
Несколько слов о себе. Все меня знают, как автора множества статей для Инфостарта. Сейчас этих статей 42. Это волшебное число. Недавно 42, наконец, смогли разложить на три куба – оно было последним среди чисел от 1 до 100. Следующее интересное число – 73, поэтому я надеюсь достичь и этой цифры.
Статьи все разные. Многие были приняты с большим интересом, хотелось бы, чтобы так же стало с докладом.

Кроме того, что я автор Инфостарта, в жизни я директор небольшой франчайзинговой фирмы. Мы в Московском регионе уже 20 лет занимаемся автоматизацией промышленных предприятий на платформе 1С.
На слайде в центре – наши программисты. Остальные фотографии – это наши заказчики. Они тут представлены с высоты птичьего полета. Видно, что это – большие, крупные фирмы. Наши заказчики подкидывают нам интересные задачи.
Интересные задачи

Интересные задачи не появляются просто так. Их нужно искать и уметь находить. У нас глаз уже пристреленный, и мы видим эти задачи. В основном, потому что у нас сотрудники – это люди с научным прошлым. В том числе, и я. И мы стараемся находить задачи, которые соответствуют нашему профессиональному опыту.
Частью этих задач я делился – например, задача про трехмерную упаковку, двумерный раскрой, поиск маршрутов, оптимизацию производственной программы, планирование перевозок… Это все, что мы запрограммировали, все, что работает у наших клиентов.
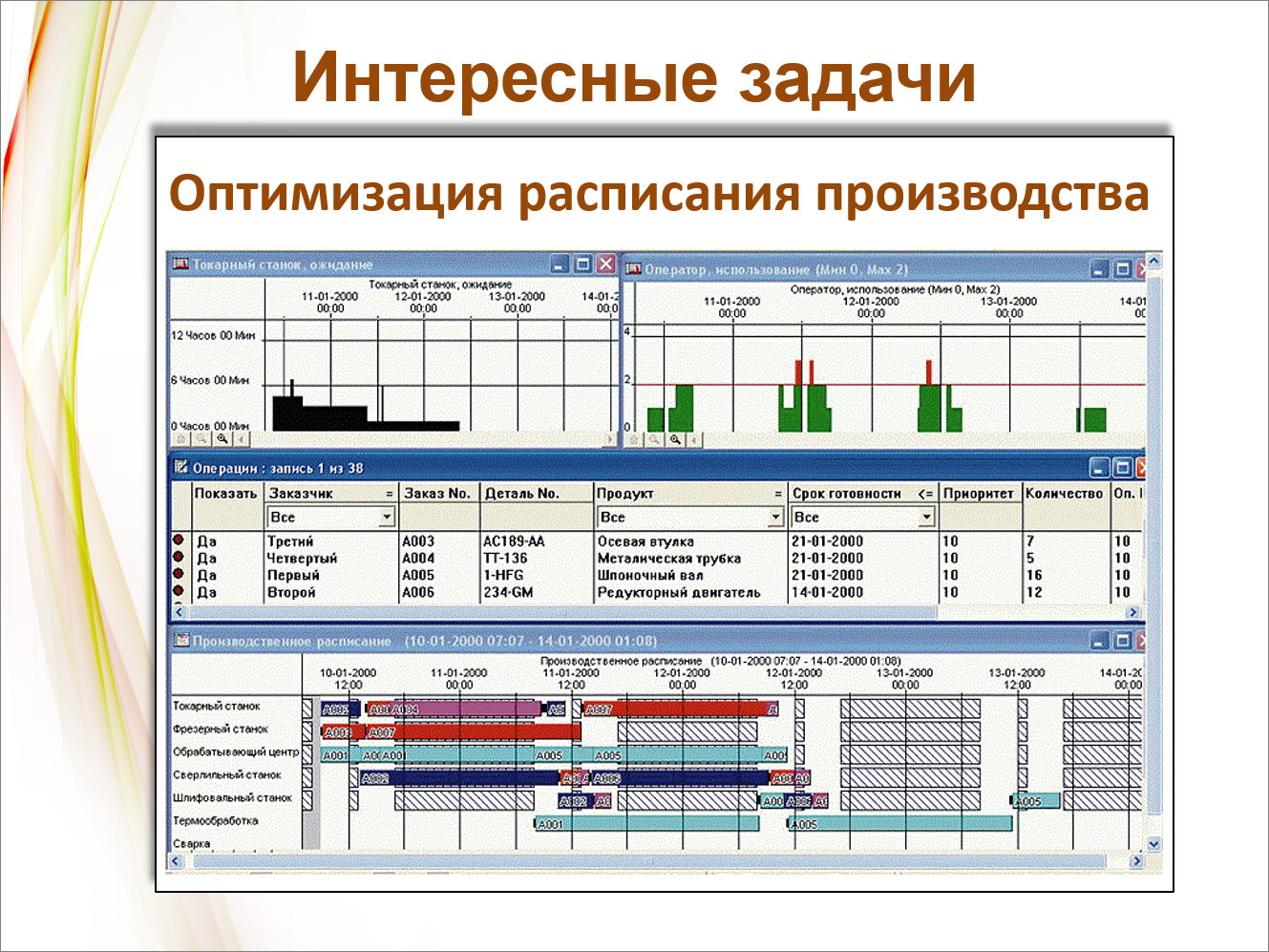
И вершина сложности, которую мы решили на сегодняшний день – это задача оптимизации расписания производства. О ней я и хотел бы сейчас рассказать.
История разработки системы оптимизации расписания производства
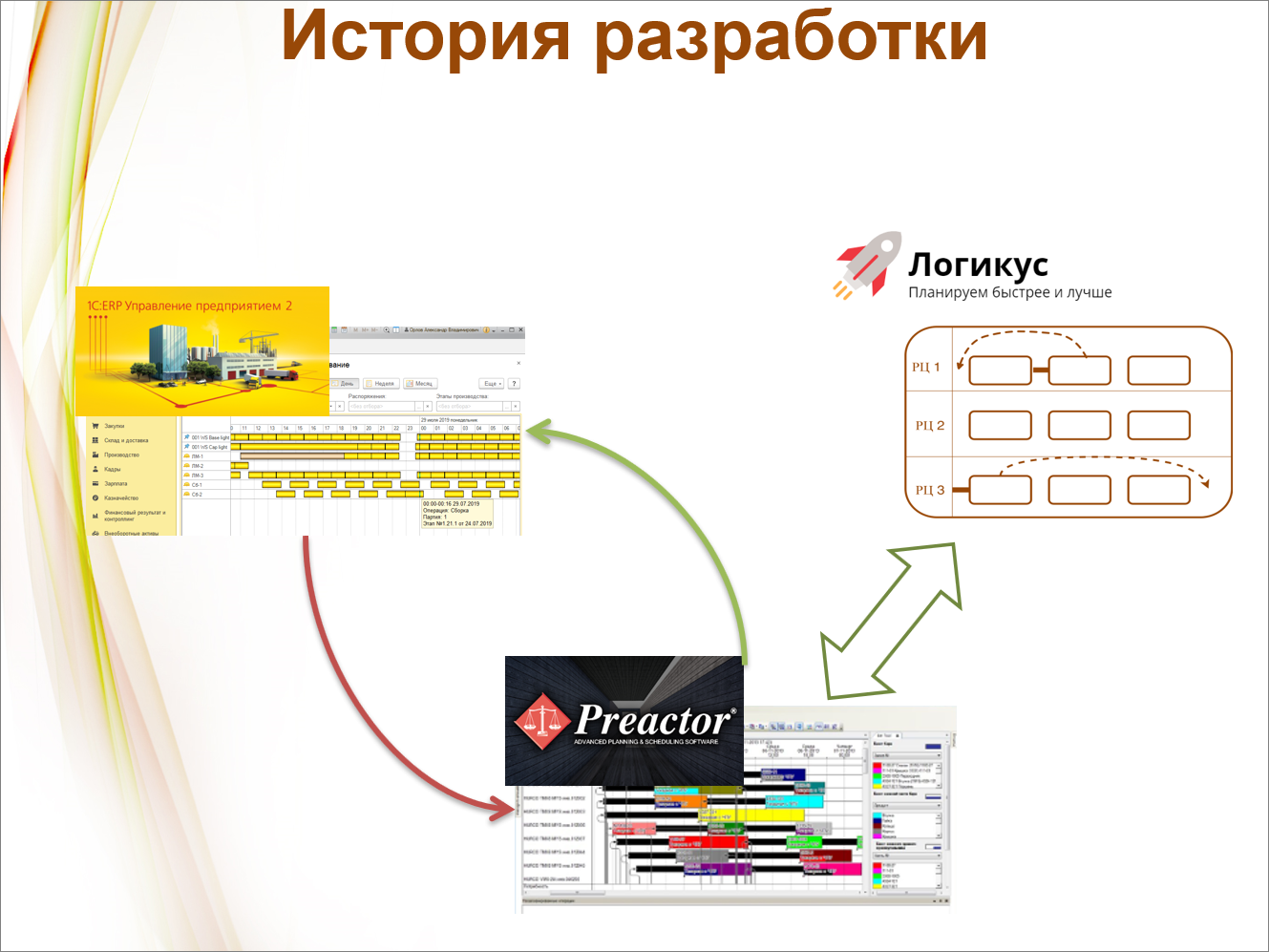
Мы участвовали в большом проекте на крупном машиностроительном предприятии, с интенсивным многопередельным производством и с большим количеством заказов, в каждом из которых было большое количество операций. Внедрялось 1С:ERP, но производственное планирование в нем «не тянуло» тот объем данных, который требовался заказчику.
