Почему оптимизатор выбрал такой план?
Здравствуйте, коллеги.
Голову себе сломал, почему оптимизатор выбрал в качестве соединения Nested Loops в запросе
Т.е. получается, что регистр сам на себя соединяется. Размер регистра 2010000 строк.
Регистр состоит из измерений: Число1; Число2; Число3.
Измерение Число3 индексировано.
В индексе поля расположены: Число3; Число1; Число2.
Графический план в картинке.
Голову себе сломал, почему оптимизатор выбрал в качестве соединения Nested Loops в запросе
ВЫБРАТЬ ПЕРВЫЕ 5
РС_Тест2.Число1,
РС_Тест21.Число1 КАК Число11
ИЗ
РегистрСведений.РС_Тест2 КАК РС_Тест21
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.РС_Тест2 КАК РС_Тест2
ПО РС_Тест21.Число3 = РС_Тест2.Число3
И РС_Тест21.Число2 = РС_Тест2.Число1
Т.е. получается, что регистр сам на себя соединяется. Размер регистра 2010000 строк.
Регистр состоит из измерений: Число1; Число2; Число3.
Измерение Число3 индексировано.
В индексе поля расположены: Число3; Число1; Число2.
Текстовый план |
|---|
| Rows Executes StmtText StmtId NodeId Parent PhysicalOp LogicalOp Argument DefinedValues EstimateRows EstimateIO EstimateCPU AvgRowSize TotalSubtreeCost OutputList Warnings Type Parallel EstimateExecutions
---- -------- -------- ------ ------ ------ ---------- --------- -------- ------------- ------------ ---------- ----------- ---------- ---------------- ---------- -------- ---- -------- ------------------ 5 1 Top(TOP EXPRESSION:((5))) 0 0 Top Top TOP EXPRESSION:((5)) 5 0 5E-007 25 0,0230134 [T1].[_Fld756], [T2].[_Fld756] PLAN_ROW 0 1 5 1 |--Nested Loops(Inner Join, OUTER REFERENCES:([T1].[_Fld757], [T1].[_Fld758], [Expr1002]) WITH UNORDERED PREFETCH) 0 1 0 Nested Loops Inner Join OUTER REFERENCES:([T1].[_Fld757], [T1].[_Fld758], [Expr1002]) WITH UNORDERED PREFETCH 5 0 8,40205 25 0,0230129 [T1].[_Fld756], [T2].[_Fld756] PLAN_ROW 0 1 1972380 1 |--Index Scan(OBJECT:([CourseExpert].[dbo].[_InfoRg755].[_InfoRg755_ByDims764_NNN] AS [T1])) 0 3 1 Index Scan Index Scan OBJECT:([CourseExpert].[dbo].[_InfoRg755].[_InfoRg755_ByDims764_NNN] AS [T1]) [T1].[_Fld756], [T1].[_Fld757], [T1].[_Fld758] 4,99985 6,08016 2,21116 34 0,00329959 [T1].[_Fld756], [T1].[_Fld757], [T1].[_Fld758] PLAN_ROW 0 1 5 1972380 |--Index Seek(OBJECT:([CourseExpert].[dbo].[_InfoRg755].[_InfoRg755_ByDims764_NNN] AS [T2]), SEEK:([T2].[_Fld758]=[CourseExpert].[dbo].[_InfoRg755].[_Fld758] as [T1].[_Fld758] AND [T2].[_Fld756]=[CourseExpert].[dbo].[_InfoRg755].[_Fld757] as [T1].[_Fld757]) ORDERED FORWARD) 0 4 1 Index Seek Index Seek OBJECT:([CourseExpert].[dbo].[_InfoRg755].[_InfoRg755_ByDims764_NNN] AS [T2]), SEEK:([T2].[_Fld758]=[CourseExpert].[dbo].[_InfoRg755].[_Fld758] as [T1].[_Fld758] AND [T2].[_Fld756]=[CourseExpert].[dbo].[_InfoRg755].[_Fld757] as [T1].[_Fld757]) ORDERED FORWARD [T2].[_Fld756] 1,00003 0,003125 0,0001581 16 0,0196924 [T2].[_Fld756] PLAN_ROW 0 5,99985 |
Графический план в картинке.
