is_loop_mat_index = false;
if (inner_path->pathtype == T_IndexScan || inner_path->pathtype == T_IndexOnlyScan)
is_loop_index = true;
if (inner_path->pathtype == T_Memoize
&& (((MemoizePath *) inner_path)->subpath->pathtype == T_IndexScan
|| ((MemoizePath *) inner_path)->subpath->pathtype == T_IndexOnlyScan
)
)
is_loop_memo_index = true;
if (inner_path->pathtype == T_Material
&& (((MaterialPath *) inner_path)->subpath->pathtype == T_IndexScan
|| ((MaterialPath *) inner_path)->subpath->pathtype == T_IndexOnlyScan
)
)
is_loop_mat_index = true;
if (!is_loop_index && !is_loop_memo_index && !is_loop_mat_index)
{
double tuples = -1;
agg_tuples(root,inner_path,&tuples);
if(tuples>tuples_threshold || tuples == -1)
{
replace_nestloop = true;
current_path->total_cost += disable_cost;
/*log info*/
if (iter == 1)
is_loop_replace_log = true;
}
/*log info*/
if (iter == 1)
{
is_loop_other_log = true;
if (tuples>tuples_threshold)
is_loop_other_threshold_log = true;
}
}
/*log info*/
if (iter == 1)
{
is_loop_log = true;
is_loop_index_log = is_loop_index;
is_loop_memo_index_log = is_loop_memo_index;
is_loop_mat_index_log = is_loop_mat_index;
}
}
}
if (replace_nestloop)
{
hash_inner_and_outer(root, joinrel, outerrel, innerrel,
jointype, extra);
/*log info*/
foreach(p1, joinrel->pathlist)
{
Path *current_path = (Path *) lfirst(p1);
JoinPath *current_joinpath = (JoinPath *) current_path;
if (!(current_joinpath->path.pathtype == T_HashJoin && is_loop_replace_log))
{
is_loop_replace_log = false;
}
break;
}
}
/*log info*/
if (enable_log_join)
{
join_total += 1;
if (is_loop_log)
loop_total += 1;
if (is_loop_index_log)
loop_index_total += 1;
if (is_loop_memo_index_log)
loop_memo_index_total += 1;
if (is_loop_mat_index_log)
loop_mat_index_total += 1;
if (is_loop_other_log)
loop_other_total += 1;
if (is_loop_replace_log)
loop_replace_total += 1;
if (is_loop_other_threshold_log)
loop_other_threshold_total += 1;
if (difftime(time(NULL),log_time) >= log_freq_sec)
{
ereport(LOG,
(errmsg("join: %li loop: %li loop index: %li loop memo index: %li loop mat index: %li loop other: %li loop threshold: %li loop replace: %li",
join_total, loop_total,loop_index_total,loop_memo_index_total,loop_mat_index_total,
loop_other_total,loop_other_threshold_total,loop_replace_total
),
errhidestmt(true)));
log_time = time(NULL);
}
}
}
}
static void
agg_tuples(PlannerInfo *root, Path *path, double *tuples)
{
bool bitmap = false;
List *bitmapquals;
Path *subpath = NULL;
switch (nodeTag(path))
{
case T_Path:
if (*tuples < 0)
*tuples = 0;
*tuples+=path->parent->tuples;
break;
case T_BitmapHeapPath:
subpath = ((BitmapHeapPath *) path)->bitmapqual;
break;
case T_BitmapAndPath:
bitmap = true;
bitmapquals = ((BitmapAndPath *) path)->bitmapquals;
break;
case T_BitmapOrPath:
bitmap = true;
bitmapquals = ((BitmapOrPath *) path)->bitmapquals;
break;
case T_MaterialPath:
subpath = ((MaterialPath *) path)->subpath;
break;
case T_MemoizePath:
subpath = ((MemoizePath *) path)->subpath;
break;
case T_UniquePath:
subpath = ((UniquePath *) path)->subpath;
break;
case T_SortPath:
subpath = ((SortPath *) path)->subpath;
break;
case T_IncrementalSortPath:
subpath = ((SortPath *) path)->subpath;
break;
case T_GroupPath:
subpath = ((GroupPath *) path)->subpath;
break;
case T_UpperUniquePath:
subpath = ((UpperUniquePath *) path)->subpath;
break;
case T_AggPath:
subpath = ((AggPath *) path)->subpath;
break;
case T_GroupingSetsPath:
subpath = ((GroupingSetsPath *) path)->subpath;
break;
case T_WindowAggPath:
subpath = ((WindowAggPath *) path)->subpath;
break;
case T_SetOpPath:
subpath = ((SetOpPath *) path)->subpath;
break;
case T_LockRowsPath:
subpath = ((LockRowsPath *) path)->subpath;
break;
case T_LimitPath:
subpath = ((LimitPath *) path)->subpath;
break;
default:
break;
}
if (bitmap)
{
ListCell *lc;
foreach(lc, bitmapquals)
{
Path *bitmapqual = (Path *) lfirst(lc);
agg_tuples(root, bitmapqual, tuples);
}
}
if (subpath)
agg_tuples(root, subpath, tuples);
}
/* dependent methods */
static void
try_hashjoin_path(PlannerInfo *root,
RelOptInfo *joinrel,
Path *outer_path,
Path *inner_path,
List *hashclauses,
JoinType jointype,
JoinPathExtraData *extra)
{
Relids required_outer;
JoinCostWorkspace workspace;
/*
* Check to see if proposed path is still parameterized, and reject if the
* parameterization wouldn't be sensible.
*/
required_outer = calc_non_nestloop_required_outer(outer_path,
inner_path);
if (required_outer &&
!bms_overlap(required_outer, extra->param_source_rels))
{
/* Waste no memory when we reject a path here */
bms_free(required_outer);
return;
}
/*
* See comments in try_nestloop_path(). Also note that hashjoin paths
* never have any output pathkeys, per comments in create_hashjoin_path.
*/
initial_cost_hashjoin(root, &workspace, jointype, hashclauses,
outer_path, inner_path, extra, false);
if (add_path_precheck(joinrel,
workspace.startup_cost, workspace.total_cost,
NIL, required_outer))
{
add_path(joinrel, (Path *)
create_hashjoin_path(root,
joinrel,
jointype,
&workspace,
extra,
outer_path,
inner_path,
false, /* parallel_hash */
extra->restrictlist,
required_outer,
hashclauses));
}
else
{
/* Waste no memory when we reject a path here */
bms_free(required_outer);
}
}
static void
try_partial_hashjoin_path(PlannerInfo *root,
RelOptInfo *joinrel,
Path *outer_path,
Path *inner_path,
List *hashclauses,
JoinType jointype,
JoinPathExtraData *extra,
bool parallel_hash)
{
JoinCostWorkspace workspace;
/*
* If the inner path is parameterized, the parameterization must be fully
* satisfied by the proposed outer path. Parameterized partial paths are
* not supported. The caller should already have verified that no lateral
* rels are required here.
*/
Assert(bms_is_empty(joinrel->lateral_relids));
if (inner_path->param_info != NULL)
{
Relids inner_paramrels = inner_path->param_info->ppi_req_outer;
if (!bms_is_empty(inner_paramrels))
return;
}
/*
* Before creating a path, get a quick lower bound on what it is likely to
* cost. Bail out right away if it looks terrible.
*/
initial_cost_hashjoin(root, &workspace, jointype, hashclauses,
outer_path, inner_path, extra, parallel_hash);
if (!add_partial_path_precheck(joinrel, workspace.total_cost, NIL))
return;
/* Might be good enough to be worth trying, so let's try it. */
add_partial_path(joinrel, (Path *)
create_hashjoin_path(root,
joinrel,
jointype,
&workspace,
extra,
outer_path,
inner_path,
parallel_hash,
extra->restrictlist,
NULL,
hashclauses));
}
static void
hash_inner_and_outer(PlannerInfo *root,
RelOptInfo *joinrel,
RelOptInfo *outerrel,
RelOptInfo *innerrel,
JoinType jointype,
JoinPathExtraData *extra)
{
JoinType save_jointype = jointype;
bool isouterjoin = IS_OUTER_JOIN(jointype);
List *hashclauses;
ListCell *l;
/*
* We need to build only one hashclauses list for any given pair of outer
* and inner relations; all of the hashable clauses will be used as keys.