Тогда заказчик приобрел систему Preactor и стал планировать уже в ней. Это импортная система составления расписания, ее, возможно, многие знают. Тем не менее, те критерии, которые требовались заказчику, система Preactor тоже не отрабатывала.
Нас попросили разработать для системы Preactor небольшой плагин (она позволяет это делать), чтобы улучшить работу с переналадками. Мы это сделали, но при этом недооценили объем работ и в результате потратили гораздо больше времени. В общем-то, сделали мини-Preactor – задублировали все объекты, которые в нем есть, всю систему ограничений. Кодовая база разрослась, терять ее стало жалко, тем более что, когда дедлайнов нет, разрабатывать всегда интересно. И мы решили нашу систему развить, усовершенствовать, чтобы вообще убрать необходимость использования системы Preactor.
Теперь наша система позволяет составлять производственное расписание напрямую в ERP.
Планирование в ERP
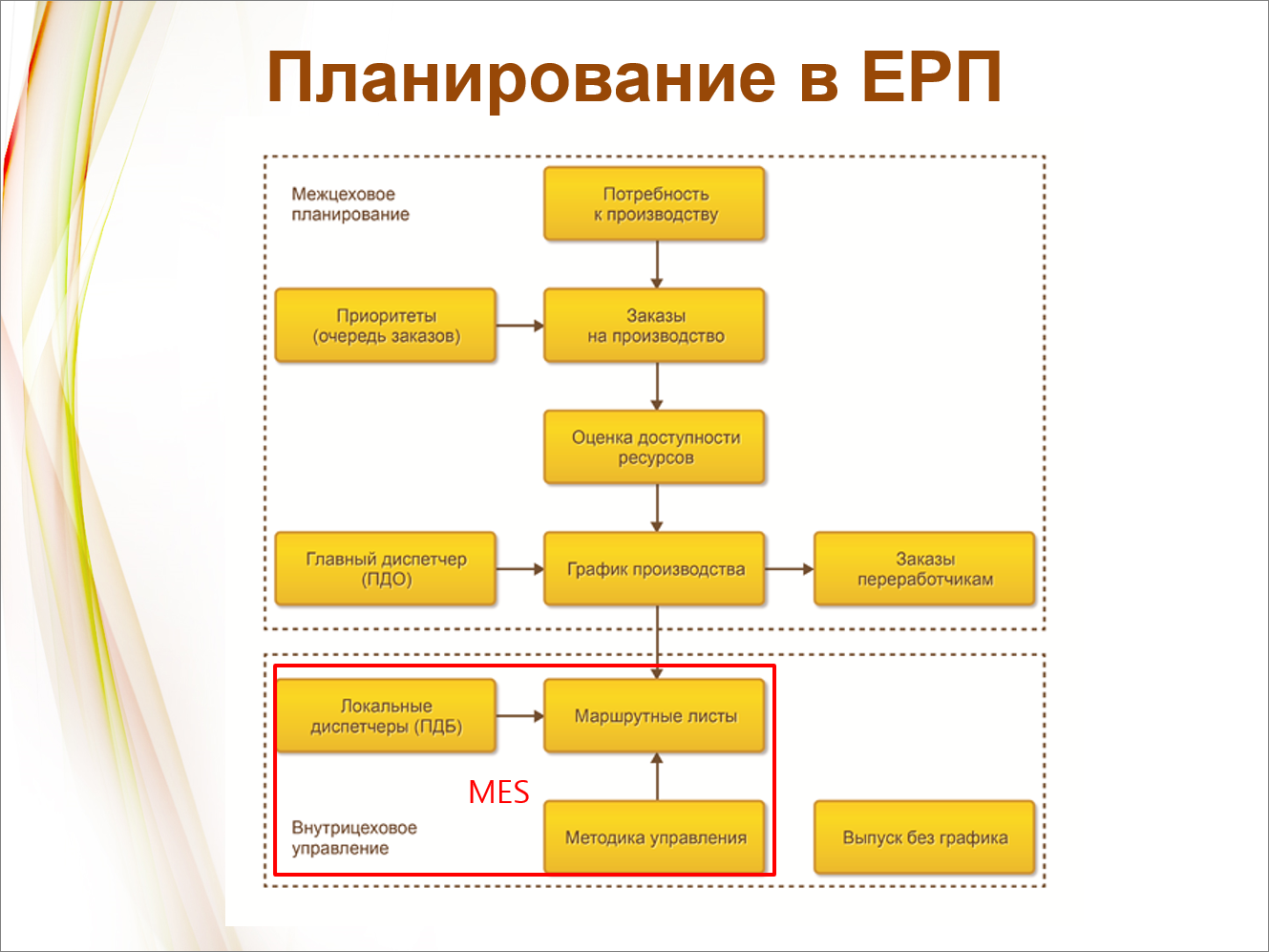
Как в ERP устроено планирование?
Надо сказать, что по сравнению с УПП планирование в ERP сделало очень большой шаг вперед. Если изучить мировой опыт построения систем планирования, то наиболее развиты APS-системы, которые осуществляют планирование в масштабе предприятия, планируют по-крупному. А планирование в деталях, с привязкой к минутам и секундам в масштабе всего предприятия сделать невозможно из-за большого количества возмущений. И 1С очень точно угадала с тем, что сделала двухуровневую систему:
-
На верхнем уровне работает глобальный диспетчер – согласно теории ограничений систем по методу «Буфер-Барабан-Веревка» разбрасывает задания по цехам.
-
А дальше на нижнем уровне эти задания исполняются как хотят – там уже все конкретно, задания уже более детализированные, и интервал меньше, и задания меньше, и зависят они от меньшего количества факторов. Уже вступает цеховой уровень планирования, на котором отдельные операции уже можно привязать ко времени. И мы на этом уровне для MES-планирования сделали свою разработку.
Возможно, вы обратили внимание, что во всех обучающих роликах или лекциях по MES, когда преподаватель показывает построение расписания в ERP (даже на небольшом примере, в котором 10-20 операций), он нажимает на кнопку и довольно долго ждет, когда это расписание построится, хотя это всего лишь учебный пример. Естественно, ждать никто не любит, поэтому стандартной возможностью построения расписания в ERP заказчики вряд ли интенсивно пользуются. Хотя, может быть, у вас другое мнение.
Исходя из этого, складывается ощущение, что система MES в ERP была написана «для галочки» просто для того, чтобы она там была. И в реальных приложениях она, скорее всего, не работает, потому что осуществлять планирование можно десятком других способов, в том числе и вручную. Но если действительно хочется это автоматизировать, то нужно что-то думать. Поэтому мы сделали такой шаг вперед, чтобы появилась возможность построить расписание производства для практических случаев.
Что такое расписание производства

Проблема построения производственного расписания возникла давно, и был человек – Гантт Генри Лоуренс, который занимался организацией производства (вы все его хорошо знаете по фамилии, потому что так называется диаграмма), он описал вот такие требования к расписанию – где оно должно составляться, кем выполняться. Эти требования так и называются, «Принципы Гантта».
И, если посмотреть в Википедии, как расшифровывается термин «Расписание», то там тоже написано, что это разновидность календаря, где указано, в какой момент, где и что должно делаться.
Получается, что расписание производства – это производственные операции, привязанные ко времени и месту их выполнения.
-
Если расписание большое, операций много (в нашей системе обрабатываются десятки тысяч операций), то удержать их в голове, нанести на один лист и просмотреть бывает сложно. Нужна автоматизация.
-
Во-вторых, получается, когда мы строим расписание, мы обязательно должны учитывать ограничения – например, у нас один станок в одно и то же время не может выполнять две отдельные операции. И производственный персонал тоже не может быть в 10 местах одновременно, как Фигаро. То есть, расписание – это не просто набор операций, этот набор должен удовлетворять весьма большому количеству ограничений.
-
В-третьих, расписание можно построить множеством способов, и разные расписания будут отличаться друг от друга – одно будет хорошим, второе – плохим, или вообще не будет укладываться ни в какие рамки. То есть, кроме того, что расписание должно удовлетворять системе ограничений, оно должно еще и отличаться качеством, которое также должно иметь какое-то числовое выражение.
Учитываемые при построении производственного расписания ограничения

Какие ограничения должна учитывать наша система:
-
Порядок выполнения операций, потому что, пока полуфабрикаты не готовы, следующая операция начаться не может. Здесь приведены математические обозначения для уточнения нашего словесного описания – что от порядка операций зависит время их выполнения.
-
Также должно учитываться, что каждая операция потребляет какие-то ресурсы, материалы, эти материалы должны к моменту начала операции быть уже подвезены или с самого начала иметься на складе – тут сумма остатков плюс накопленный итог – это запросом можно посчитать.
-
Должны быть доступны рабочие центры.
-
Должны быть доступны вспомогательные рабочие центры. Кто пытался разбираться в НСИ ERP, тот все эти названия и термины знает, мы здесь просто немного строже их описали.
-
Рабочие центры обычно работают не круглосуточно, а по какому-то определенному графику – он тоже должен учитываться.
-
А вообще мы очень часто сталкиваемся с тем, что в наши замыслы вносятся возмущения, и для того, чтобы с ними бороться, нужен запас прочности и запас по времени. Поэтому должны учитываться резервы доступности – если что-то сломалось или что-то не довезли, нужно время, чтобы это можно было исправить.
-
Также у нас должны учитываться различные вторичные ограничения, наподобие площади покрасочной камеры, объема гальванической ванны, в зависимости от которых мы сможем параллельно загружать операции.