Прикрепленные файлы:

По теме из базы знаний
- SQL: Добиваемся выполнения параллельного плана запроса
- Зачем запросу план и кто его выполняет?
- Почему вообще работает мой запрос? или Ещё раз о планах запросов
- Оптимизатор запросов. Вторая часть
- Смотрим запросы 1С через Microsoft SQL Profiler по следам ошибок разработчиков, приводящих к проблемам производительности
Ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
(1)Не моё:
"
Nested loop - (сильно грубое описание) Пробегаем по таблице 1 и для каждой строки из нее смотрим какие строки из таблицы 2 ей подходят.
Обычно очень быстро дает первые строки результата (если конечно таблица 2 не гигантская, а единственная строка из первой таблицы, которая попадет в результат - последняя). Еще алгоритм, практически не требует дополнительной памяти для промежуточной работы и индекс во второй таблице может сильно помочь.
Hash join - Поскольку сравнивать каждую строку с каждой очень долго придумали шаманские танцы. Придумываем некую очень быстро вычислимую функцию от сравниваемых полей возвращающую результат от 1 до N. Просматриваем все строки таблицы 1 и раскладываем их в N корзин. Просматриваем таблицу 2 и для каждой строки проверяем только строки из подходящей корзины.
Достоинства - Общее количество операций сравнения гораздо меньше.
Недостатки - Можно оптимизировать только операции равенства, ибо для равных значений равны и значения hash функций, но ">" "<" уже не гарантируются. :( Если коллизии (совпадения hash при разных исходных данных) лягут так, что все строки попадут в одну корзину - то только лишняя работа.
Merge join - построен на том, что если множества упорядочены, то просматривать их целиком не обязательно можно последовательно идти по одному - потом по другому, затем опять по первому и так пока не надоест.
Недостатки - данные надо заранее упорядочить. А если использовать индекс при условии, что таблички не влезают в кеш и будут постоянно вымываться приведет к большому числу операций ввода-вывода.
"
Учитывая индекс и ограничение на первые пять строк - наверное выбор обоснован.
"
Nested loop - (сильно грубое описание) Пробегаем по таблице 1 и для каждой строки из нее смотрим какие строки из таблицы 2 ей подходят.
Обычно очень быстро дает первые строки результата (если конечно таблица 2 не гигантская, а единственная строка из первой таблицы, которая попадет в результат - последняя). Еще алгоритм, практически не требует дополнительной памяти для промежуточной работы и индекс во второй таблице может сильно помочь.
Hash join - Поскольку сравнивать каждую строку с каждой очень долго придумали шаманские танцы. Придумываем некую очень быстро вычислимую функцию от сравниваемых полей возвращающую результат от 1 до N. Просматриваем все строки таблицы 1 и раскладываем их в N корзин. Просматриваем таблицу 2 и для каждой строки проверяем только строки из подходящей корзины.
Достоинства - Общее количество операций сравнения гораздо меньше.
Недостатки - Можно оптимизировать только операции равенства, ибо для равных значений равны и значения hash функций, но ">" "<" уже не гарантируются. :( Если коллизии (совпадения hash при разных исходных данных) лягут так, что все строки попадут в одну корзину - то только лишняя работа.
Merge join - построен на том, что если множества упорядочены, то просматривать их целиком не обязательно можно последовательно идти по одному - потом по другому, затем опять по первому и так пока не надоест.
Недостатки - данные надо заранее упорядочить. А если использовать индекс при условии, что таблички не влезают в кеш и будут постоянно вымываться приведет к большому числу операций ввода-вывода.
"
Учитывая индекс и ограничение на первые пять строк - наверное выбор обоснован.
(10) ок, что такое кластерный индекс? Является ли он отсортированной кучей или отсортированными данными в Вашем понимании?
