Добрый день. Столкнулся с проблемой, что rphost съедает всю память. До этого грешил на sql, делал ограничения, но понял что проблема в rphost. Из 32гб памяти для одной базы он сжирает 21гб. Перезапуск службы помогает ненадолго.
В инете видел инструкции по ограничению памяти в кластере серверов, но мой кластер от инструкции отличается (Скрин во вложении).
Подскажите как быть, как сделать правильно ограничение.
В инете видел инструкции по ограничению памяти в кластере серверов, но мой кластер от инструкции отличается (Скрин во вложении).
Подскажите как быть, как сделать правильно ограничение.
Прикрепленные файлы:

По теме из базы знаний
- Кластер серверов 1С
- Рецепты приготовления технологического журнала
- Как мы подружили "1С:Аналитику" и "Финансист". Практический опыт
- Как я стал Экспертом по технологическим вопросам за 3 месяца. Часть 2 (обновлена)
- Применение 1С:Аналитики и Дата акселератора, или Как получить в 1С прозрачность и скорость обработки данных для прямого доступа и контроля руководителя
Ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
(1) Для начала можно сделать настройку ТЖ по событию CALL(вызов сервера) и SCALL, у событий есть важные показатели memory и memorypeak. В идеале memory не должен увеличиваться после вызова CALL. Первое чтобы сделал, это нашел по событию CALL контексты с наибольшим значением memorypeak. Если затрудняетесь с настройками ТЖ, пишите в личку, помогу настроить
Проблема не в rphost, а в кривом коде написанном где-то в недрах вашей конфигурации. Найти этот кривой код можно анализируя технологический журнал.
Настройки вы видите не те потому что нет у вас функционала КОРП, который раньше был у всех, а теперь доступен немногим.
Настройки вы видите не те потому что нет у вас функционала КОРП, который раньше был у всех, а теперь доступен немногим.
(3)В 8.3.19
Значение свойства рабочего сервера кластера Временно допустимый объем памяти процессов используется и для перезапуска рабочих процессов по памяти и для управления прерыванием объемных вызовов. Данное свойство допускается использовать с лицензией уровня ПРОФ.
можно ограничить память для rphost
(4) а вот этого делать не надо. Один кулибин так сделал - ограничил потребление RPhost-а 10-ю гигабайтами. Каждый день были жалобы на тормоза сервера, приходилось ежедневно перезапускать службу. Несколько дней, а то и недель пришлось потратить на расследования, пока не стало ясно, что тормоза приходятся на "плато" потребления памяти процессом РПхост (упирался в 10 гигов, судя по мониторингу и в этот-то момент все жаловались на тормоза). Полез в настройки кластера 1С и увидел там это ограничение - тут же его снял. Больше жалоб не было. Пусть себе растет сколько ему надо. Уж лучше перезапуск рабочих процессов настроить в таком случае, если есть нарекания на размер потребляемой памяти, если нет возможности пока разобраться в истинных причинах
(3)Код конфигурации это миллионы строк. Доработки тоже могут быть большими.
Бесполезно смотреть на код, нужно смотреть на технологический журнал. Он покажет каким кодом память была использована и потом не освобождена.
Если слова "технологический журнал" ни о чем не говорят - можно их загуглить и открыть для себя мир технологической экспертизы в 1С. Ну или позвать специалиста.
Бесполезно смотреть на код, нужно смотреть на технологический журнал. Он покажет каким кодом память была использована и потом не освобождена.
Если слова "технологический журнал" ни о чем не говорят - можно их загуглить и открыть для себя мир технологической экспертизы в 1С. Ну или позвать специалиста.
(6) Я совсем недавно с этим флагом напоролся.. Оно вырубает рпхост при слишком большом числе ошибок. А новые конфиги 1С или даже сама платформа, я не выяснял, отсылают куда-то статистику. И вот сервис статистики какое-то время был недоступен. Из-за этого попытки ее отправить выдавали ошибку. А у меня постоянно падали рпхосты, что влияло на работу пользователей по итогу.
(8)Хмммм, относительно месяца 2 назад включил перезапуск процессов (время зависит от технологических процессов базы) + завершение проблемных ресурсов . Нагрузка упала ощутимо, "внезапных" падений нет.
Автор на ИТС вполне доступное описание по основным настройкам сервера(даже оптимизация) + Гугл для актуализации информации.
Если грузится rphost
1. Подумать когда проблема появилась и при каких действиях.
2. Смотрим на сам сервер (системные или аппаратные ошибки, общее состояние системы ) . Ок или правим.