Критерии оценки расписания

Какие критерии влияют на качество построенного расписания:
-
Чаще всего обращают внимание на то, что все должно быть сделано вовремя. То есть, коммерческие предприятия должны выполнять заказы в срок. А если вдруг мы их в срок выполнить не можем, то это отставание должно быть минимальным. Время просроченности заказов – это один из критериев.
-
Кроме этого мы учитываем количество просроченных заказов.
-
Также нужно учитывать, что время рабочих центров может использоваться не целенаправленно – например, на переналадку, когда нужно прекратить одну операцию и начать следующую, а за это время поменять настройки и инструменты. Например, если бы мы хотели послушать все доклады, нам пришлось бы бегать, «переналаживаться» от одного доклада к другому, а если бы все, что нас интересует, шло бы подряд и в одном месте, мы тратили бы меньше времени на «переналадку».
-
Также на качество расписания влияет равномерность загрузки рабочих центров. Иногда удивляешься, что рабочие при планировании расписания обижаются: «Почему меня забыли, почему меня никто ничего не просит делать?» Это удивительный факт, когда приходится сталкиваться с буквальными обидами, человек думает, что его сократят, он хочет, чтобы ему тоже попадали задачи. И если под рабочим центром понимать производственный персонал, то равномерная загрузка рабочих центров тоже является критерием.
-
Также влияет стоимость выполнения производственной программы. Понятно, что на одном и том же станке разные операции можно делать быстро/дорого или медленно/дешево.
-
Кроме стоимости влияет общее время выполнения – здесь приведены формулы, можете их посмотреть.
-
А чаще всего используется комплексный критерий, когда мы не можем выбрать ни один из этих критериев, их всех смешиваем, чтобы получить какую-то их взвешенную сумму, и все они участвуют в формировании общей оценки – как средний балл у человека.
Сложность задачи

Вообще задача сложная.
-
Помните мою статью про трехмерную упаковку? Попробуйте сами сложить все эти коробочки так, чтобы между ними осталось меньше места. Есть огромное количество разных способов, и все время оказывается, что туда больше ничего нельзя запихнуть. Но, поскольку в трехмерной упаковке ограничений только три – по высоте, ширине и глубине, а в задаче построения производственного расписания ограничений больше – поэтому она сложнее.
-
В ERP используется однопроходной алгоритм – когда мы выложили на доску какую-то операцию, зафиксировали это решение и поменять его уже не можем. Хотя, может быть, в самом конце мы увидим, что определенный шаг решения у нас был неудачным. Просто не хватает времени, чтобы принятое решение пересмотреть. Так оптимальное расписание не построить.
-
Нет общей модели и общего метода решения. Многие люди думают, что мы сейчас возьмем задачу, полистаем книжки, посмотрим, найдем соответствующий нашему названию метод, разберемся и решим его. Но общий метод решения зависит от того, как сформулировано ограничение: если целевая функция линейная, то это один метод, если целевая функция квадратичная – то второй метод. Если ограничения целочисленные – третий метод и т.д. А клиент хочет все и сразу. И получается, что общего метода и общей модели нет. Это – очень сложно. И поэтому академические, высокоэффективные суперсложные решения здесь плохо работают.
-
Большинство методов в условиях сформулированных ограничений – NP-полные. Это означает, что мы, не перебрав все возможные расписания, самого лучшего решения не получим. А когда мы выстроим все операции в цепочку, у нас количество возможных расписаний станет равным факториалу (n!) – это очень много. Если операций три – это шесть, если пять – 120, если их сто – это уже больше, чем атомов во вселенной.
-
Любое небольшое изменение условий переводит задачу в другой класс, требуя от нас других методов решения.
-
Требуется большой объем вычислений. И хотя раньше мне казалось, что 1С может решить все, если исхитриться и что-то изобрести – в данном случае это не срабатывает. На стороне 1С такой большой объем вычислений производить нецелесообразно.
Метод решения – эволюционный генетический алгоритм

Тем не менее, мы выбрали метод решения. В его основе – эволюционный генетический алгоритм. Его достоинства:
-
он легко перестраивается на решение других задач;
-
легко добавить или изменить систему и форму ограничений;
-
легко добавить или изменить критерии;
-
он хорошо распараллеливается.
Есть и недостатки – это нестабильность, когда, запустив алгоритм на выполнение второй и третий раз можно получить разные расписания. С этим нужно как-то технологически, организационно бороться.
Время показало правильность нашего выбора, потому что ТЗ, с которого мы начинали, многократно уточнялось. И если бы та модель, которую мы выбрали, была строгая, то предлагаемый нами метод давно бы перестал работать. А так мы с задачей все-таки справились.

Если говорить о сущности нашего метода, то как он устроен:
-
У нас есть вариант расписания – это как индивидуум (какой-то зверек, животное в длинной цепи эволюции).
-
Совокупность этих расписаний у нас соответствует популяции.
-
Индивидуумы в ходе эволюции друг друга воспроизводят, в процессе этого они меняются под воздействием мутаций, скрещиваются, лучшие черты родителей переходят потомкам, отбираются – получается все, как в жизни.
-
Собственно говоря, в некотором смысле наши занятия математикой, или прикладной математикой, или просто программированием подтверждают наши общие жизненные установки, общие представления. Нашей работой как будто подтверждается теория эволюции.
-
И что касается небольших подробностей – в эволюционных алгоритмах есть понятие генотипа и фенотипа. Генотип – это последовательность операций. Привязываем каждую операцию к рабочему центру. И на одном рабочем центре выстраиваем последовательность операций, не фиксируя времени выполнения конкретной операции, которое дали в фенотипе (после интерпретации мы получаем фенотип).
-
А фенотип – это расписание с привязкой операции по времени. Оно определяется уже в процессе интерпретации, когда мы применяем ограничения.
Общая схема эволюционного алгоритма
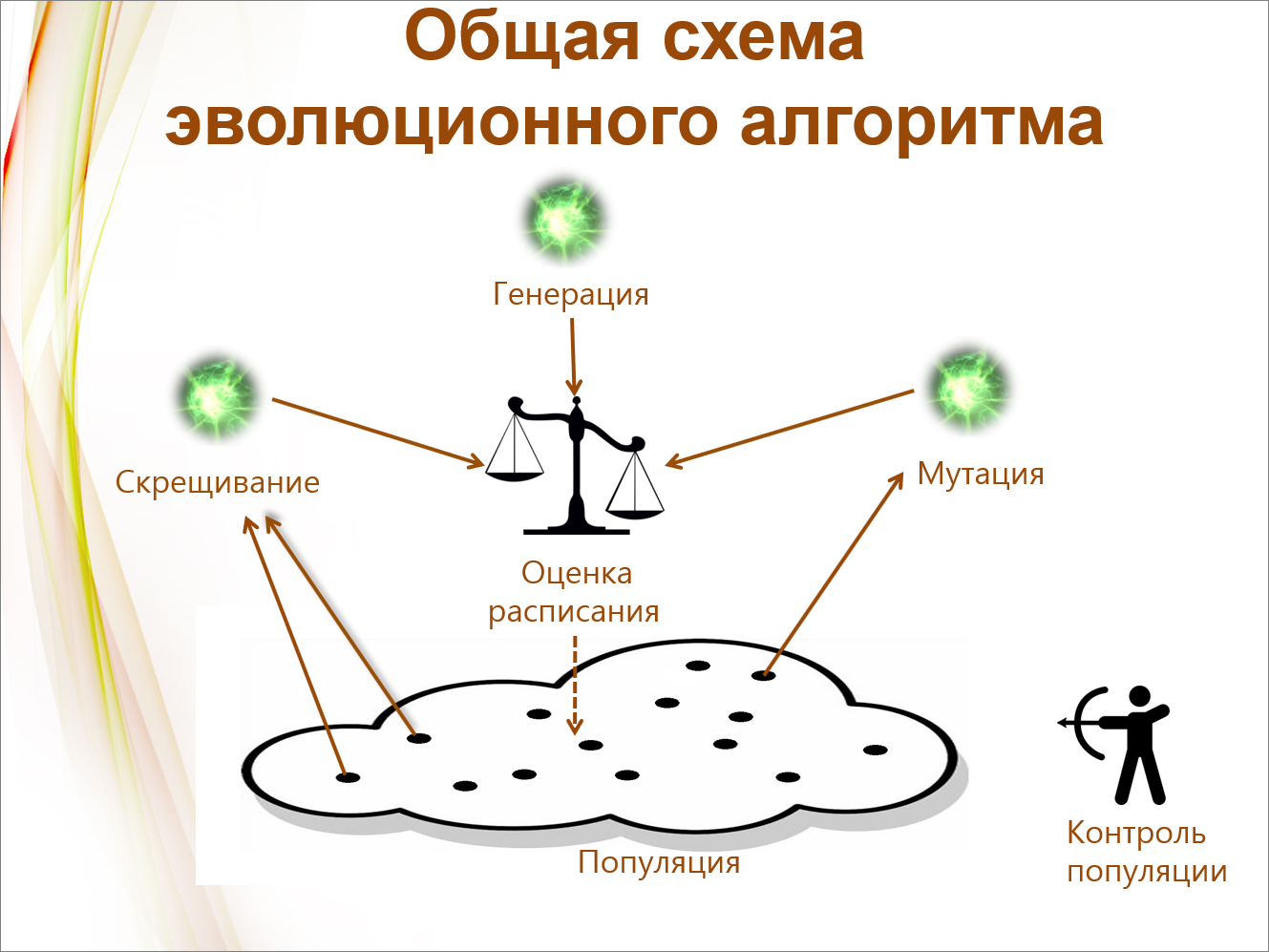
Общая схема эволюционного алгоритма выглядит таким образом:
-
У нас имеется популяция – генерируется набор случайных или предварительно сформированных ручным способом расписаний.
-
Каждое расписание получает оценку по соответствующему критерию, и помещается в популяцию с этой оценкой.
-
Далее может производиться мутация – берется расписание, в него вносятся небольшие изменения, после чего оно оценивается и снова помещается в популяцию.
-
Или расписание подвергается скрещиванию – берется два родителя, их операции каким-то образом смешивается, и также получается потомок.
-
Плохие расписания отбраковываются – производится контроль популяции.
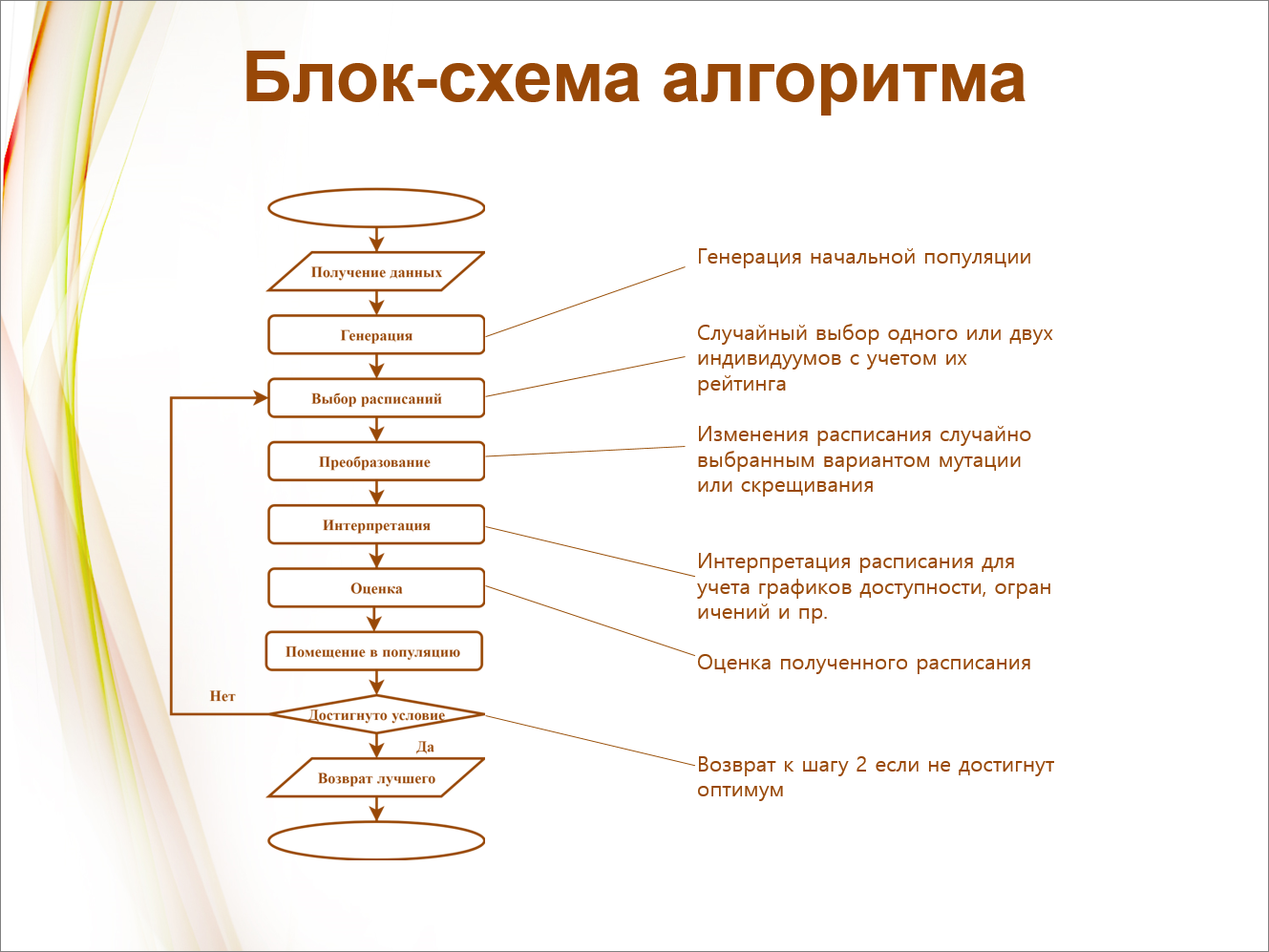
Вот так у нас это изображено на блок-схеме. Получение данных, генерация начальной популяции, выбор расписаний, преобразование, интерпретация, оценка – все в соответствии с блок-схемой.
Применяемые методы мутаций и скрещиваний

Надо сказать, что мы жалеем вычислительные ресурсы и не стали идти как в природе и делать случайные мутации. В нашей системе мутации – это эвристики. Пример этих эвристик приведен. Например:
-
мы переносим на ранние сроки операции запаздывающих заказов;
-
группируем операции с минимизацией переналадок;
-
переносим операции на другой РЦ с усреднением загрузки группы РЦ и т.д.
В зависимости от заказчика у нас есть определенный расширяемый набор этих эвристик. Мы испытываем их результативность на конкретных тестовых данных и помещаем результат в популяцию уже с условием, что есть какая-то оптимизация.
По мере необходимости эвристики дополняются или исключаются. Используется статистика их результативности, нерезультативные мы не используем.

И скрещивания – их набор чуть победнее. Тем не менее, тоже не одно.
Реализация многопоточности
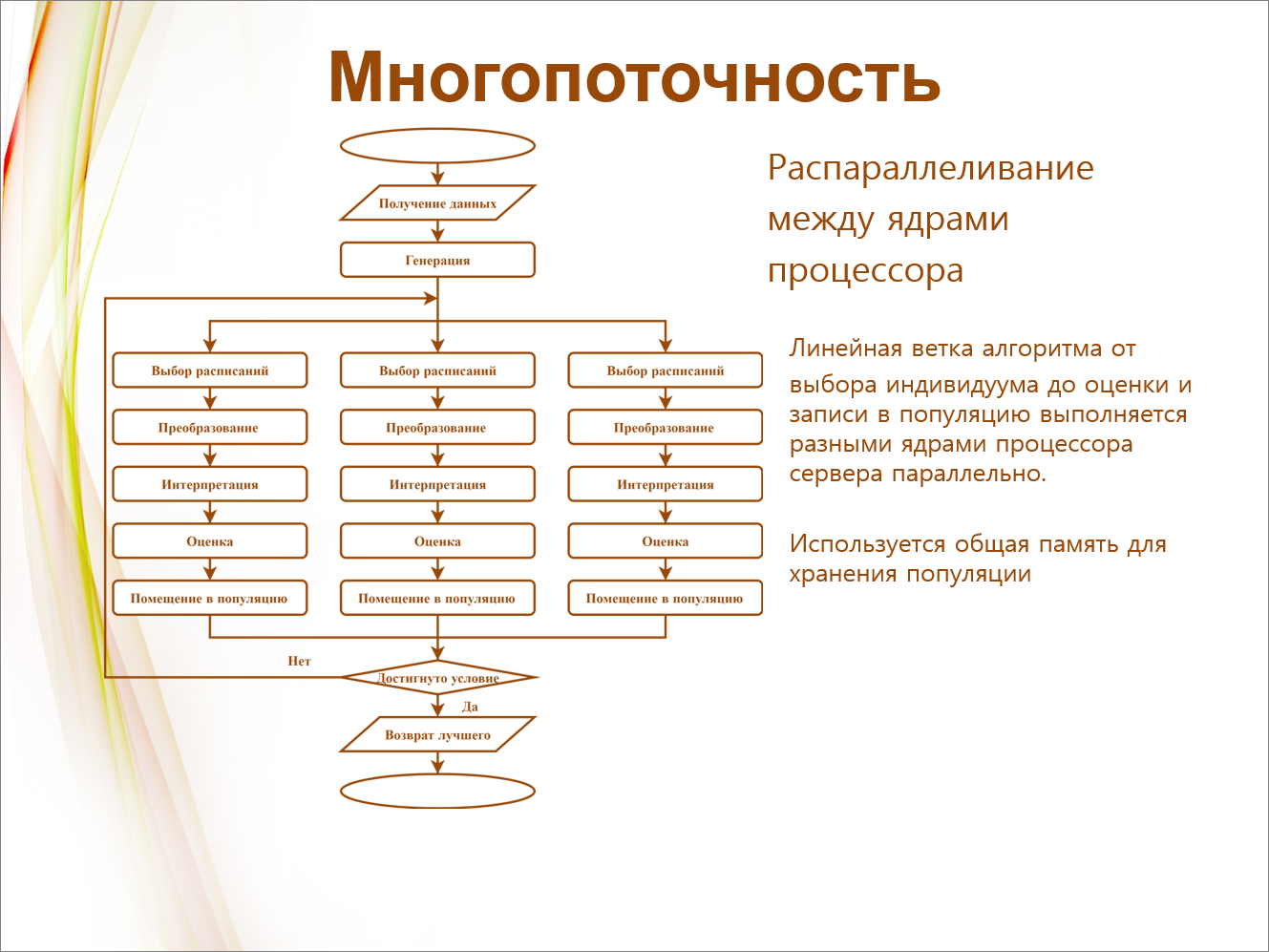
Кроме того, уже после окончания проекта мы этот алгоритм распараллелили по ядрам процессора. У нас имеется общая память, где хранится популяция, и каждая веточка алгоритма выполняется параллельно, отдельным ядром.