*
* Scan the join's restrictinfo list to find hashjoinable clauses that are
* usable with this pair of sub-relations.
*/
hashclauses = NIL;
foreach(l, extra->restrictlist)
{
RestrictInfo *restrictinfo = (RestrictInfo *) lfirst(l);
/*
* If processing an outer join, only use its own join clauses for
* hashing. For inner joins we need not be so picky.
*/
if (isouterjoin && RINFO_IS_PUSHED_DOWN(restrictinfo, joinrel->relids))
continue;
if (!restrictinfo->can_join ||
restrictinfo->hashjoinoperator == InvalidOid)
continue; /* not hashjoinable */
/*
* Check if clause has the form "outer op inner" or "inner op outer".
*/
if (!clause_sides_match_join(restrictinfo, outerrel, innerrel))
continue; /* no good for these input relations */
hashclauses = lappend(hashclauses, restrictinfo);
}
/* If we found any usable hashclauses, make paths */
if (hashclauses)
{
/*
* We consider both the cheapest-total-cost and cheapest-startup-cost
* outer paths. There's no need to consider any but the
* cheapest-total-cost inner path, however.
*/
Path *cheapest_startup_outer = outerrel->cheapest_startup_path;
Path *cheapest_total_outer = outerrel->cheapest_total_path;
Path *cheapest_total_inner = innerrel->cheapest_total_path;
/*
* If either cheapest-total path is parameterized by the other rel, we
* can't use a hashjoin. (There's no use looking for alternative
* input paths, since these should already be the least-parameterized
* available paths.)
*/
if (PATH_PARAM_BY_REL(cheapest_total_outer, innerrel) ||
PATH_PARAM_BY_REL(cheapest_total_inner, outerrel))
return;
/* Unique-ify if need be; we ignore parameterized possibilities */
if (jointype == JOIN_UNIQUE_OUTER)
{
cheapest_total_outer = (Path *)
create_unique_path(root, outerrel,
cheapest_total_outer, extra->sjinfo);
Assert(cheapest_total_outer);
jointype = JOIN_INNER;
try_hashjoin_path(root,
joinrel,
cheapest_total_outer,
cheapest_total_inner,
hashclauses,
jointype,
extra);
/* no possibility of cheap startup here */
}
else if (jointype == JOIN_UNIQUE_INNER)
{
cheapest_total_inner = (Path *)
create_unique_path(root, innerrel,
cheapest_total_inner, extra->sjinfo);
Assert(cheapest_total_inner);
jointype = JOIN_INNER;
try_hashjoin_path(root,
joinrel,
cheapest_total_outer,
cheapest_total_inner,
hashclauses,
jointype,
extra);
if (cheapest_startup_outer != NULL &&
cheapest_startup_outer != cheapest_total_outer)
try_hashjoin_path(root,
joinrel,
cheapest_startup_outer,
cheapest_total_inner,
hashclauses,
jointype,
extra);
}
else
{
/*
* For other jointypes, we consider the cheapest startup outer
* together with the cheapest total inner, and then consider
* pairings of cheapest-total paths including parameterized ones.
* There is no use in generating parameterized paths on the basis
* of possibly cheap startup cost, so this is sufficient.
*/
ListCell *lc1;
ListCell *lc2;
if (cheapest_startup_outer != NULL)
try_hashjoin_path(root,
joinrel,
cheapest_startup_outer,
cheapest_total_inner,
hashclauses,
jointype,
extra);
foreach(lc1, outerrel->cheapest_parameterized_paths)
{
Path *outerpath = (Path *) lfirst(lc1);
/*
* We cannot use an outer path that is parameterized by the
* inner rel.
*/
if (PATH_PARAM_BY_REL(outerpath, innerrel))
continue;
foreach(lc2, innerrel->cheapest_parameterized_paths)
{
Path *innerpath = (Path *) lfirst(lc2);
/*
* We cannot use an inner path that is parameterized by
* the outer rel, either.
*/
if (PATH_PARAM_BY_REL(innerpath, outerrel))
continue;
if (outerpath == cheapest_startup_outer &&
innerpath == cheapest_total_inner)
continue; /* already tried it */
try_hashjoin_path(root,
joinrel,
outerpath,
innerpath,
hashclauses,
jointype,
extra);
}
}
}
/*
* If the joinrel is parallel-safe, we may be able to consider a
* partial hash join. However, we can't handle JOIN_UNIQUE_OUTER,
* because the outer path will be partial, and therefore we won't be
* able to properly guarantee uniqueness. Similarly, we can't handle
* JOIN_FULL and JOIN_RIGHT, because they can produce false null
* extended rows. Also, the resulting path must not be parameterized.
* We would be able to support JOIN_FULL and JOIN_RIGHT for Parallel
* Hash, since in that case we're back to a single hash table with a
* single set of match bits for each batch, but that will require
* figuring out a deadlock-free way to wait for the probe to finish.
*/
if (joinrel->consider_parallel &&
save_jointype != JOIN_UNIQUE_OUTER &&
save_jointype != JOIN_FULL &&
save_jointype != JOIN_RIGHT &&
outerrel->partial_pathlist != NIL &&
bms_is_empty(joinrel->lateral_relids))
{
Path *cheapest_partial_outer;
Path *cheapest_partial_inner = NULL;
Path *cheapest_safe_inner = NULL;
cheapest_partial_outer =
(Path *) linitial(outerrel->partial_pathlist);
/*
* Can we use a partial inner plan too, so that we can build a
* shared hash table in parallel? We can't handle
* JOIN_UNIQUE_INNER because we can't guarantee uniqueness.
*/
if (innerrel->partial_pathlist != NIL &&
save_jointype != JOIN_UNIQUE_INNER &&
enable_parallel_hash)
{
cheapest_partial_inner =
(Path *) linitial(innerrel->partial_pathlist);
try_partial_hashjoin_path(root, joinrel,
cheapest_partial_outer,
cheapest_partial_inner,
hashclauses, jointype, extra,
true /* parallel_hash */ );
}
/*
* Normally, given that the joinrel is parallel-safe, the cheapest
* total inner path will also be parallel-safe, but if not, we'll
* have to search for the cheapest safe, unparameterized inner
* path. If doing JOIN_UNIQUE_INNER, we can't use any alternative
* inner path.
*/
if (cheapest_total_inner->parallel_safe)
cheapest_safe_inner = cheapest_total_inner;
else if (save_jointype != JOIN_UNIQUE_INNER)
cheapest_safe_inner =
get_cheapest_parallel_safe_total_inner(innerrel->pathlist);
if (cheapest_safe_inner != NULL)
try_partial_hashjoin_path(root, joinrel,
cheapest_partial_outer,
cheapest_safe_inner,
hashclauses, jointype, extra,
false /* parallel_hash */ );
}
}
}
static inline bool
clause_sides_match_join(RestrictInfo *rinfo, RelOptInfo *outerrel,
RelOptInfo *innerrel)
{
if (bms_is_subset(rinfo->left_relids, outerrel->relids) &&
bms_is_subset(rinfo->right_relids, innerrel->relids))
{
/* lefthand side is outer */
rinfo->outer_is_left = true;
return true;
}
else if (bms_is_subset(rinfo->left_relids, innerrel->relids) &&
bms_is_subset(rinfo->right_relids, outerrel->relids))
{
/* righthand side is outer */
rinfo->outer_is_left = false;
return true;
}
return false; /* no good for these input relations */
}
MODULE_big = plan_optimizer_1c
OBJS = \
$(WIN32RES) \
plan_optimizer_1c.o
PGFILEDESC = "plan_optimizer_1c"
TAP_TESTS = 1
ifdef USE_PGXS
PG_CONFIG = pg_config
PGXS := $(shell $(PG_CONFIG) --pgxs)
include $(PGXS)
else
subdir = contrib
top_builddir = ..
include $(top_builddir)/src/Makefile.global
include $(top_srcdir)/contrib/contrib-global.mk
endif
Ну и компилируем уже известным способом.
