Поговорим о том, как устроены статистики в MS SQL, почему 1С иногда мешает статистикам работать правильно, и чем это все заканчивается.
Сразу важное замечание – все, о чем я говорю, относится к MS SQL Server, потому что я здесь рассказываю в том числе и о том, что происходит «под капотом». В PostgreSQL и других СУБД это может работать по-другому. Поэтому важно, что это все описанное в первую очередь касается MS SQL Server .
Зачем нужны статистики?
От качества статистик зависят ваши планы выполнения запросов и, соответственно скорость выполнения этих запросов. Поэтому очень важно понимать, как статистики работают, и что на них влияет.
Все мы знаем, что SQL – это декларативный язык, который говорит, «что нужно получить», но не говорит – «как». А «как получать» – придумывает сам SQL-сервер в виде плана выполнения запроса (см. иллюстрацию ниже).

План выполнения запроса – это, по сути, инструкция, какие операции выполнить и в каком порядке, чтобы получить нужный результат. При этом, у СУБД есть несколько вариантов чтения данных (индексный поиск vs. сканирование) и также несколько способов эти данные связать друг с другом. Естественно, возникает вопрос – что выбрать?
Например, для того, чтобы связать данные двух таблиц, у нас есть три базовых варианта соединения:
-
Nested Loops – вложенные циклы;
-
Hash Match – соединение по хэш-таблице;
-
Merge Join – соединение слиянием

У каждого из этих вариантов свои плюсы и минусы.
-
Nested Loops хорошо подходит, когда у нас на входе, с одной стороны, большой набор данных, а с другой стороны – маленький. В этом варианте работают вложенные циклы, и когда мы по маленькому набору быстро проходим, то сразу находим, что нужно. Но Nested Loops чудовищно проседает, когда у нас с обеих сторон большие наборы данных – скажем, для каждой из миллиона строк одного набора надо выполнить поиск по миллионам строк второго набора. Обычно так и возникают многочасовые ожидания выполнения запроса.
-
Hash Match – наоборот, очень хорошо работает с большими наборами, каждый из них будет прочитан по одному разу. Два скана для больших наборов – это гораздо лучше, чем миллионы и миллиарды повторяющихся поисков, как было бы с Nested Loops. Но с другой стороны, если из каждого из этих наборов нам нужно отобрать по несколько строк – это будут избыточные чтения, а также избыточное потребление оперативной памяти.
Получается, когда мы выбираем, какой именно оператор использовать для соединения нескольких источников, нам нужно понимать, какой объем данных мы собираемся сопоставить. В этом нам как раз помогают статистики.
Статистики – это объекты в базе данных, которые хранят распределение данных внутри таблицы. Это выглядит приблизительно так, как на рисунке ниже.

Например, у нас есть таблица с контрагентами или физлицами. Она огромная – там миллионы записей. Мы просто посчитали распределение по этим записям, составили гистограмму и после этого понимаем – сколько у нас людей на букву А, сколько на букву Б и т.д.
И уже дальше SQL-сервер, когда готовит план выполнения, смотрит в эти гистограммы, примерно прикидывает, сколько ему строк в каждом случае вернется, и после этого может построить правильный план, который порадует и вас, как администраторов, которые следят за ресурсами, и пользователей, которые ждут, что этот запрос очень быстро выполнится.
Как физически устроены статистики?
Давайте посмотрим, как физически организованы статистики.
Отдельная статистика существует для каждого индекса, поэтому изучим статистику для индекса по «наименованию» справочника «Контрагенты». Я посмотрел соответствующие названия полей через оператор «ПолучитьСтруктуруХраненияБазыДанных» – в вашей базе названия SQL-объектов могут отличаться!
Для того,чтобы заглянуть статистике «под капот», воспользуемся старой, хорошо документированной командой
dbcc show_statistics