3. Начинаем грешить на админа, проверяем адекватность выделяемых ресурсов под работу сервера и наличие планов обслуживания.
4. Начинаем грешить на программиста и искать "плохой" код.
На практике до 4 пункта не доходило.
Автор на ИТС вполне доступное описание по основным настройкам сервера(даже оптимизация) + Гугл для актуализации информации.
Если грузится rphost
1. Подумать когда проблема появилась и при каких действиях.
2. Смотрим на сам сервер (системные или аппаратные ошибки, общее состояние системы ) . Ок или правим.
3. Начинаем грешить на админа, проверяем адекватность выделяемых ресурсов под работу сервера и наличие планов обслуживания.
4. Начинаем грешить на программиста и искать "плохой" код.
На практике до 4 пункта не доходило.
(9) У нас постоянно доработки 1с, и проблема то появлялась, то пропадала. Планы обслуживания каждую ночь, в sql server настраивали все норм, он не жрет особо. Докинул оперативки 16 гб до 48гб + добавил авторестарт службы, сегодня посмотрим. Если не поможет поставлю "завершение проблемных процессов.

Здравствуйте, напишу свой опыт если ещё актуально. Да, у меня тоже была такая проблема, что rphost сжирал много памяти, потом пользователи начинали отваливаться с ошибкой нехватки памяти на сервере. У нас УТ 11.4 на Postgreee SQL, одновременно работающих пользователей штук 14-20, стоит ПРОФ лицензия сервера 1С, а не КОРП. Есть регламентные задания обмена с интернет магазином и эвотор облаком по заданному интервалу. Опубликована через апач и имеется обмен с 3-мя штуками РИБ и 2-мя другими конфигурациями.
Итак, что я сделал, чтобы rphost не разрастался:
1). Настроил журнал регистрации. Каждый месяц отдельный файл, также в рабочей базе сокращаю ЖР, и оставляю последние 3 месяца. Н всякий случай храню файлы ЖР в отдельном ресурсе.
2). Full vacuum средствами Postgree SQL
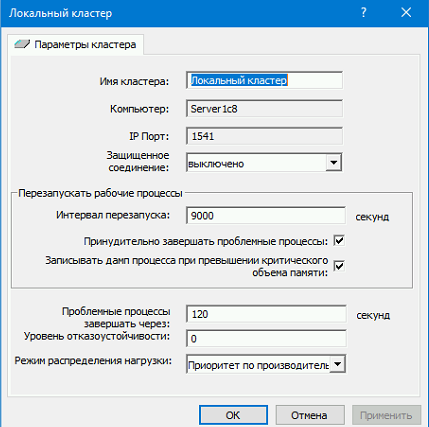
3). Настроил кластер (см. рис во вложении)
Итак, что я сделал, чтобы rphost не разрастался:
1). Настроил журнал регистрации. Каждый месяц отдельный файл, также в рабочей базе сокращаю ЖР, и оставляю последние 3 месяца. Н всякий случай храню файлы ЖР в отдельном ресурсе.
2). Full vacuum средствами Postgree SQL
3). Настроил кластер (см. рис во вложении)
Прикрепленные файлы:
Попробуйте платформу обновить.
Была проблема, что на сервер 1с съедал почти всю оперативку (110 из 128гб) и еще проблемы были с зависанием. Короче неудачная версия для нас оказалась. Что только не пробовал и ТЖ смотрел.
Платформа 8.3.20.2180 была вроде.
А потом обновил на 8.3.21.1709. Теперь больше 50гб не съедает и зависания пропали.
Была проблема, что на сервер 1с съедал почти всю оперативку (110 из 128гб) и еще проблемы были с зависанием. Короче неудачная версия для нас оказалась. Что только не пробовал и ТЖ смотрел.
Платформа 8.3.20.2180 была вроде.
А потом обновил на 8.3.21.1709. Теперь больше 50гб не съедает и зависания пропали.
(30)Нормально. 99% завершаются за 10минут-час.
Но вам надо проверить редко запускаемые тяжелые фоновые. Например, закрытие месяца. Лет 5 назад на ERP оно крутилось 1,5 суток, и что кластер его не "рубил" пришлось выставить интервал в 2 суток. Но это скорее особенность той базы.
Но вам надо проверить редко запускаемые тяжелые фоновые. Например, закрытие месяца. Лет 5 назад на ERP оно крутилось 1,5 суток, и что кластер его не "рубил" пришлось выставить интервал в 2 суток. Но это скорее особенность той базы.
Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот