Оптимизатор запросов. Часть вторая. Оптимизатор. Часть первая
Автор: Искаков Данис. Рецензент: Стрекаловский Иван.
Выражаю особую благодарность Ивану Стрекаловскому за помощь и терпение. Я очень надеюсь, что наше сотрудничество продолжится. Я понимаю, что это отнимает немало времени и нужно не просто читать, а, буквально, перелопачивать материал. И все же, я рад и благодарен вам за вашу поддержку. Эта статья – наш совместный труд.
Конечно, тема оптимизатора – это одновременно и просто, и сложно. Понять его работу, в принципе, не так сложно. Многие это умеют (или думают, что умеют). Но стоит спросить: «А почему выбрана такая стратегия?» - То ответом может стать ступор даже у бывалых зубров. Почему так происходит? - Дело в том, что сам выбор стратегии – это область вероятностного программирования. Ключевое слово – «вероятность». Оптимизатор выбирает ВЕРОЯТНОСТЬ лучшего решения. Представьте, если вас спросят: «Кто выиграет чемпионат мира по футболу?» и дадут информацию о командах. Оптимизатор бы ответил, примерно так: Команда «Торпедо» может победить с ВЕРОЯТНОСТЬЮ, допустим, 70%, Команда «Спартак» - с ВЕРОЯТНОСТЬЮ 20% (ничего не имею против команды Спартак – это просто пример) и т.д. Обратите внимание на то, что ВЕРОЯТНОСТЬ – это не УВЕРЕННОСТЬ, а предположение. А у нашего, горячо любимого, оптимизатора, помимо предположений, есть еще полное незнание структуры базы данных, с которыми он работает. Все данные об используемых данных, оптимизатор получает на входе, а на выходе выдает предполагаемый план запроса. Если бы оптимизатора не было, то это не значит, что мы не могли бы делать выборки. Мы могли бы это делать, только эффективность была бы потеряна. Чтобы лучше понять, давайте представим, что нам нужно хранить и выбирать данные. Для простоты представим, что мы храним таблицы в файлах данных: один файл данных – это одна таблица. Каждая строка файла – это запись таблицы. Теперь, если нам нужно выбрать строку по определенному условию, что мы сделаем? Скорее всего, переберем все строки файла данных в цикле и когда дойдем до нужной строки, прервем цикл. А если условие содержит несколько значений? Тогда сделаем таблицу, куда будем записывать подходящие строки и, пройдя циклом по строкам файла данных, будем отбрасывать неподходящие по условию строки, а подходящие, запишем в нашу таблицу выборки.
Псевдокод 1с:
ТЗвыборки = Новый ТаблицаЗначений;
Выборка = ФайлДанных1.Выбрать();
Пока Выборка.Следующий() Цикл
Если Выборка.Код = ПодходитПодУсловие Тогда
НоваяСтрока = ТЗвыборки.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, Выборка);
КонецЕсли;
КонецЦикла;
Помучившись так несколько раз, мы начнем искать способ улучшить наше приложение. Какие тут есть пути? В СУБД используют файлы индексов. Давайте поступим также. Создаем файл индекса (допустим, по полю «Код»), где у нас записаны упорядоченные значения кодов и номера строк нашего файла данных. Теперь, чтобы найти нужную строку в нашем файле данных с определенным кодом, мы сначала переходим к определенной строке файла индекса. БЕЗ ЦИКЛА! По номеру! А получив строку (в индексном файле), получаем номер строки нашего файла данных. Теперь остается только получить найденную строку в файле данных. Это, конечно, грубый пример, но он позволяет увидеть схему работы.
Псевдокод 1с:
ТЗВыборки = Новый ТаблицаЗначений;
ВыборкаИндекс = ФайлИндекса1.ПолучитьСтроку(НомерКода);
НомерСтрокиФД = ВыборкаИндекс.НомерСтрокиФайлаДанных;
Если НомерСтрокиФД <> Неопределено Тогда
НоваяСтрока = ТЗвыборки.Добавить();
СтрокаФайлаДанных = ФайлДанных1.ПолучитьСтроку(НомерСтрокиФД);
ЗаполнитьЗначенияСвойств(НоваяСтрока, СтрокаФайлаДанных);
КонецЕсли;
По такой же аналогии, мы можем построить и соединения. Допустим, нам надо соединить две таблицы по определенному условию. Выбираем данные из первого файла данных в таблицу выборки номер один, затем из второго в таблицу выборки номер два, после чего запускаем цикл по строкам таблицы номер один, а внутри этого цикла, запускаем еще один цикл по выборке из таблицы номер два. Если данные подходят, то записываем их в таблицу три, если нет, то продолжаем цикл.