Сразу замечу, что это уже достаточно устаревшая команда. Всё дело в том, что она требует повышенных прав и возвращает сразу 3 набора данных. В результате она совершенно не подходит для применения в каких-нибудь скриптах или даже обычных запросах. Если вы пытаетесь что-то автоматизировать и вам нужна информация о статистиках, посмотрите документацию о DMV, например sys.dm_db_stats_histogram.
Первый набор данных показывает нам общую информацию о статистике: к какому объекту она относится, сколько шагов в гистограмме, средний размер шага и т.д.
И тут я напомню, как должны выглядеть статистики здорового человека. Это вот такая красивая гистограмма: видно, что у нас все распределение разбивается на несколько столбцов, в каждом из которых какое-то количество строк (не обязательно одинаковое!)
Теперь давайте посмотрим, что я увидел в тестовой базе 1С. Конечно, я ее немного накачал данными – у меня в справочнике получилось 4.5 миллиона строк. Но картинка получилась вот такая:

4.5 миллиона строк и всего один шаг в статистике. Это просто смешно. Получается, как в том анекдоте про среднюю температуру по больнице. Внизу труп, наверху у нас горячка, посередине у нас какие-то непонятные 76,7 тысяч строк просемплировано. Это совершенно бессмысленно. У нас всего один шаг, и с каким бы значением параметра мы не пришли, выбирая наш план запроса, мы все равно придем к одной и той же оценке – одинаково плохой для всех вариантов. И план у нас будет всегда одинаково плохой.
Почему так выходит? Смотрим дальше. Я уже говорил, что dbcc show_statistics возвращает три набора данных – второй из них нам сейчас объяснит, в чем дело.

Вот у нас колонки, по которым строится статистика. И, если мы говорим про статистику, которая привязана к индексу, она всегда строится по первой колонке в индексе.
А какая у нас колонка во всех индексах типовой конфигурации? Правильно, «разделитель учета», который всегда равен одному и тому же значению!
Даже если у вас несколько баз, несколько организаций, несколько разделителей учета, они все равно никак не коррелируют, не релевантны всем последующим значениям в строке. Зная разделитель учёта из строки, вы не можете сказать, какой в этой строке контрагент – Вася или Петя. С равной вероятностью может быть любой. То есть мы строим статистику по нерелевантному, одинаковому значению, а все остальные значения из строки у нас оказываются за бортом.
Да, есть ещё мера корреляции (вторая и третья строки на рисунке выше), но это опять корреляция к одному-единственному значению. То есть, та же самая «средняя температура по больнице». Такая статистика оказывается просто бесполезна.
Признаюсь, когда я в первый раз увидел эту картинку, у меня была реакция, как у героев «Бриллиантовой руки», потому что это правда катастрофа.

Получается, у нас есть куча индексных статистик, которые не работают. Мы их обслуживаем, что-то с ними делаем, надеемся, что у нас будут строится правильные планы, а все это оказывается бессмысленно.
Но, с другой стороны, если успокоиться и подумать – ведь как-то это всё–таки работает. Даже с таким статистиками запросы выполняются за секунды, а не за часы. Я часто в работе вижу корректные планы выполнения. Значит, всё не так просто, надо посмотреть, что происходит вживую.
Посмотрим, как это работает «вживую»
Я решил детально изучить, как выбирается и выполняется план выполнения на 1С-базе. В этом мне очень сильно помог SQL Server. Дело в том, что начиная с версии SQL Server 2014 SP2 прямо в плане запроса показано, какие статистики использовались при составлении этого плана. Можно даже посмотреть, в каком состоянии были эти статистики – когда они в последний раз пересчитывались, сколько изменений накопилось и т.д.