В результате мы получили практически линейное ускорение в 8 раз (у нас было 8 ядер). Если бы ядер было 16, было бы ускорение в 16 раз – мы пока не ощутили достижения предела на наших мощностях.
Сложности, возникшие при реализации
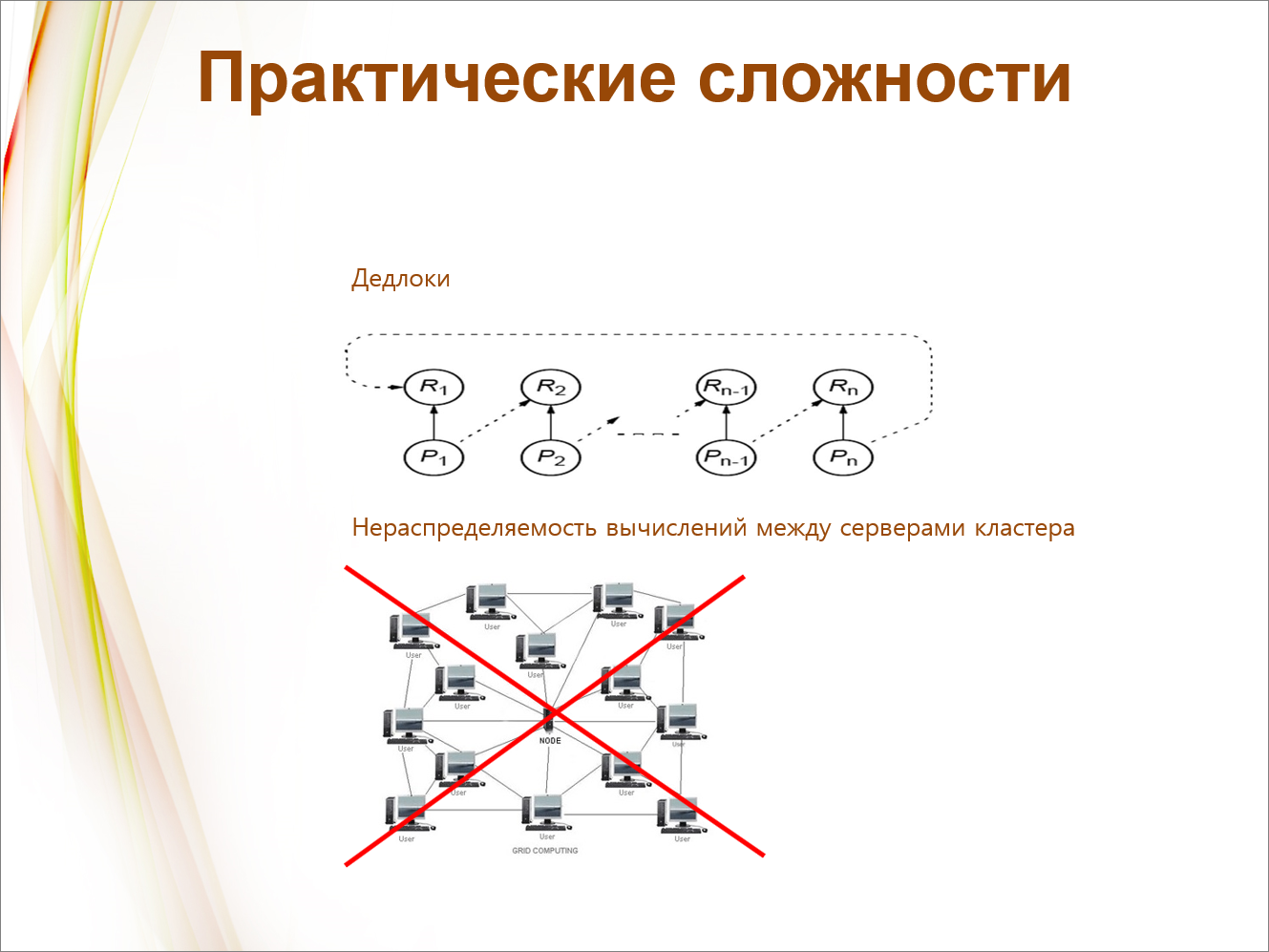
Какие у нас сложности возникали, как мы их преодолевали?
Когда у нас получается генотип, то фенотип образуется не всегда, потому что эта сгенерированная последовательность может не выжить – может получиться нежизнеспособный мутант. Это происходит за счет дедлоков (типа блокировок в СУБД). Чтобы их развязать, достаточно отбросить какую-то транзакцию, а здесь этого сделать нельзя, поскольку мы очень бережно относимся к сгенерированным нами последовательностям. Развязывание дедлоков – это довольно сложный математический алгоритм. Он тоже NP-полный. Нам пришлось изобретать свой, легкий алгоритм. Но, тем не менее, мы с этим справились, и получилось достаточно интересное решение.
И вот еще интересный момент, который мы здесь отметили – когда я давно занимался 3D-упаковкой, у меня было ощущение, что мы возьмем и распределим задачи по одному серверу кластера, второму, третьему, четвертому, и получим пропорциональный рост. То есть, после достижения этой полочки (количества ядер, по которому мы распараллелили алгоритм) мы таким же образом распределим между серверами.
Но оказалось, что мы здесь ошиблись и получили отрицательный результат. Но отрицательный результат для науки – это тоже результат, поэтому я хочу им с вами поделиться.
Мы, получается, очень долго не могли понять. Провели работу, у нас были SOAP-сервисы запущены для того, чтобы обмениваться между серверами. И не получаем мы ускорение. Оставляем на ночь, на воскресенье, на компьютерах всех разработчиков запускаем. И получается, наоборот, хуже. Почему? Оказывается, есть объяснение. Мы модель построили, чтобы это объяснить. Вкратце, дело в том, что для некоторых разновидностей вычислений обязательно требуется общая оперативная память и быстрый доступ к ней. Иначе передача промежуточных результатов с сервера на сервер съедает весь возможный выигрыш. Для борьбы с этим на суперкомпьютерах есть особые шины. А так просто, как в 1С, добавить сервер в кластер и ускорить вычисления не получиться. Вообще нужно следить за прогрессом в этой области. Когда появятся 128-ядерные процессоры, их нужно покупать. Нужно сказать, что это не только в нашей области решения задач оптимизации, но и в области нейросетевых технологий точно такой же эффект отмечается. Возможно, там другие объяснения. Но это – та вещь, которую мы почувствовали своими руками и поэтому этим хотелось бы поделиться.
Подробности реализации

Что представляет собой наше решение:
-
Оно сделано на C#. Платформа .NET Core.
-
Размер кодовой базы примерно 15 тысяч строк.
-
Обрабатываемые расписания состоят из десятков тысяч операций – у нас встречалось 13-15 тысяч.
-
В результате построения одного расписания мы получаем десятки тысяч вариантов. Бывает 5 тысяч, бывает 15 тысяч. Когда мы запускали пример на неделю, там могли быть и миллионы.
-
Конечно, наше решение показывает гораздо более высокую скорость, чем встроенные методы в ERP. На несколько порядков (на три, наверное).
-
И показывает лучшие результаты при том же самом времени.
-
Также оптимизирует переналадки – наш метод работает в гораздо более широком диапазоне условий.

Мы оформили наше решение как расширение, которое добавляет кнопку в окно расчета расписания производства продукции.
Сам расчет может запускаться на отдельном сервере, а обмен идет через общую папку или через FTP.