Псевдокод 1с:
Тз1 = Новый ТаблицаЗначений;
Тз2 = Новый ТаблицаЗначений;
Тз3 = Новый ТаблицаЗначений;
ВыборкаИзФайлаДанных1 = ФайлДанных1.Выбрать();
Пока ВыборкаИзФайлаДанных1.Следующий() Цикл
ВыборкаИзФайлаДанных2 = ФайлДанных2.Выбрать();
Пока ВыборкаИзФайлаДанных2.Следующий() Цикл
Если ВыборкаИзФайлаДанных1.Код = ВыборкаИзФайлаДанных2.КодПартнера Тогда
НоваяСтрокаТЗ = Тз3.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрокаТЗ, ВыборкаИзфайлаДанных2);
КонецЕсли;
КонецЦикла;
КонецЦикла;
Обратите внимание. Когда мы написали, что выборка начинается с файла данных номер 1, а затем перебор всех записей файла данных 2, мы загнали себя в угол. А что, если я поставлю отбор на выборку из файла данных 2? Не лучше ли будет, сначала выбрать по отбору, а потом запустить цикл сначала из отобранных записей? Какое тут может быть решение? - Можно написать еще несколько выборок, учитывая различные возможности отбора, и потом, исходя из задачи, выбирать нужную. Давайте попробуем. Допустим, что мы написали кучу выборок на все случаи жизни. У нас их получилось, ну пусть, миллион. К нам начали поступать запросы, и мы как давай перебирать весь свой миллион выборок для поиска подходящего. Веселое занятие? «Очень веселое». Повеселившись так определенное время, приходим к выводу: Надо что-то делать. Хорошенько подумав, принимаем решение. Надо написать программу, которая, исходя из входных параметров, будет выбирать НАИБОЛЕЕ подходящую выборку. Что значит - решили автоматизировать поиск выборки. Как это сделать? Самый примитивный путь – это создать соответствия между запросами с параметрами и выборками. То есть, все входящие параметры нам известны изначально. Доложили шефу радостную новость. Шеф от радости уволил половину. Оставшиеся снова задумались. Приходим к мнению: нужно запросы и входящие параметры представить в виде определенных числовых значений. Тоже самое надо сделать с выборкой. И сопоставляя числовые значения параметров и выборок, выбирать самые большие или самые маленькие (а может и средние). Они то, и будут искомые. Вот и появилась первая версия оптимизатора.
Псевдокод 1с:
ВходящиеПараметрыЧисловоеЗначение = ПолучитьЧисловоеЗначение(ВхПарам);
ТЗчислЗначВыборок = Новый ТаблицаЗначений;
Для Каждого ТекущаяВыборка из Выборки Цикл
НоваяСтрока = ТЗчислЗначВыборок.Добавить();
НоваяСтрока.ЧисловоеЗначение = ПолучитьЧисловоеЗначение(ТекушаяВыборка);
НоваяСтрока.Выборка = ТекущаяВыборка;
КонецЦикла;
ИспользуемаяВыборка = НайтиВыборку(ТЗчислЗначВыборок,ВходящиеПараметрыЧисловоеЗначение); //вот здесь происходит вся магия поиска
Как видите, у нас есть функция НайтиВыборку(ТЗгде ищем, ЧтоИщем). Вот она и должна вернуть нужную нам выборку. Дальше можно улучшать работу с числовыми значениями входящих параметров и выборок, и саму функцию улучшать до бесконечности. Это уже детали. Главное, что нужно знать, так это то, что оптимизатор не является частью БД – это общий механизм выборки наилучшего. Его нужно рассматривать как отдельный модуль, внутри СУБД. И что нам нужно, так это правильно давать входящую информацию. Входящая информация – это все, что мы можем. А дальше мы бессильны. В нашем случае, входящая информация – это наши запросы. Сейчас, я хочу заострить ваше внимание на вышесказанном и прошу понять правильно. Если вы написали один запрос, и он работал плохо, а потом внесли изменения и запрос стал лучше выполняться – это улучшение, это прогресс, это очень хорошо, но это не совершенство и может быть очень далеко от идеала. И то, что мы делаем – это улучшение работы запроса. Я понимаю какой поднимется…, назовем бум, в комментах, когда я скажу простую истину – мы никогда не получим наилучший вариант, сколько бы не улучшали. И тот, кто говорит, что, делая вот так и вот так, мы получаем НАИЛУЧШУЮ выборку – тот лукавит. Мы можем получить лучшее из возможных. Давайте по аналогии с нашим примером, сделаем несколько выборок. Представьте, нам нужно выбрать все данные из файла данных номер 1 и упорядочить по полю «Код». Как вы думаете, нужно здесь использовать индекс? Или лучше пройтись полным сканированием файла данных? – С одной стороны, данные в индексном файле упорядочены, с другой стороны, может выборка из одного файла работает быстрее и стоит не использовать индекс.
Псевдокод 1с:
Делать так:
ТзВыборки = Новый ТаблицаЗначений;
ВыборкаФайлДанных1 = ФайлДанных1.Выбрать();
Пока ВыборкаФайлДанных1.Следующий() Цикл
НоваяСтрока = ТзВыборки.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока,ВыборкаФайлДанных1);
КонецЦикла;
ТзВыборки.Сортировать(«Код»);
Или так:
ТзВыборки = Новый ТаблицаЗначений;
ВыборкаИндекса = ФайлИндекса1.Выбрать();
Пока ВыборкаИндекса.Следующий() Цикл
НоваяСтрока = ТзВыборки.Добавить();
СтрокаФайлаДанных = ФайлДанных1.ПолучитьСтроку(ВыборкаИндекса.Код);
ЗаполнитьЗначенияСвойств(НоваяСтрока, СтрокаФайлаДанных);
КонецЦикла;
Как видите, в первом случае используется сортировка полученной таблицы, а во втором случае – ее нет. Но зато во второй выборке есть постоянные переходы к файлу данных. Какой из этих вариантов лучше? А может есть еще третий вариант, который будет лучше предыдущих? Самое интересное, что мы не можем ОДНОЗНАЧНО ответить на эти вопросы. Нам нужно учитывать сколько записей в файле, вместиться ли вся наша выборка в оперативную память, как работает функция сортировки и много-много еще разных условий. Поэтому для нас важно выбрать НАИБОЛЕЕ подходящую процедуру и использовать ее. Вот еще пример: Допустим, в нашем файле данных номер 1 есть поле с типом «Булево». И мы решили создать индекс по этому полю. Какие тут могут быть варианты? – Ну, я предлагаю сделать два файла индексов, в один из которых мы будем писать номера строк файла данных, соответствующих значению «Истина», а в другой файл индекса - со значением «Ложь». (Помните, это просто пример. Поэтому можем позволить себе все.) Теперь, когда мы будем выбирать данные с отбором по этому полю, мы можем использовать определенный файл индекса. Как вы думаете, это улучшит выборку? Давайте, для начала, взглянем на псевдокод:
Выборка по индексу:
ТзВыборки = Новый ТаблицаЗначений;
ВыборкаИндекса = ФайлИндексаБулевоИстина.Выбрать();
Пока ВыборкаИндекса.Следующий() Цикл
СтрокаФайлаДанных= ФайлДанных1.ПолучитьСтроку(ВыборкаИндекса.НомерСтроки);
НоваяСтрока = ТзВыборки.Добавить();
ЗаполнитьЗначенияСвойств(НоваяСтрока, СтрокаФайлаДанных);
КонецЦикла;
Выборка без индекса:
ТзВыборки = Новый ТаблицаЗначений;
ВыборкаДанных = ФайлДанных1.Выбрать();
Пока ВыборкаДанных.Следующий() Цикл
Если ВыборкаДанных.<ПолеБулево> = Ложь Тогда
Продолжить;
КонецЕсли;
НоваяСтрока = ТзВыборки.Добавить();
ЗаполнитьЗначенияСвойств(новаяСтрока, ВыборкаДанных);
КонецЦикла;
В первом случае, мы постоянно обращаемся к файлу данных, но зато проходим не весь файл, а только нужные записи. Во втором случае, выборка идет из одного файла, но зато перебираются все записи. А что, если у нас записей с признаком «Истина» много (допустим, сто тысяч), а записей с признаком «Ложь» всего несколько штук (к примеру, три)? Еще вопрос: А стоит ли сохранять выбранную стратегию для дальнейшего использования? А что, если данные обновились? Подойдет ли сохраненная стратегия? Попробуйте ответить. Конечно, есть общие правила и рекомендации. И к ним стоить прислушаться. Но принимать все на веру не стоит. Лучше попробовать все самим. Представьте, как бы вы сделали выборку с условием равенства/неравенства, как бы соединяли таблицы и т.д.
Ну, как говорил Ги де Мопассан: «ближе к телу». В прошлой статье за бортом остались некоторые вопросы. Я сейчас постараюсь исправить положение. Быстренько пробежимся по некоторым пунктам, чтобы восполнить пробел. Я не буду слишком углубляться. Информации будет ровно столько, сколько нужно для понимания материала. Ну, а мы переходим к…
I. Хранение информации на диске.
- Страницы. Строение страниц. Информация на диске хранится в виде страниц. Лучше, конечно, представить хранение, как набор связанных файлов, где каждый файл – это и есть страница. Страница состоит из заголовка, данных и таблицы смещений. В заголовке содержится системная информация – идентификатор базы данных, идентификатор таблицы (объекта), указатели на предыдущую и следующую страницу, размерность, права и т.д. Сразу за заголовком идут данные (представьте их в виде строк). Ну и в конце, находится таблица смещений, где каждая строка таблицы, занимает два байта и содержит указатель на строку данных. Таблица смещений начинается с конца, то есть, первая запись указывает на последнюю строку. Выглядит это так:
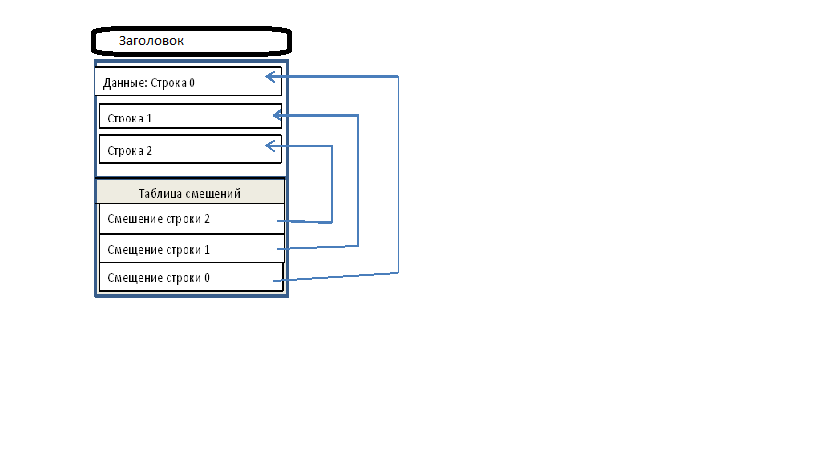
Каждая строка состоит из полей (типа колонок таблицы), и каждое поле должно иметь свой фиксированный размер – поэтому, когда мы создаем поля, то указываем его тип, ведь по нему движок СУБД определяет количество выделяемой памяти для поля. Если данные поля слишком большие и превышают размер страниц, то в область данных записывается информация о странице, где хранится информация. Каждая страница принадлежит одной таблице в БД. И, соответственно, одна таблица может содержать много страниц. Помимо самих страниц данных есть еще и индексные файлы. Когда мы создаем индекс, то создаются индексные файлы. По структуре (по крайней мере, той, которая нас интересует) они похожи на страницы, где хранятся данные таблиц, только вместо данных таблиц там находятся данные индексов. Индексные файлы связаны с информацией в наших страницах данных. Соответственно, если мы обновляем данные в таблице, то движок СУБД должен обновить и индексные файлы. Когда происходит захват данных в таблицах, мы должны понимать, что на самом деле, произошел захват страниц. И еще нам нужно понять: что все проходы по БД (выборка, обновление, запись и т.д.) – это постоянное перемещение страниц из оперативной памяти на диск и обратно. В рамках оптимизатора – это значит, что процесс оптимизации начинается с проектирования БД. Я понимаю, что работы от проекта ведут не все, чаще всего вам приходится работать с уже готовыми базами. Поэтому мы здесь больше внимания уделим именно этому и следующим важным пунктом для рассмотрения являются индексы.
- Индексы. Индексы служат для более удобного доступа к данным. Наиболее удачный пример – это оглавление книги. В книгах есть раздел «Оглавление», где содержится список разделов или глав, с указанием номера страницы, перейдя на которую, мы можем начать читать указанную в «Оглавлении» главу. Другой пример - это закладки, которые можно распределить по книге для быстрого поиска. Индексы в БД представляются в виде дерева. Ветки дерева – это диапазоны значений полей. Проход по веткам дерева с выходом на конкретную/ые страницу может быть быстрее, чем переход от страницы к странице, хотя это не всегда справедливо (я имею ввиду маленькие таблицы, которые проще сканировать последовательно).
В БД индексы бывают двух типов: кластерные и некластерные.
- Кластерный индекс создается по полю таблицы с уникальными значениями и в листьях своего дерева содержит непосредственно записи таблиц. Если сравнить с оглавлением, то строчка оглавления – это запись индекса, а когда мы переходим к нужной странице, то получаем данные, которые необходимо прочитать (запись таблицы). Такой индекс является физически упорядоченным. На каждую таблицу можно создать один кластерный индекс, так как упорядочить одновременно по нескольким полям невозможно.
- Некластерный индекс. В отличии от кластерного индекса, некластерный содержит в своих листьях ссылки на записи таблиц. Опять же, если сравнить с книгой, то в книгах, помимо оглавления, бывает еще и алфавитный указатель, содержащий ссылку на главу. Поэтому, чтобы найти эту главу, нам нужно обратиться к оглавлению, а из него к непосредственной странице с данными. Если оглавления нет, то придется просматривать страницу за страницей, в поисках нужной главы. (По крайней мере, так работает движок СУБД)
Вот здесь первое замечание: - При сильном частом обновлении таблицы с кластерным индексом, будет происходить снижение производительности из-за переупорядочивания данных. А при частом удалении таблица будет фрагментирована (содержать пустые строки). Попробуйте сами создать таблицу без индекса и добавьте/удалите несколько тысяч строк и сделайте тоже с кластерным/некластерным индексом. И чем больше раз вы проделаете операции, тем нагляднее будет пример. Особенно обратите внимание на разницу между кластерным и некластерным индексом. И тоже самое, проделайте с выборкой. С выборкой играть еще интересней. Можно сначала сделать простую выборку, потом выборку с оператором DISTINCT (РАЗЛИЧНЫЕ), с оператором TOP, потом с условием по полю с кластерным индексом, потом с некластерным. Получить их планы запроса и сравнить. Для тех, кто не знает, как получить план запроса, в конце статьи будет описание команд СКЛ в среде Management Studio.
- Кеширование индексов. В SQL Server есть область памяти, предназначенная для хранения планов выполнения запросов. Если к серверу выполняется несколько однотипных запросов, то сервер строит план только для первого запроса и сохраняет его в кэш, а остальные выполняет по уже созданному плану. Это касается параметризированных запросов. Например:
Есть два запроса: SELECT * FROM Zakaz WHERE date_zakaz > ‘01/02/2010’
И второй запрос: SELECT * FROM Zakaz WHERE date_zakaz > ‘01/02/2012’
Обратите внимание на условие. Здесь используются разные даты в виде констант. Для этих запросов оптимизатор будет строить разные планы, так как ему надо оценить каждую выборку.
Теперь давайте переделаем на параметризированный запрос:
DECLARE @date_parametr = ‘02/02/2010’
SELECT * FROM Zakaz WHERE date_zakaz > @date_parametr ,
затем запустим еще один похожий запрос
DECLARE @date_parametr = ‘01/02/2000’
SELECT * FROM Zakaz WHERE date_zakaz > @date_parametr .
В этом случае, план первого запроса уйдет в кэш и второй запрос будет выполнен по этому плану. А это не всегда гарантирует оптимальность выполнения запроса. И еще одно, очень трудно понять, что запрос будет неэффективно выполняться, если смотреть только на код запроса, то есть при разных параметрах – будут разные результаты.
- Фильтруемый индекс. Если вам часто приходится обращаться к определенному диапазону значений в таблице, то можно создать фильтруемый индекс (всегда некластерный). Он отличается от обыкновенного тем, что содержит только попадающие под условия, данные. Например, нам нужно получать заказы только за этот год, а то, что было раньше нас не интересует. В этом случае создание фильтруемого индекса поможет ускорить выборку данных. Создать его можно такой командой
CREATE NONCLUSTERED INDEX i_zakaz
- ON zakaz (date_zakaz)
- WHERE date_zakaz > ‘01/01/2018’
GO
Теперь, когда мы будем обращаться к полю date_zakaz данной таблицы, то оптимизатор может использовать наш фильтруемый индекс. Конечно, надо помнить о том, что индекс тоже требует обслуживания. Другими словами, на каждый индекс тратятся ресурсы.
- Индекс, с включенными полями. Еще одним видом индексов является индекс с включенными полями. Часто бывает такая ситуация – надо выбрать определенные столбцы, при этом отбор использует некое третье поле. Примером может служить выборка Склада и Номенклатуры, а в качестве отбора используем поле Организация. Даже если Организация имеет индекс, план запроса вряд ли будет его использовать. Хотя если сделать индекс по полям Склад и Номенклатура, то тут наш индекс попадает в план запроса. При создании таких композитных индексов следует учесть, что порядок указания столбцов играет роль на использование индекса оптимизатором. Если в нашем примере поменять местами поля Номенклатура и Склад, то при выборке такой индекс не будет учитываться. Вообще, роль играет только первое поле. Допустим, мы указали такой порядок: Склад, затем Номенклатура – теперь если выбирать поле Склад или Склад и Номенклатура, то индекс сработает, а вот если выбрать поле Номенклатура или Номенклатура и Склад – индекс не сработает. Можно, конечно, добавить еще один индекс по полям Номенклатура, затем Склад. В этом случае, оптимизатор будет сравнивать, какой индекс более селективный и использовать его. Только такие вещи лучше делать с осторожностью – индексы надо обслуживать.
- Упорядочивание индексов. При создании индексов вы можете использовать команды упорядочивания по возрастанию/убыванию (ASC/DESC). Такое упорядочивание влияет на группировку и сортировку данных при выполнении запросов. На выборку, правда, это не влияет.
- Статистика индексов. Как говорилось в прошлой статье, на использование индексов влияет селективность. Если более подробно, то для каждого индекса есть понятие плотность распределения. Это когда определяется как распределены данные таблицы и вычисляется путем 1 / Число уникальных записей. Здесь большое значение имеет ЧИСЛО УНИКАЛЬНЫХ ЗАПИСЕЙ. Так, к примеру, если в нашей таблице все записи уникальны, то мы получим плотность = 1/число записей. А если в нашей таблице пять уникальных записей? То здесь будет плотность = 1 / 5 или 20%. При создании индексов рекомендуется обращать внимание на плотность распределения и если она выше 10% (для некластерного индекса), то создание индекса вызывает большое сомнение. Тут действует правило: чем больше плотность распределения (больше уникальных записей), тем лучше для индекса. Поэтому создание индекса для таблицы из пяти записей - бесполезно. Еще пример: - Пусть, в таблице 500 строк и всего пять уникальных значений (сто записей – одно значение), то плотность = 1/5 или 20%. Или поле таблицы может содержать миллион строк, но всего два значения. Это, например, может быть, когда наше поле имеет значение типа бит и значения типа: (1 или 0 и т.д.). Селективность у этого поля низкая и поэтому здесь будет сканирование таблицы даже при наличии индекса. Есть некоторые специфические виды индексов – это индексы множеств или кластеров. Например, поле содержит географические данные, и мы решили разбить их по регионам. Одно множество может показывать один регион, другое множество следующий регион и т.д. (ну или кластеры: хорошие покупатели, плохие покупатели; добросовестные кредиторы и недобросовестные; ваши примеры). Эти индексы тоже срабатывают при хорошей селективности.
Вообще, когда нужно представить работу индексов и статистику, то можете использовать следующий подход: вы берете книгу, где вам надо прочитать две главы. Как думаете, использовать оглавление в этом случае? Не спешите отвечать. На самом деле вопрос с подвохом. Если в книге две или три главы, то можно и целиком прочитать. Ведь так? А если там целая куча глав, то тогда выгодней использовать оглавление. Также и работа с некластерными индексами – только здесь, вместо оглавления, алфавитный указатель.
Как можно посмотреть статистику по индексу? - Для просмотра статистики можете воспользоваться командой:
DBCC SHOW_STATISTICS (<your_table>, <your_index_name>), где <your_table> - имя таблицы <your_index_name> - имя индекса
Вручную обновить Статистику поля индекса можно командой
UPDATE STATISTIC [your_table] [your_index_name]
Вместо рекомендаций. При использовании индексов обратите внимание на то, по каким полям данные выбираются чаще всего. Если вы используете выборку по Складу и Номенклатуре, то индексы по этим полям могут ускорить выполнение запроса. Обратите внимание на плотность. Если плотность данных мала, то индекс будет, скорее, вредить, чем помогать. Обновление статистики играет немаловажную роль. А вот делать это вручную или средствами СУБД – это уже решать вам. В некоторых случаях, полезно чтобы СУБД само заботилось об обновлении, но иногда вам может понадобится и вручную обновить статистические данные. Допустим, что в таблице, хранящей миллион строк, изменилось сто записей. Стоит ли обновлять статистику? – Думаю, нет, если плотность данных высокая и думаю, да, если плотность данных настолько низка, что измененные записи влияют на количество уникальных записей. Однозначного ответа нет. Понимаю, что многим хотелось бы готовых рецептов, но, к сожалению, их не существует. И об этом далее…
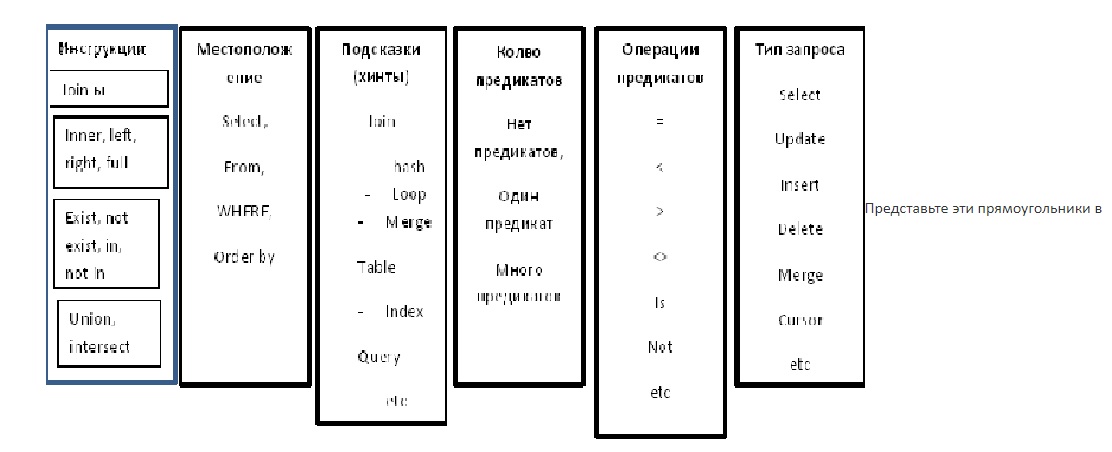
Что влияет на решения оптимизатора. Давайте рассмотрим, что влияет на решения, принимаемые оптимизатором.
Инструкции языка - [inner join, cross join, left/right outer join, full outer join, [not]exist, [not]in, union, intersect];
Местоположение в запросе -[select, from, where, order by];
Хинты (если есть поддержка подсказок для запроса) - [join (loop, hash, merge), table (index), query (force order, loop join, merge join, hash join)];
Количество предикатов -[нет предикатов, один, несколько];
Операции в предикатах - [=, >, <, >=, <=, <>, is, is not, not];
Тип запроса- [select, insert, update, delete, merge, if, cursor];
Как видите, таких множеств много, а комбинаций этих множеств еще больше. Не помню, где, я видел такую картинку. Мне кажется, она в лучшей мере отображает ситуацию
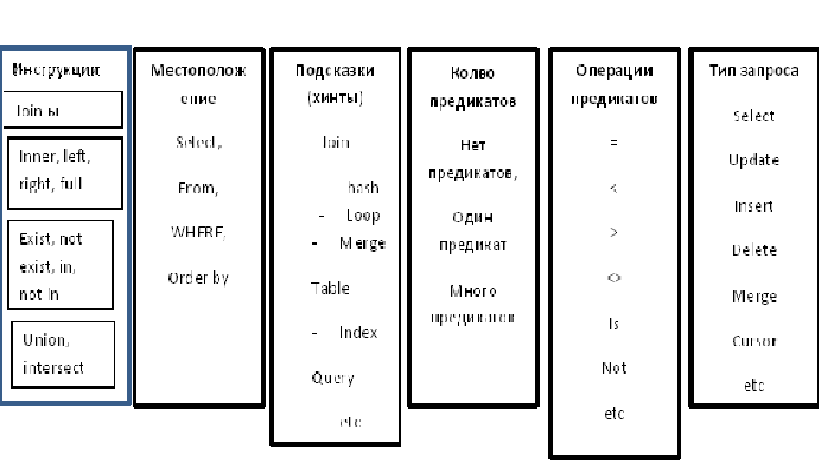 Представьте эти прямоугольники в виде неких валов. Допустим, мы видим только верхнюю строку. Вращая эти валы, мы получаем различные комбинации этой строки. И на основе этой комбинации, строим наилучшую стратегию. Причем, мы можем получать не одно, а несколько строк. Крутанули вал – зафиксировали строку, затем опять – крутим вал и так далее. Результат может быть очень огромным. И как будет действовать оптимизатор не всегда очевидно. Ведь мы можем делать выборку, вложенную в другую выборку, затем повторять эту выборку или соединять по разным условиям. Иногда оптимизатору выгодно сразу что-то рассчитать, иногда лучше выбирать последовательно. И насчет рассчитанных значений. Давайте рассмотрим еще такое понятие, как предикаты и скаляры. Это рассчитанное выражение встречается в плане запроса как Compute Scalar.
Представьте эти прямоугольники в виде неких валов. Допустим, мы видим только верхнюю строку. Вращая эти валы, мы получаем различные комбинации этой строки. И на основе этой комбинации, строим наилучшую стратегию. Причем, мы можем получать не одно, а несколько строк. Крутанули вал – зафиксировали строку, затем опять – крутим вал и так далее. Результат может быть очень огромным. И как будет действовать оптимизатор не всегда очевидно. Ведь мы можем делать выборку, вложенную в другую выборку, затем повторять эту выборку или соединять по разным условиям. Иногда оптимизатору выгодно сразу что-то рассчитать, иногда лучше выбирать последовательно. И насчет рассчитанных значений. Давайте рассмотрим еще такое понятие, как предикаты и скаляры. Это рассчитанное выражение встречается в плане запроса как Compute Scalar.
Предикаты - выражение, результатом которого является значение булевого типа или неопределенно (множество Операции предикатов). Выражение может состоять из одной или двух частей. Например: НЕ <Проверяемое> (проверяется одна часть) или <Первое> = <Второе> (состоит из двух частей: справа и слева). Еще одно определение, которое нам понадобится – это скаляры. Скаляры – это константы, переменные или арифметические выражения. Они могут стоять в любой части предиката. Скалярные выражения вычисляются, а их значения подставляются в то место запроса, где они объявлены (в плане запроса Compute Scalar).
Вот мы и пробежались по основам. Теперь, я думаю, вы и сами сможете в случае необходимости углубиться в материал. Ну, а мы рассмотрим вызов оптимизатора.
Оптимизатор. Для того, чтобы посмотреть план запроса в среде Management Studio наберите
SET SHOWPLAN_ALL ON; --включаем показ плана запроса
GO – запуск изменений
--В этом месте располагаем свой запрос
SELECT <your_fields> FROM <your_table>
--закончили запрос
GO -- запуск запроса
SET SHOWPLAN_ALL OFF; --отключаем показ плана запроса (ОБЯЗАТЕЛЬНО)
GO – запуск изменений
Вместо SHOWPLAN_ALL можно использовать SHOWPLAN_TEXT (правда, вид у него не очень) или SHOWPLAN_XML (а у этого классный вид). Или можно набрать текст запроса и выбрать в меню «Запрос», кнопку «Показать предполагаемый план запроса».
В прошлой статье рассказывалось о соединениях (NESTED LOOP, MERGE JOIN, HASH JOIN). Здесь же посмотрим на такие вещи index scan, index seek, table scan.
Index scan – сканирование по индексу. Выбираем записи, используя индекс.
Index seek – позиционирование внутри выборки по индексу. Сразу переходит к нужной записи. Если по аналогии с книгой, то сразу находит нужную страницу и ставит указатель на нужную строку.
Table scan – сканирование таблицы. Проход по всем страницам последовательно. Так мы читаем книгу. Нас не интересует оглавление, мы читаем от начала до конца.
Когда вы будете получать план запроса, обратите внимание, что выполняется он справа налево. В плане запроса, помимо информации о выбираемых таблицах и методах, еще есть информация о стоимости каждого действия. Чем выше стоимость, тем больше затрат на данное действие. Для эксперимента, вам понадобится не так уж много. Можете создать базу из трех-пяти таблиц. Сделать наполнение. Мы, в свое время, делали так. Из программы выгружали в файл CSV данные, которые загружали потом в тестовую базу. И начинали эксперименты: создашь индекс – посмотришь выборку, удалишь индекс – опять выборка. Сами выборки делали тоже с усложнением. Сначала просто выборку, потом с операторами TOP, DISTINCT, потом условия (разные: на равенство, неравенство, вхождения в диапазон и т.д.), потом соединения с другой таблицей и тоже с разными условиями. И, сравнивая планы запросов и результаты выборки, учились. Если честно, то это заняло не так много времени, как думали изначально.
Теперь немного слов о 1С. К сожалению, управление индексами в рамках 1С, как бы сказать тактичней, сильно упрощено. Настолько сильно, что из конфигуратора, вы можете только указать, что индексировать, но не как это делать. В принципе, можно в самом скуле выставить нужные индексы на базу 1с, но я вам это не рекомендую. Я не уверен, к каким последствиям это может привести. На что я хочу обратить внимание, так это «Внешние источники». Тут есть возможность и рыбку съесть, сорри, свою базу в скуле сделать и с нужными индексами и прочим. И потом обращаться к ним из 1с.
За сим позвольте откланяться. Если есть вопросы, пишите в комментарии.