Цель этой статьи - показать, что оптимизация запросов "по учебнику" не всегда работает, и иногда приходится использовать подходы, которые идут вразрез всем правилам, описанным на курсах и в книгах для 1С:Экспертов по технологическим вопросам.
Более 2-х лет я занимаюсь вопросами повышения производительности 1С за счет оптимизации программного кода. Одна из частых задач (особенно при борьбе с ожиданиями на блокировках) - это повышение режима совместимости конфигурации 1С.
Описание проблемы
Один из клиентов обратился к нам для перевода конфигурации из режима совместимости с 8.1 в режим "без совместимости" (версия платформы 8.2.19.102).
Код конфигурации был адаптирован под 8.2, режим совместимости благополучно изменен.
Примечание: версия СУБД в процессе повышения режима совместимости не изменялась.
НО, после повышения режима совместимости пользователи начали жаловаться на медленный поиск номенклатуры в рабочем месте менеджера.
Поиск выполнялся следующим образом: пользователь в специальном окне вводил строку поиска и нажимал Enter. На 8.1 поиск выполнялся около 5 секунд. При переходе на 8.2 стал выполняться 20 секунд (в 4 раза дольше). Нужно было ускорить поиск хотя бы до старых значений в 5 секунд.
Анализ и решение
При поиске номенклатуры выполнялся вот такой запрос:

С помощью SQL Server Profiler были получены тексты запросов и планы выполнения для платформы 8.1 и для платформы 8.2.
Текст запроса в терминах SQL (платформа 8.1):

План запроса (платформа 8.1):

Таким образом, при выполнении запроса на 8.1 происходил полный скан таблицы справочника. Любой человек, который когда-нибудь занимался оптимизацией запросов скажет вам - "скан - это плохо", и будет прав. Но дальше увидим, что на самом деле это не всегда так :)
Текст запроса в терминах SQL (платформа 8.2):

План запроса (платформа 8.2):
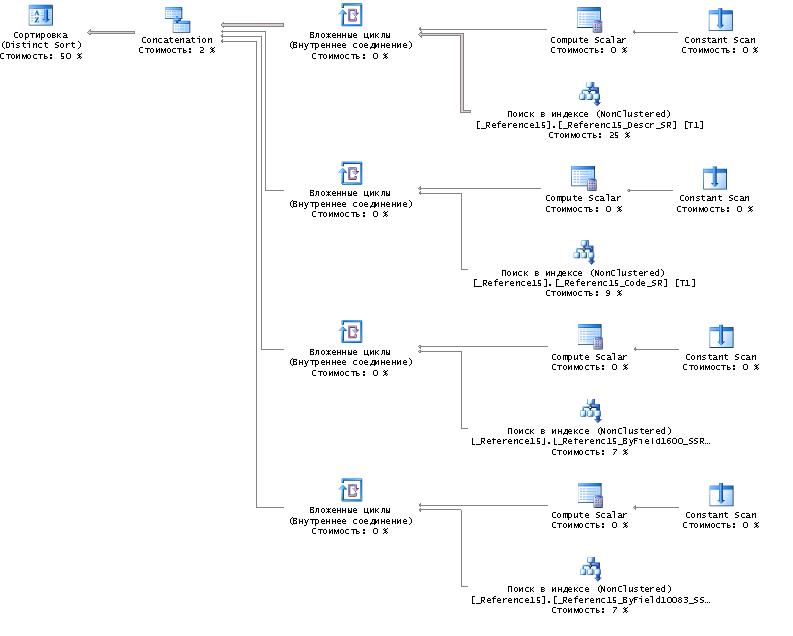
Несмотря на то, что сканов в этом плане запроса не было, запрос выполнялся в 4 раза дольше (20 сек.), чем этот же самый запрос на платформе 8.1 (5 сек.).
Любые попытки оптимизации этого запроса по стандартным методикам не привели к нужному результату - он продолжал стабильно выполняться в 3-4 раза дольше, чем до повышения режима совместимости.
Тогда было принято решение намеренно "ухудшить" запрос, чтобы повлиять на выбор плана запроса оптимизатором СУБД, и получить скан таблицы справочника (как было в 8.1).
Для этого в текст запроса были добавлены выражения над полями условий, запрос стал выглядеть так:

План запроса стал следующим:
То есть, мы получили такой же план запроса, который был при режиме совместимости с 8.1 - полный скан таблицы справочника.
При этом запрос ускорился в 4 раза: с 20 сек. до 5 сек.
Таким образом, конкретно в этом случае, скан таблицы оказался быстрее поиска по индексу.
В этой статье постарался показать, что оптимизация "по учебнику", работает не всегда.
Если вам понравилась статья, поставьте "+" :)