К тому же я не могу выбрать регистр во временную таблицу, чтобы отсортировать, только на помещение ВТ в TempDB тратится времени больше, чем на выполнение запроса без ВТ. Отдельно сортировку я могу применить только к выборке, которая, к слову получается неоптимально и при этом тратится лишнее время дополнительно. В подзапросе я выборку не могу отсортировать.
К тому же я не могу выбрать регистр во временную таблицу, чтобы отсортировать, только на помещение ВТ в TempDB тратится времени больше, чем на выполнение запроса без ВТ. Отдельно сортировку я могу применить только к выборке, которая, к слову получается неоптимально и при этом тратится лишнее время дополнительно. В подзапросе я выборку не могу отсортировать.
(1)
1) оптимизатор проверяет наличие индекса по полям Число3 + Число2
такого нет. (индексе поля расположены: Число3; Число1; Число2. - это не подходит, поля должны идти подряд Число3 + Число2)
2) есть индекс по Число3, его и используем.
2.1) находим поля в табице, где РС_Тест21.Число3 = РС_Тест2.Число3 т.е. сравниваем одно поле.
2.2) для второго поля приходится осуществлять поиск в не отсортированном массиве.
т.к. записей очень много используется Nested Loops (если бы их было мало, использовалось бы другое соединение, возможно Hash join)
3) топ 5 не возможно наложить сразу на выборку т.к. нужно состыковать вначале поля таблиц.
Мы ведь не берём первые 5 из первой таблицы, а из результатов соединения.
Хотите быстрее?
Создавайте покрывающий индекс. Или включайте поле Число2 как INCLUDE в индекс.
ВЫБРАТЬ ПЕРВЫЕ 5
РС_Тест2.Число1,
РС_Тест21.Число1 КАК Число11
ИЗ
РегистрСведений.РС_Тест2 КАК РС_Тест21
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.РС_Тест2 КАК РС_Тест2
ПО РС_Тест21.Число3 = РС_Тест2.Число3
И РС_Тест21.Число2 = РС_Тест2.Число1
РС_Тест2.Число1,
РС_Тест21.Число1 КАК Число11
ИЗ
РегистрСведений.РС_Тест2 КАК РС_Тест21
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.РС_Тест2 КАК РС_Тест2
ПО РС_Тест21.Число3 = РС_Тест2.Число3
И РС_Тест21.Число2 = РС_Тест2.Число1
1) оптимизатор проверяет наличие индекса по полям Число3 + Число2
такого нет. (индексе поля расположены: Число3; Число1; Число2. - это не подходит, поля должны идти подряд Число3 + Число2)
2) есть индекс по Число3, его и используем.
2.1) находим поля в табице, где РС_Тест21.Число3 = РС_Тест2.Число3 т.е. сравниваем одно поле.
2.2) для второго поля приходится осуществлять поиск в не отсортированном массиве.
т.к. записей очень много используется Nested Loops (если бы их было мало, использовалось бы другое соединение, возможно Hash join)
3) топ 5 не возможно наложить сразу на выборку т.к. нужно состыковать вначале поля таблиц.
Мы ведь не берём первые 5 из первой таблицы, а из результатов соединения.
Хотите быстрее?
Создавайте покрывающий индекс. Или включайте поле Число2 как INCLUDE в индекс.
(18)
1. Есть кластерный индекс по всем полям и именно он и используется, сканируя при этом весь индекс. Далее осуществляется поиск по индексу с условием по полям Т1.Ч3 = Т2.Ч3 и Т1.Ч2 = Т2.Ч1
Оптимизатор правильно выбрал именно кластерный индекс, он является покрывающим.
2. Индекс используется по всем полям
2.1 В переписанном запросе как раз ступенькой: Индекс скан + поиск по Ч3 - Nested Loops - Поиск по Ч2=Ч1
2.2. Почему неотсортированном? Тут скорее всего проблема в пропуске Ч1, т.к. Индекс берется Ч3, Ч1, Ч2
И при большом количестве записей вредно использовать соединение вложенными циклами, для этого как раз и есть хеш и мердж(если таблицы сортированы по полям соединения)
3. Топ 5 по идее должен накладываться на оператор соединения, т.к. поток операторов идет слева направо и запрашивает данные у опреатора, который находится справа.
Индекс уже есть покрывающий, тут пробелма как раз в том, как добиться правильного соединения. В моем случае получить соединение по хешу получилось только избавившись от топ 5. И отработало намного быстрее
1. Есть кластерный индекс по всем полям и именно он и используется, сканируя при этом весь индекс. Далее осуществляется поиск по индексу с условием по полям Т1.Ч3 = Т2.Ч3 и Т1.Ч2 = Т2.Ч1
Оптимизатор правильно выбрал именно кластерный индекс, он является покрывающим.
2. Индекс используется по всем полям
2.1 В переписанном запросе как раз ступенькой: Индекс скан + поиск по Ч3 - Nested Loops - Поиск по Ч2=Ч1
2.2. Почему неотсортированном? Тут скорее всего проблема в пропуске Ч1, т.к. Индекс берется Ч3, Ч1, Ч2
И при большом количестве записей вредно использовать соединение вложенными циклами, для этого как раз и есть хеш и мердж(если таблицы сортированы по полям соединения)
3. Топ 5 по идее должен накладываться на оператор соединения, т.к. поток операторов идет слева направо и запрашивает данные у опреатора, который находится справа.
Индекс уже есть покрывающий, тут пробелма как раз в том, как добиться правильного соединения. В моем случае получить соединение по хешу получилось только избавившись от топ 5. И отработало намного быстрее
(19)
Если в индексе один порядок полей, а в запросе - другой, индекс уже не может работать.
Потому, неотсортированном. По первому полю есть сортировка, по второму нет.
Вы можете на листке бумаги это проверить. Напишите 10 записей и вручную подумайте как происходит поиск?
И поймете, что для второго поля приходится искать в Nested Loops и никакого index seek нет.
Индекс используется по всем полям
Если в индексе один порядок полей, а в запросе - другой, индекс уже не может работать.
2.2. Почему неотсортированном? Тут скорее всего проблема в пропуске Ч1, т.к. Индекс берется Ч3, Ч1, Ч2
Потому, неотсортированном. По первому полю есть сортировка, по второму нет.
Вы можете на листке бумаги это проверить. Напишите 10 записей и вручную подумайте как происходит поиск?
И поймете, что для второго поля приходится искать в Nested Loops и никакого index seek нет.
(20) но разве при таком индексе не будет сортировка:
Число3 Число1 Число2
1 1 2
1 2 3
2 2 4
5 6 9
И как я понимаю, сначала выполнение сканирует индекс по полям Ч3;Ч1;Ч2, затем из строки берет Ч3 и Ч1 с помощью Index Seek Ищет эти значения и так до первых пяти совпадений, или я ошибаюсь? По крайней мере на плане запроса так, вроде
SEEK:([T2].[_Fld758]=[CourseExpert].[dbo].[_InfoRg755].[_Fld758] as [T1].[_Fld758] AND [T2].[_Fld756]=[CourseExpert].[dbo].[_InfoRg755].[_Fld757] as [T1].[_Fld757])
_Fld758 - Число 3; _Fld756 - Число 1; _Fld757 - Число 2
Число3 Число1 Число2
1 1 2
1 2 3
2 2 4
5 6 9
И как я понимаю, сначала выполнение сканирует индекс по полям Ч3;Ч1;Ч2, затем из строки берет Ч3 и Ч1 с помощью Index Seek Ищет эти значения и так до первых пяти совпадений, или я ошибаюсь? По крайней мере на плане запроса так, вроде
SEEK:([T2].[_Fld758]=[CourseExpert].[dbo].[_InfoRg755].[_Fld758] as [T1].[_Fld758] AND [T2].[_Fld756]=[CourseExpert].[dbo].[_InfoRg755].[_Fld757] as [T1].[_Fld757])
_Fld758 - Число 3; _Fld756 - Число 1; _Fld757 - Число 2
(1)Вы про оптимизатор MS SQL? Так он статистику смотрит. Как бэ с претензией на искусственный интеллект и злопамятная своалачь.Типа под тебя подстраивается.Пару раз пронумеровал запросом. То бишь соединил себя с собой. А этот гаденыш запомнил и считает, что так должно быть и в плоском запросе.
Мало того, это недоразумение может недавно переиндексированные таблицы, по привычке кидать в TempDB и с умным видом заниматься помощью тебе родимому.
Не особо силен в админ SQL. Но простые вещи. Раз в неделю foreachtable dbreindex, раз в месяц штатная функция Реструктуризация, сносит все желание тебе "помогать" этому оптимизатору. Ибо нефиг, сами с усами.
Хотя нет. Штатная Реструктуризация. Все же булк инсертом данные запихивает. Может и диск отвалится. Все же без SQL спецов не обойтись
Мало того, это недоразумение может недавно переиндексированные таблицы, по привычке кидать в TempDB и с умным видом заниматься помощью тебе родимому.
Не особо силен в админ SQL. Но простые вещи. Раз в неделю foreachtable dbreindex, раз в месяц штатная функция Реструктуризация, сносит все желание тебе "помогать" этому оптимизатору. Ибо нефиг, сами с усами.
Хотя нет. Штатная Реструктуризация. Все же булк инсертом данные запихивает. Может и диск отвалится. Все же без SQL спецов не обойтись

Кстати, если в студии выполнить переданный запрос, но с OPTION (Hash join), то выполняется в два раза быстрее. Если выставиьт опцию Merge join, то на 100мс выполняется дольше, чем хеш джоин. И это с оператором сортировки, который занимает 96% всего времени
Оптимизировал запрос, переписав на
Время выполнения 375 мс, но опять же все тот же Nested Loops.
Поля Т1.Число3_1, Т1.Число3_2, Т2.Число2_1, Т2.Число1_2 проверочные и никакой другой смысловой нагрузки не дают
И все-равно не дает ответа, почему в первом случае 2М раз нужно делать поиск в индексе
Текст |
|---|
|
Время выполнения 375 мс, но опять же все тот же Nested Loops.
Поля Т1.Число3_1, Т1.Число3_2, Т2.Число2_1, Т2.Число1_2 проверочные и никакой другой смысловой нагрузки не дают
И все-равно не дает ответа, почему в первом случае 2М раз нужно делать поиск в индексе
Судя по всему, помешало как раз таки
Выбрать Первые 5.
Потому что, если выбрать все, то в плане соединение преобразуется в хеш джоин.
Теперь вопрос, господам экспертам, почему оптимизатор ошибся при выборке из кластерного индекса? Почему он предположил, что количество строк будет 5 в случае, если выбирается ТОП 5 и правильно определил в случае полной выборки?
Выбрать Первые 5.
Потому что, если выбрать все, то в плане соединение преобразуется в хеш джоин.
Теперь вопрос, господам экспертам, почему оптимизатор ошибся при выборке из кластерного индекса? Почему он предположил, что количество строк будет 5 в случае, если выбирается ТОП 5 и правильно определил в случае полной выборки?
(14)В описании выше я указывал, что Nested loop считается оптимальным если выборка по ограниченному количеству строк и в таблице присутствует индекс. То, что у Вас таблица из громадного количества строк, по видимому для оптимизатора не является аргументом. И почему выбор не обоснован?
Возможно оптимизатор посчитал стоимость операций и выбрал самый дешёвый вариант.
Вопрос в том, знаем ли мы критерии по которым оптимизатор определяет стоимость каждой операции и какова стоимость других вариантов?
Стоимость операций настраивается, и настойки можно найти, а как посмотреть в sql рассмотренные варианты?
Вопрос в том, знаем ли мы критерии по которым оптимизатор определяет стоимость каждой операции и какова стоимость других вариантов?
Стоимость операций настраивается, и настойки можно найти, а как посмотреть в sql рассмотренные варианты?
1.Планы с совместимостями 110 и (130-140) в студию.