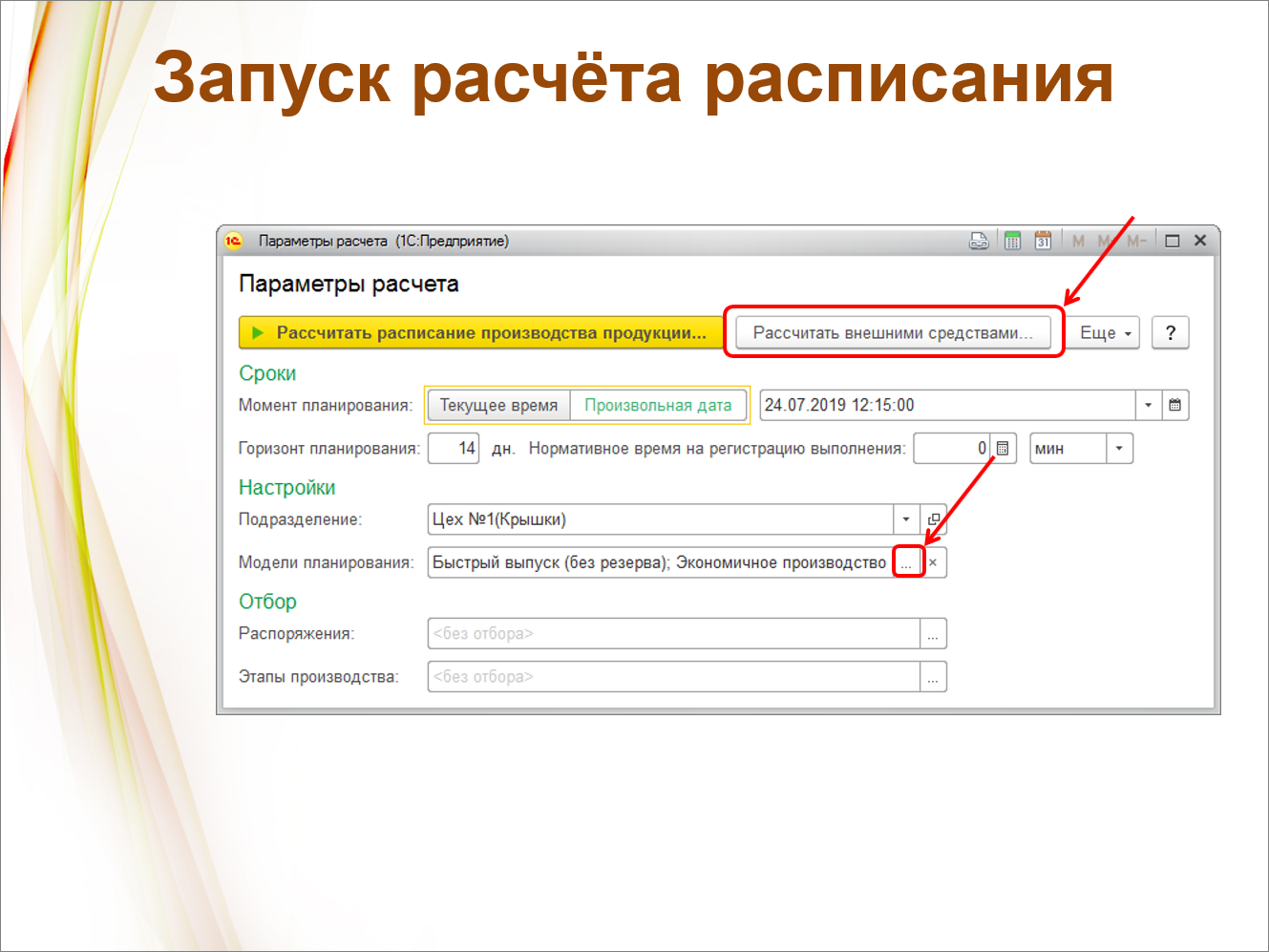
Вот пример вызова. Тот, кто работал с MES, это окно знает. Сюда добавлена возможность расчета внешними средствами.
Вы видите, что в качестве ограничений используются те же самые модели планирования. За небольшими исключениями мы поддержали фактически всю функциональность, которая есть в ERP.
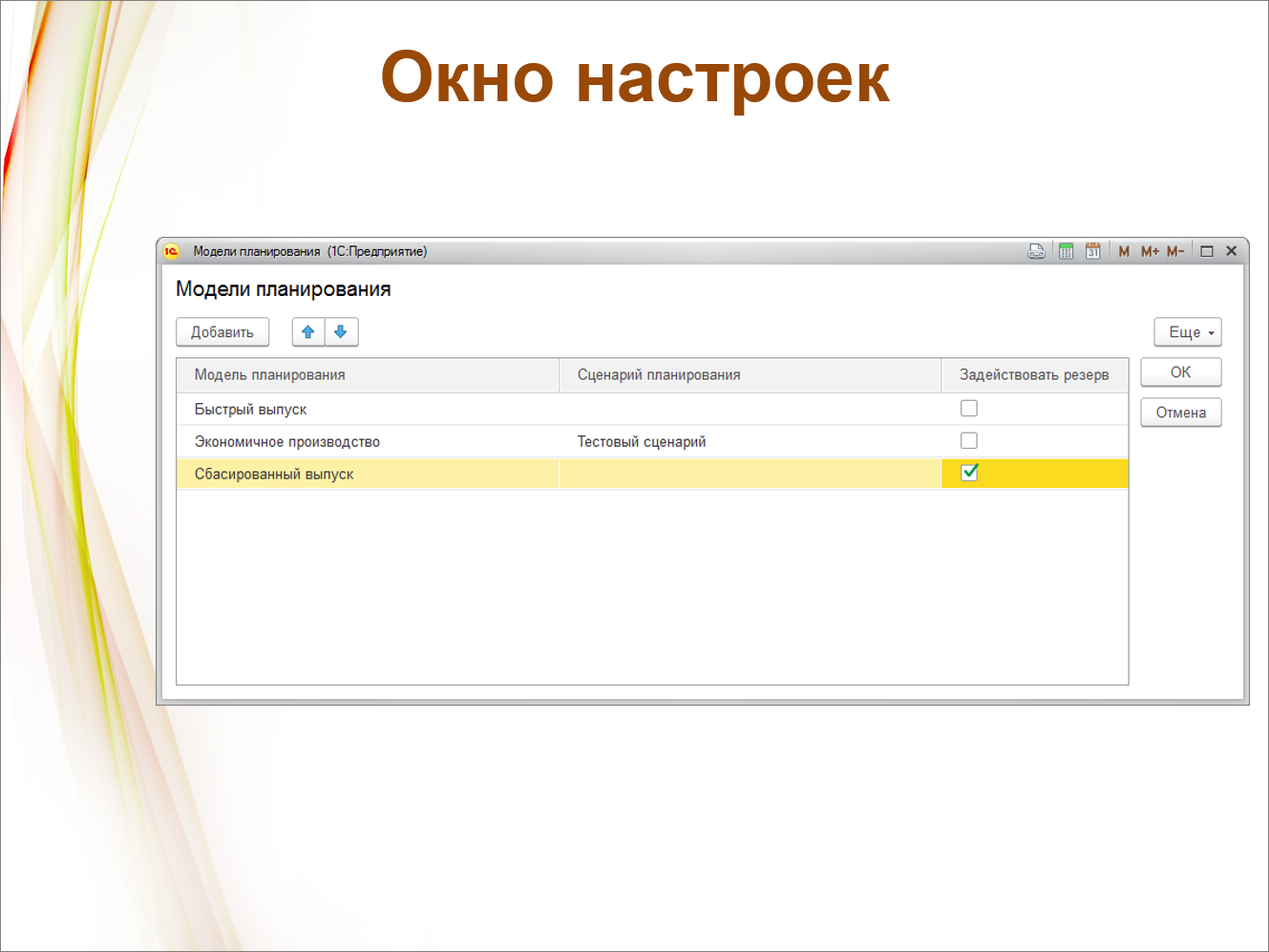
Есть окно настроек.
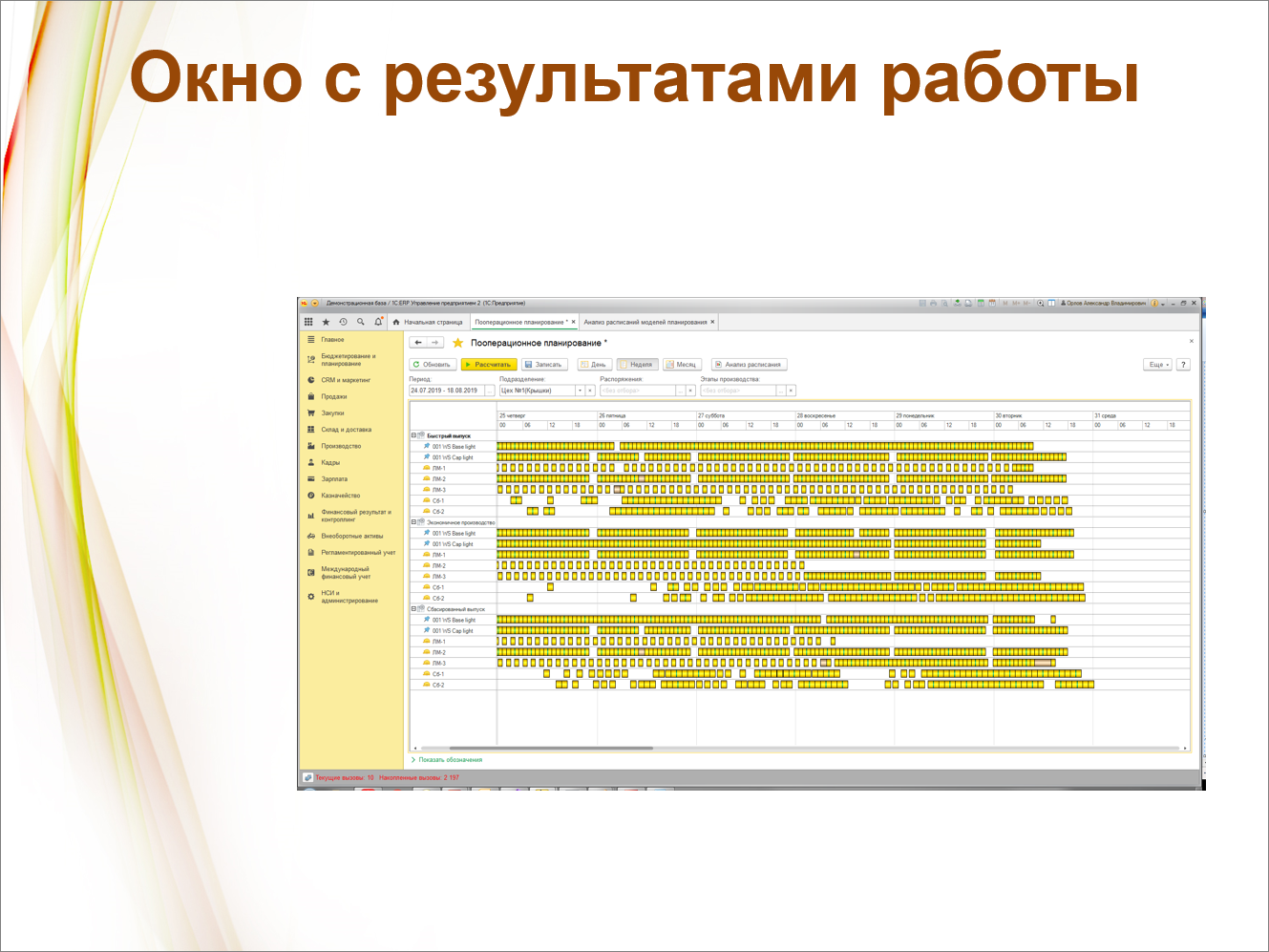
Окно с результатами работы – это то же самое окно.
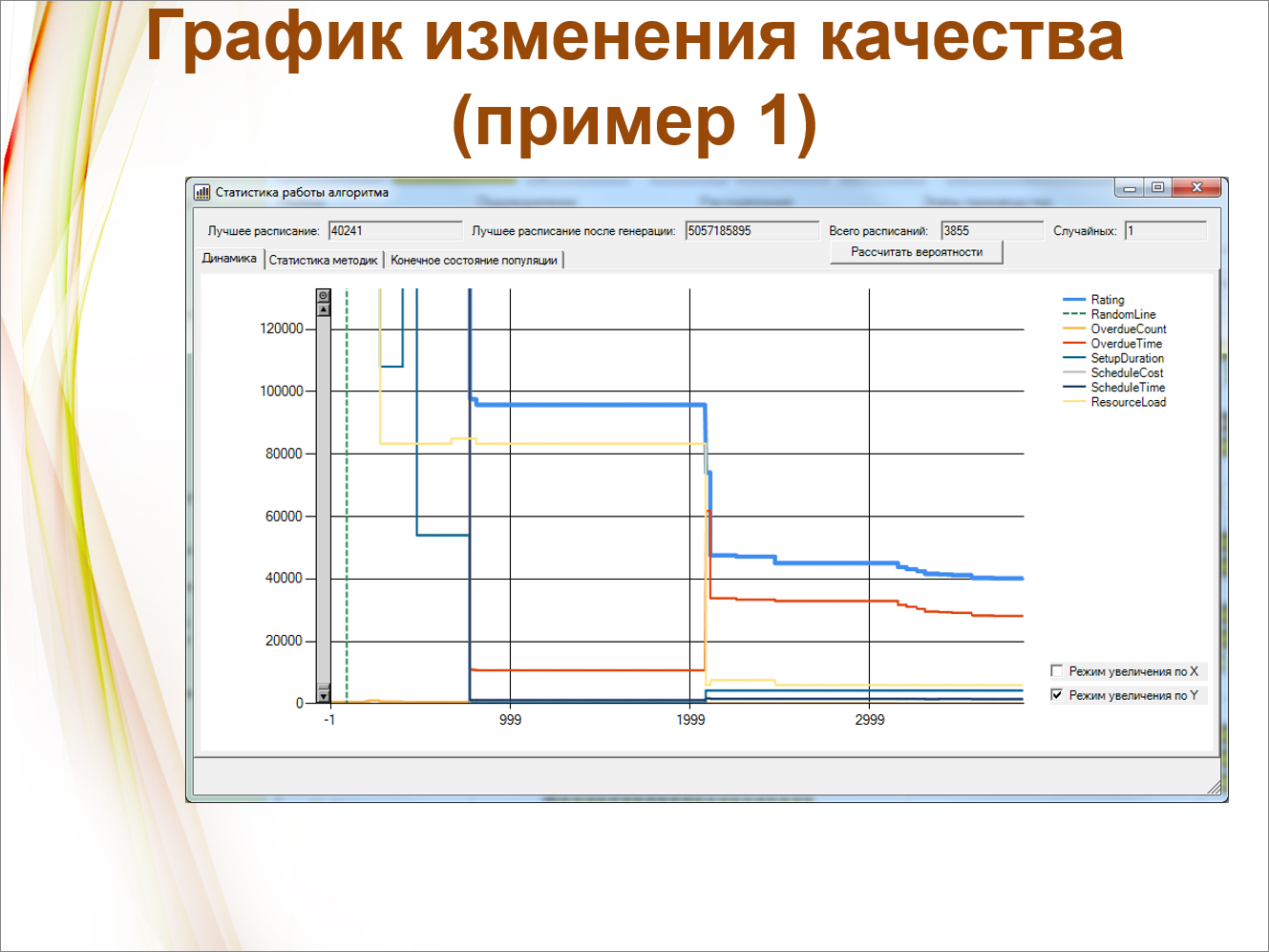
И вот статистика. Здесь можно посмотреть, как все у нас происходит.
Линия рейтинга здесь – это антирейтинг, потому что она показывает, как сокращаются издержки. Этой линией изображен комплексный аддитивный критерий, полученный суммированием с весовыми коэффициентами.
А ниже у нас изображены частные критерии.
Видно, что иногда какие-то из критериев растут навстречу рейтингу. Например, когда стали минимизировать переналадки, критерий OverdueTime, изображенный красной линией, у нас все-таки подрос – мы чуть-чуть пожертвовали просроченностью.
Итого, у нас здесь всего лишь 3000 вариантов, но мы для них, судя по всему, уже вышли на самое оптимальное значение.
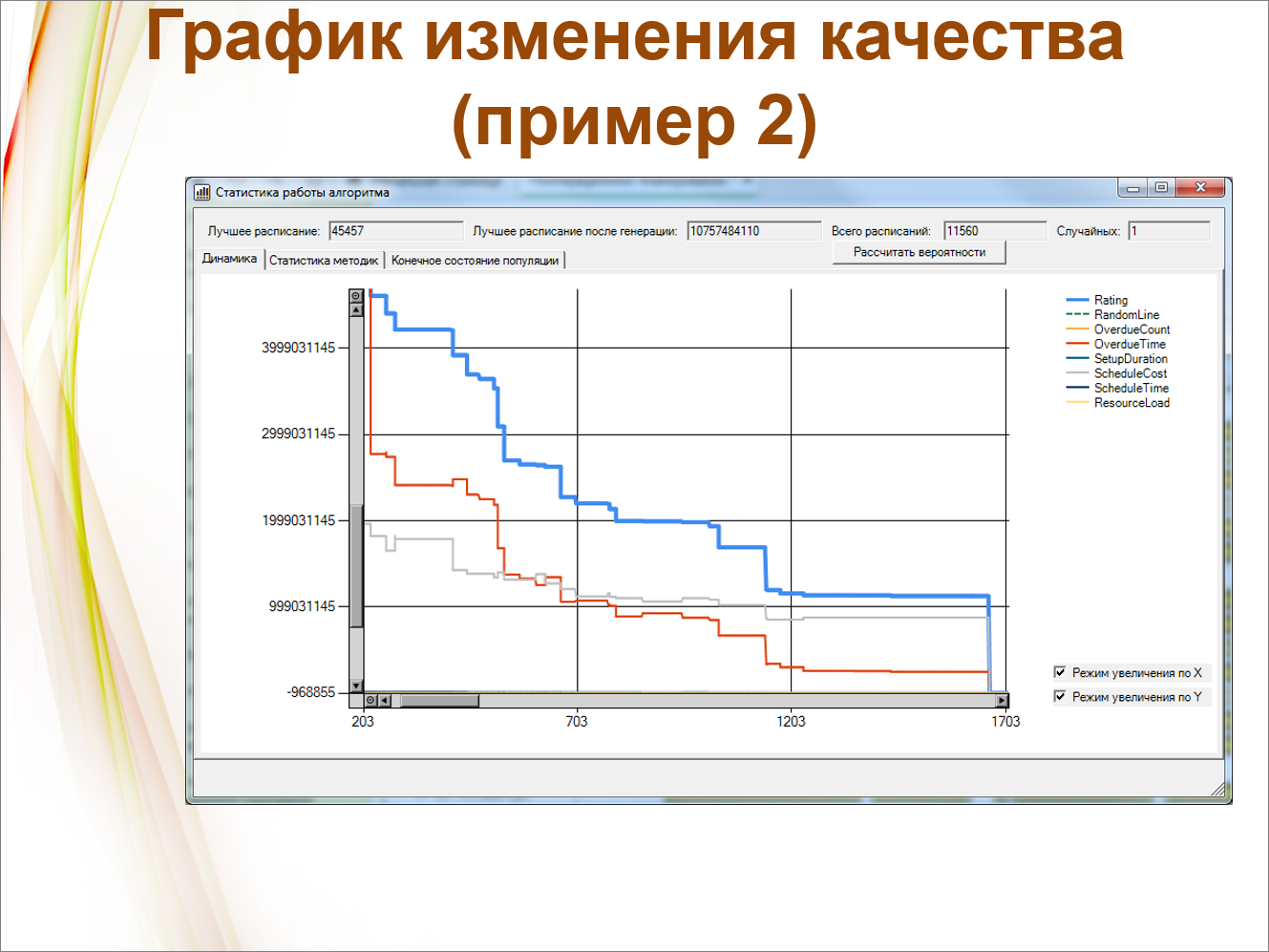
А здесь – другой вариант, когда встречных движений нет, все более-менее гладко.
Общие выводы

-
Я довольно давно занимаюсь 1С и вижу, что, несмотря на надежды сообщества, 1С в области методов оптимизации работать не будет. Это – интересная ниша, пожалуйста, занимайте ее.
-
Выбирая метод решения задачи, связанной с оптимизацией, следует выбирать метод более общий, даже в ущерб каким-то маленьким достижениям. Условия задач меняются гораздо быстрее, чем программируется специализированный метод. Только так мы можем экономить. Это вообще тенденция сегодняшнего дня, что мы экономим свое время, а не компьютерное.
-
Нужно иметь в виду, что есть фундаментальные ограничения при распределении оптимизационных задач между серверами кластера. Десять маленьких силачей не заменят одного большого. Не надейтесь распределить решение. Выбирайте многоядерный сервер.
Если у вас имеются задачи, связанные с оптимизацией, пожалуйста, обращайтесь, привлекайте нас в свои проекты. Используйте математические методы оптимизации. Это интересно, здорово, это – настоящее программирование. Я – большой любитель программирования, оно – мое хобби, вы это видели по моим статьям. Мы вдоволь программировали, используя многие эффективные современные структуры данных. Получили массу удовольствия, немного отдохнули от каждодневной 1С-ной рутины.
Вопросы
-
Preactor в итоге совсем убрали?
-
Да, наша обработка работает без Preactor. Preactor очень многое может, мы можем работать вместе с ним. Но Preactor стоит полтора миллиона, это гораздо больше, чем стоимость ERP. А сейчас мы уже вышли на более широкий рынок – увидели потребность, что классическая ERP-шная обработка пооперационного планирования не работает в реальных применениях, и сделали так, чтобы она могла работать. Мне кажется, что это здорово.
-
А на этом конкретном проекте Preactor был внедрен?
-
Да.
-
Вы сказали, что заказчика не устроила функциональность Preactor. Не скорость, а функциональность.
-
Если говорить про тот конкретный проект, то мы на нем работали в качестве подрядчиков, за спиной исполнителя. Там Preactor выполнял очень много задач. Клиенту Preactor подошел, клиент с ним продолжает работать. Просто в некоторых случаях при некоторых настройках Preactor не минимизировал переналадки так, как хотелось клиенту. Они хотели иметь эту кнопочку, и мы эту кнопочку им сделали.
-
А сколько по времени занимал ваш пересчет?
-
У нас много критериев остановки. В той исходящей задаче у нас было ограничение по времени 10 минут. За эти 10 минут мы отрабатывали 9000 расписаний. Кроме этого, у нас есть критерий остановки, когда график стабилизируется (выходит на «полочку»), расписание уже не меняется. В принципе, обычно мы старались уложиться на том объеме, который нам давали, в десятки минут. Когда мы проводили тестирование – на сложных задачах на большом количестве данных, то запускали расчет на сутки, и решение обычно находилось за 5-6 часов. А вообще критерий остановки в задачах оптимизации – это сложный вопрос.
-
А можно ли для составления расписаний использовать специальные математические пакеты – тот же самый MatLab или Python с библиотеками?
-
Я – большой любитель MatLab, напрограммировался на нем. Многие люди думают, что мы купим известный IBM-овский пакет и решим все задачи. Нет, потому что получается, как дерево – у корня его можно охватить, а у кроны задачи очень быстро расползаются и специальные математические пакеты в области построения расписаний не работают, потому что они работают тогда, когда задача поставлена совершенно конкретно и у нее есть строгие четкие ограничения. Такой узкий класс задач встречается очень редко. Поэтому мы эти специальные пакеты не использовали. Не потому, что мы про них не знаем, а потому, что не нашли такой возможности.
-
Но вы писали практически с нуля, и вам приходилось часть функциональности, которая есть в этих математических пакетах, в том числе ограничения по операциям с плавающей точкой, чтобы не набегала ошибка, делать все в ручном режиме. Потому что идеальный алгоритм (простейшее решение системы матриц 20*20, если его написать «в лоб»), не решится – это ограничение жестких систем.
-
Здесь таких проблем нет. В генетическом алгоритме для построения расписания при ограничении операций ошибки не набегают. Это не расчет себестоимости. Мы сейчас работаем на очень широком поле задач, поэтому я здесь убежден и готов отвечать, что специальные математические пакеты в этой области не работают. Можно привлечь к нашему разговору Евгения Борисовича Фролова – человека, который ведет школу оптимизации расписаний. В этом случае работают только практически ориентированные методы.
-
Два вопроса в сторону конкретики – какая в ваших кейсах была стандартная глубина прогноза этого расписания – насколько вперед они смотрели? И как часто приходилось уже просчитанное, казалось бы, расписание пересчитывать в случае каких-то отклонений по факту от него.
-
На том проекте, с которого все началось – там глубина прогноза расписания была полтора месяца (7 недель). Не знаю, что это за волшебное число, но у меня довольно часто это число выскакивает в практике. Пересчитывать приходится часто, даже очень часто. Недавно мы решали задачу по производственной логистике, где применялись очень похожие методы. Там мы вообще отказались от долговременного прогноза – и просто перешли на часовой интервал пересчета.
-
Вы упомянули, что эвристический метод не дает одинаковый результат два раза. Получается, что вся глубина прогноза может очень сильно измениться?
-
У нас есть операции, которые начаты – они зафиксированы. У нас есть возможность закрепить операции в расписании и их не пересчитывать – это и в ERP есть. Конечно, иногда мы не можем за выделенное время составить оптимальное расписание – тут уже нужно чем-то жертвовать. Но бывают важные заказчики, важные заказы и т.д. Это все учитывается.
-
В вашем итоговом расписании соблюдается ли условие, что на рабочий центр запланировано не больше работы, чем его мощность? Эти алгоритмы учитывают, что мощность рабочих центров ограничена?
-
Да, они учитываются. В нашем сегодняшнем алгоритме это учитывается как ограничение, причем, с резервом доступности – не больше. Оно проигрывается и если сюда не вписывается, то оно переносится и расписание удлиняется или появляются задержки. Иногда бывает (мы с этого начинали) – это можно перенести в разряд критериев – разрешить это, но оценить это каким-то штрафом. Например, если мы это перегрузили, то мы штрафуем это расписание чуть больше. В текущей реализации у нас доступность рабочих центров – это ограничение. Но можно поменять. И я говорил, что это – выбранный нами подход. Он позволяет гибко перестроить условия. Еще я просто не успел сказать, что мы сделали простую обработку для 3D-упаковки, где используется тот же самый алгоритм – просто немного поменяв несколько библиотек. А код в большинстве своем остался тем же самым. Сейчас мы боремся за результаты – и лучшие алгоритмы у нас показывают 80-90% плотности упаковки. К сожалению, пока ближе к 80%.
-
Как себя ведет ваш алгоритм при радикальном увеличении числа операций? Вы сказали, что у вас 13-15 тысяч операций. А если будет 100-500 тысяч операций?
-
У нас 10 тысяч операций – это предел, который не нужно превышать просто исходя из наших жизненных установок. Это общее понимание у всех методологов, кто занимается оптимизацией расписания, что большего количества операций в расписании никому не нужно, иначе оно за счет теории вероятности просто окажется неисполнимым. Поэтому это не нужно. Но наш алгоритм по затратам времени растет линейно, здесь нет квадратичных зависимостей. Получается, если операций у нас в расписании стало 100 тысяч, и мы влезаем в оперативную память, то оно просто будет выполняться в 10 раз дольше. Например, если мы в расписании за 10 минут считаем 10 тысяч операций, то при расчете 100 тысяч операций за 10 минут мы посчитаем только тысячу, соответственно, нужного качества не получим. Обратная линейная зависимость.
-
Все-таки качество итогового получившегося расписания зависит от количества операций?
-
Конечно. Это же поиск – если у нас скорость поиска медленнее, то мы и рыбы поймаем меньше.
-
А как вы оцениваете, на российском рынке, среди российских разработок у вас есть конкуренты в сегменте APS?
-
Мы с ними не сталкивались. Во-первых, у нас это не коробочное решение. Это у нас проекты – с конкретными заказчиками. Это проекты с небольшой стоимостью. Поэтому мне кажется, что мы не должны с ними пересечься. Мы позиционируем свое решение как плагин для ERP. Вы купили ERP, ERP не планирует. Доплатите нам немного, мы вам довнедрим, настроим, оттестируем. Есть фирма ИТРП – они для УПП реализовывали оптимизацию планирования с помощью отдельного сервера. Не знаю, повторили ли они этот опыт для ERP или нет. Во всяком случае, мы сами себе задачу поставили и решили ее. Наверное, я знаю только одну фирму, которая делала такую попытку – именно в этой области. Не в области столкновения с Preactor, где более высокие цены и другой интерфейс, а в области «навесок» к ERP.
-
В принципе, вы не считаете себя конкурентом для Preactor?
-
Нет, конечно.
-
По вашей презентации выходит, что «пришли мы и уделали Siemens».
-
Я извиняюсь, если такое впечатление сформировалось. Тема доклада у меня обозначена скромно. Я хотел бы пояснить, что на том проекте Preactor остался, и работает все вместе. А мы предлагаем другие проекты, где Preactor можно не покупать.
-
Я к чему говорю, у нас же сейчас импортозамещение – вроде хотелось бы импортозаместиться. Если люди привыкли к Preactor, они могут импортозаместиться с вашей помощью?
-
Мы пока себе такой цели не ставим. Если вы купили ERP и хотите использовать MES, приходите к нам, MES у вас заработает. А сделать «отечественный Preactor» мы себе цели не ставим. Мы идем по другому пути.
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.
|
30 мая - 1 июня 2024 года состоится конференция Анализ & Управление в ИТ-проектах, на которой прозвучит 130+ докладов.
Темы конференции:
Конференция для аналитиков и руководителей проектов, а также других специалистов из мира 1С, которые занимаются системным и бизнес-анализом, работают с требованиями, управляют проектами и продуктами!
|