Чтобы получить план выполнения запроса из 1С, можно использовать привычный всем SQL Profiler, но это старая технология, которую уже лет 15 грозятся «похоронить» с каждым следующим релизом SQL Server. И есть за что – работающий профайлер, особенно собирающий планы запросов, может просадить скорость работы СУБД в несколько раз.
Вместо этого я воспользовался расширенными событиями (Extended Events). Эта технология существует в SQL Server те же самые 15 лет, но сделана специально для того, чтобы легковесно, с минимальной нагрузкой, собирать те данные, которые вам нужны для какого-то расследования или просто для мониторинга.
Слава Богу, что начиная с SQL Server Management Studio 2014 появился удобный интерфейс работы с расширенными событиями – больше не надо разгребать тонны XML, чтобы найти в них нужную информацию. Теперь же в Management Studio появилась отдельная «папка», посвященная работе с расширенными событиями. Удобные мастера для настройки событий и фильтров. И интерфейс для изучения собранных данных.

Для расследования тяжелых запросов возьмём готовый набор Query Detail Tracking.

Добавим туда очень важное событие query_post_execution_plan. На самом деле, мне бы и обычного estimated-плана хватило бы, потому что этот предварительный план уже все знает о тех статистиках, которые нам нужны. Но query_post_execution_plan – это самый максимальный вариант, самая подробная статистика, которую можно получить. (правда, ценой повышенной нагрузки на систему)
Я всех призываю посмотреть, что хранится в actual execution plan – плане, который мы получаем при выполнении запроса. Это – бесценный кладезь, огромное количество полезной информации. Тем более, что разработчики MS SQL Server расширяют этот набор от версии к версии.
Там есть информация по статистикам, про которую я уже говорил.
Есть рекомендации по индексам – про это тоже уже наверняка все знают, многие видели и используют.
В новых версиях добавили список флагов трассировки, которые в данный момент у вас включены.
Самое крутое – если у вас есть этот actual execution plan (план выполнения с реальной статистикой), в последних версиях вы можете видеть время, которое было затрачено на каждую операцию. Т.е. если у вас тормозит запрос, если вы не знаете, что делать – просто получаете actual plan. Да, это дорого, это тяжело с точки зрения производительности. Но это бесценно. И прямо смотрите в плане – на эту операцию у меня ушло 2 секунды, на эту – 10 секунд. Значит, именно сюда я буду смотреть и расследовать.
В общем, всем рекомендую, кто еще не видел и не пользовался – это просто бесценная вещь.
Так вот, настраиваем нашу сессию расширенных событий и смотрим, что у нас получается.

Выполняем запрос в 1С. Я взял обычный запрос – прокрутку списка, где подключаются дополнительные справочники, которые выводят значения реквизитов. В результате, в запросе будет несколько соединений – этого уже достаточно, чтобы заставить СУБД обратиться к статистикам.

Смотрим подробно на план и видим, что сверху у нас – индексная статистика (она не подсвечена), а внизу – вот эта непонятная автоматическая статистика. SQL Server понимает, что обычная индексная статистика совершенно бесполезна. Поэтому он начинает перебирать варианты, смотрит, что у нас еще есть, и вот, на счастье, находит автоматическую статистику, которая помогает нам все-таки понять какое-то реальное распределение данных. И таким образом все-таки получить эффективный план запроса.
Получается, именно благодаря автоматическим статистикам у нас запросы выполняются быстро и без многочасовых зависаний..
Я посмотрел на эту картинку, очень порадовался. Вселенная спасена, все классно, запросы работают. Но тут во мне проснулся лесоруб из анекдота. Ну помните, когда мужикам привезли модную японскую пилу. Они озадаченно посмотрели на чудо техники, сначала скормили ей веточку – распилила. Скормили ей брёвнышко – распилила. Дали ей 50-летний дуб – прожужжала, подумала, но распилила. Сунули ей стальной рельс – тут она и встала. «То-то же!» – сказали мужики и успокоились.
Вот я тоже пошел искать этот рельс, потому что ну не может все быть настолько хорошо, где-то должен быть какой-то подвох.
А если нужных статистик нет?
Подвох я, естественно, очень быстро устроил.

Я просто скопировал свою таблицу с 4,5 миллионами записей, создал все индексы, а автоматические статистики создавать не стал – решил посмотреть, что нам на это SQL Server скажет. На скриншоте выше как раз видно, что индексные статистики я здесь все вывел, а кроме индексных статистик ничего нет.
Выполняем запрос в Management Studio. Запрос на удивление выполняется – никаких проблем нет. Смотрим, что у нас попало в нашу сессию расширенных событий.
Вот он наш запрос Select TOP 30 – обычный классический запрос из формы списка, который выгребает какие-то данные:
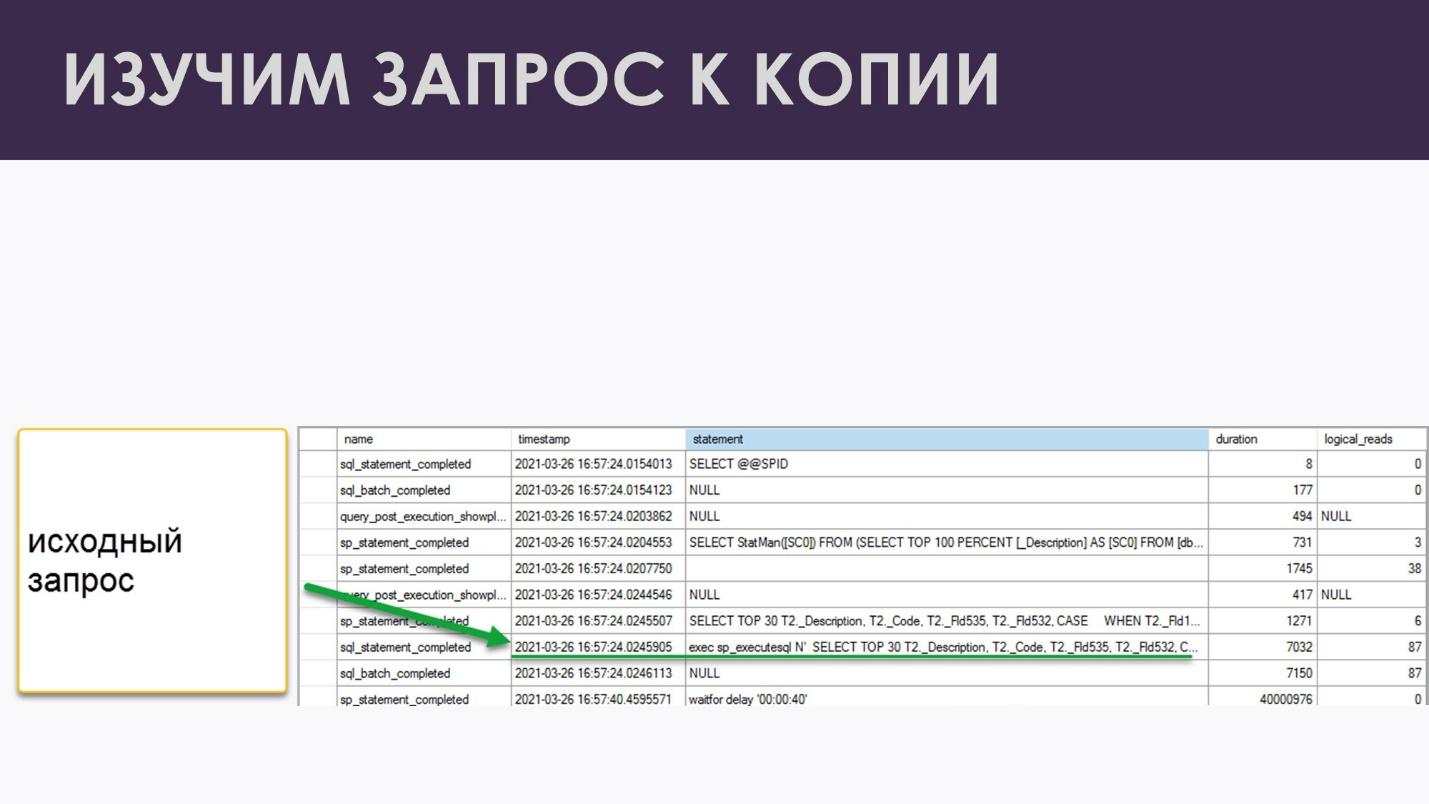
А выше по списку, перед этим запросом – что-то интересное. Этот запрос появился ниоткуда, я его не заказывал, и в нем очень подозрительное слово StatMan.

На самом деле, это – запрос создания автоматических статистик.

Если мы теперь посмотрим на план выполнения запроса, мы опять увидим автоматическую статистику, которой буквально секунду назад еще не было – мы это проверяли по Management Studio.

Получается очень просто – SQL Server видит, что полезных статистик нет, а распределение данных он не знает. И что ему делать? Он может, конечно, просто просканировать всю таблицу, понять после сканирования, что там происходит, и начать строить какой-то план выполнения. Но раз уж он ее просканировал, зачем добру пропадать? Он берет и результат этого сканирования как раз сохраняет в виде статистики. Именно так у нас и создаются автоматические статистики.
Отсюда вывод – если у нас нужных статистик вообще нет, но автосоздание статистик включено, MS SQL их автоматически создаст при первой необходимости.
Какие выводы из этого можно сделать?

Если вы успеваете пересчитывать все ваши статистики за ночь, ничего делать и не нужно. «Лучшее – враг хорошего» или «работает – не трожь» – кому какая формулировка больше нравится.
Серьезно. Не нужно усложнять свой регламент обслуживания заранее. Если вы будете городить какие-то скрипты, потом об них сами же споткнетесь. Пока это работает – пусть работает.

Если вы начинаете новый проект, заводите какую-то новую базу, десять раз подумайте, нужен ли вам разделитель учета. Если он вам не нужен, я вам серьезно рекомендую его удалить, потому что ваши индексные статистики после этого будут работать эффективно – это не будет какой-то бесполезный балласт, который зачем-то у вас место занимает. И всем от этого будет жить легче – и MS SQL Server, и вам тоже. И с обслуживанием, и с сопровождением базы вам потом будет проще.

Если у вас уже большая база, есть разделитель учёта и очень маленькое регламентное окно и вы уже не успеваете пересчитывать все ваши статистики, тут выбор очень простой. Вы можете просто пропустить все индексные статистики, где используется разделитель учёта. Серьезно. От них нет никакого толку, пересчитывать их не нужно. Я бы еще рекомендовал здесь автоапдейт статистик отключить, чтобы эти автоматические статистики даже стали случайно не пересчитывались.

И еще одна, последняя рекомендация – очень важная, особенно для больших баз. Если у вас обновление конфигурации производится по классике и используется реструктуризация первого типа (т.е. мы не используем этот новый модный тип, когда у нас вызывается ALTER TABLE), тогда в результате обновления у вас создаются новые таблицы, и в них переливаются данные. В итоге получается картинка, как на моем втором эксперименте, когда данные есть, а автоматических статистик нет. И это очень хорошая причина, чтобы сразу после реструктуризации заранее выполнить все ваши топовые запросы:
-
вы прогреете кеш, у вас все данные сразу в оперативку поднимутся;
-
плюс вы сразу создадите автоматические статистики, и ваши пользователи не будут ждать и тратить время на их создание.
*************
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.
|
30 мая - 1 июня 2024 года состоится конференция Анализ & Управление в ИТ-проектах, на которой прозвучит 130+ докладов.
Темы конференции:
Конференция для аналитиков и руководителей проектов, а также других специалистов из мира 1С, которые занимаются системным и бизнес-анализом, работают с требованиями, управляют проектами и продуктами!
|