Полученную библиотеку закидываем в lib и прописываем в shared_preload_libraries или session_preload_libraries, как пример вместе с auto_explain:
ALTER SYSTEM SET session_preload_libraries = auto_explain,plan_optimizer_1c
Включаем:
ALTER SYSTEM SET plan_optimizer_1c.nestloop_on_scan_to_hash = on
При этом enable_nestloop должен быть включен.
Настало время закрыть месяц еще раз, но уже без изменений на стороне 1С. Результаты были такие:
То есть так же, как и с оптимизированными запросами и с полным loop. Честно, именно такого результата не ожидали, думали, что будет хуже.
Решили посмотреть на план, сделали расширение и через него закинули в запрос ключ KEY-111 для auto_explain. Ждем 20 мин, не боясь забить логами сервер и получаем результат:
Как и ожидалось, вместо loop красуется hash, а время выполнения всего запроса составило 1.4 сек. Но одного теста показалось маловато, да и время закрытия месяца получали приблизительно. Как раз была одна база, для нагрузки сервера, на основе ERP. Обработкой, в несколько потоков, создается цепочка документов Заказ клиента – Заказ поставщика – Приобретение – Перемещение – Реализация – Оплата. Все документы создаются со смещением, чтобы на конец месяца оставались остатки. Количество строк в табличных частях немного, около 5. Для теста отказались от многопоточности, чтобы исключить ожидания на блокировках. Для начала заполнили пустую базу, создали где-то 15000 цепочек, и запустили тест на создание 30 цепочек. Решили проверить сразу 3 варианта: с включенным loop, с нашей библиотекой plan_optimizer_1c и вообще без loop, только на hash. Все тесты делались многократно. Результат:

В первую очередь хочется отметить, что данный тест должен был показать как раз не плюсы, а минусы библиотеки, точнее заложенных в нее алгоритмов. Так как база небольшая, то ошибок оптимизатора должно быть крайне мало. Поэтому, если бы было много замен loop на hash, тест бы это показал. По нашим подсчетам, количество переделанных loop составило где-то 1%, что достаточно немного, и, как итог, не получили отклонений.
В любом случае, при выявлении в будущем каких-либо отклонений уже есть основа для их исключения, и можно продолжать совершенствовать алгоритм, отталкиваясь от дополнительных параметров, которые доступны для анализа на операторах плана запроса. В общем, есть куда развиваться.
Итоги
Open source открыл новые возможности для решения проблем, о которых раньше и не задумывались.
Все оказалось не так страшно и сложно, как могло быть. Многие вещи вообще делались впервые, и не исключаем того факта, что некоторые моменты были восприняты и поняты не так. Надо быть осторожным с доработками того или иного механизма, так как он мог быть изменен в вашей версии PG. Скажем, 1С свою PG патчит и не слабо, даже тот же auto_explain попадает под раздачу (это обнаружилось уже после всего).
Что касается того, что было сделано.
Доработанный auto_explain уже в полную используется, новые отборы очень даже кстати. Конечно было бы неплохо, если бы 1С включила это в свои патчи.
plan_optimizer_1c, как минимум, подойдет для закрытия месяца, когда можно вот так отключить loop со сканом, а после закрытия уже вернуть все обратно. Остается вопрос: можно ли оставить так на постоянной основе? Хоть тесты и показывают хороший результат, но все индивидуально и зависит от разных факторов и условий. Надо проводить реальные тесты, приближенные к основным процессам в работе пользователей. Поэтому нам еще предстоит неоднократно проверить на прочность эту библиотеку, чтобы окончательно определиться с ее использованием, а в идеале получить решение от 1С.