2.Структуру индексов туда же
Логически... ПЕРВЫЕ 5 - можно ли применить только к первой таблице? НЕТ! То что она соединяется сама с собой - вряд ли оптимизатор это понимает. Хотя хотелось бы...
Давайте рассматривать это как соединение двух одинаковых таблиц. Тогда как к чему применять первые 5? Только к РЕЗУЛЬТАТУ.
2.Структуру индексов туда же
Логически... ПЕРВЫЕ 5 - можно ли применить только к первой таблице? НЕТ! То что она соединяется сама с собой - вряд ли оптимизатор это понимает. Хотя хотелось бы...
Давайте рассматривать это как соединение двух одинаковых таблиц. Тогда как к чему применять первые 5? Только к РЕЗУЛЬТАТУ.
Какой запрос такой и план...
ВЫБРАТЬ ПЕРВЫЕ 5
РС_Тест2.Число1,
РС_Тест21.Число1 КАК Число11
ИЗ
РегистрСведений.РС_Тест2 КАК РС_Тест21
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.РС_Тест2 КАК РС_Тест2
ПО РС_Тест21.Число3 = РС_Тест2.Число3
И РС_Тест21.Число2 = РС_Тест2.Число1
выбираем из любой таблицы (на усмотрение оптимизатора, потому что внутреннее не внешнее левое правое соединение) 5 строк - это table scan первых любых 5 строк.
далее из другой таблицы которая соединяется с 1й ищется по условию для каждой из 5и строк данные...
хотя любой джоин может делать дубли конечно, если (число3, число2) и (число3, число1) не уникальны. Ну даже не уникальны один фиг поиск по индексу это наибыстрейшее соединение 5и строк. если уберете первые 5 - план поменяется... попробуйте первые 1000000 - высока вероятность что план будет другим.
ВЫБРАТЬ ПЕРВЫЕ 5
РС_Тест2.Число1,
РС_Тест21.Число1 КАК Число11
ИЗ
РегистрСведений.РС_Тест2 КАК РС_Тест21
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.РС_Тест2 КАК РС_Тест2
ПО РС_Тест21.Число3 = РС_Тест2.Число3
И РС_Тест21.Число2 = РС_Тест2.Число1
выбираем из любой таблицы (на усмотрение оптимизатора, потому что внутреннее не внешнее левое правое соединение) 5 строк - это table scan первых любых 5 строк.
далее из другой таблицы которая соединяется с 1й ищется по условию для каждой из 5и строк данные...
хотя любой джоин может делать дубли конечно, если (число3, число2) и (число3, число1) не уникальны. Ну даже не уникальны один фиг поиск по индексу это наибыстрейшее соединение 5и строк. если уберете первые 5 - план поменяется... попробуйте первые 1000000 - высока вероятность что план будет другим.
(21) да, я писал уже, что на больших наборах данных, даже при выбрать первые 5000 Nested loops меняется на Hash mutch. Но другое дела, что при топ 5, оптимизатор считает, что при скане кластеризованного индекса будет 5 строк, а там 2 миллиона, как следствие соединение вложенными запросами тормозит выполнение
Т.е. вопрос в том, почему сразу не используется hash match вместо nested loops?
Ответ на этот и многие другие вопросы в нашем новом журнале "а хрен его знает".
Похоже на ошибку оптимизации. По сути, это свалка эвристик. Может, когда на нейросетку перепишут, будет лучше :)
Ответ на этот и многие другие вопросы в нашем новом журнале "а хрен его знает".
Похоже на ошибку оптимизации. По сути, это свалка эвристик. Может, когда на нейросетку перепишут, будет лучше :)
(25)да, именно это меня и интересует. Ведь оптимизатор прекрасно должен знать, сколько записей в таблице регистра, но почему то ошибается в плане. Причем и на 2012 и на 2016 SQL.
Причем, если выбрать не 5, а 5000 записей, то он берет правильное соединение
Причем, если выбрать не 5, а 5000 записей, то он берет правильное соединение
Прикрепленные файлы:
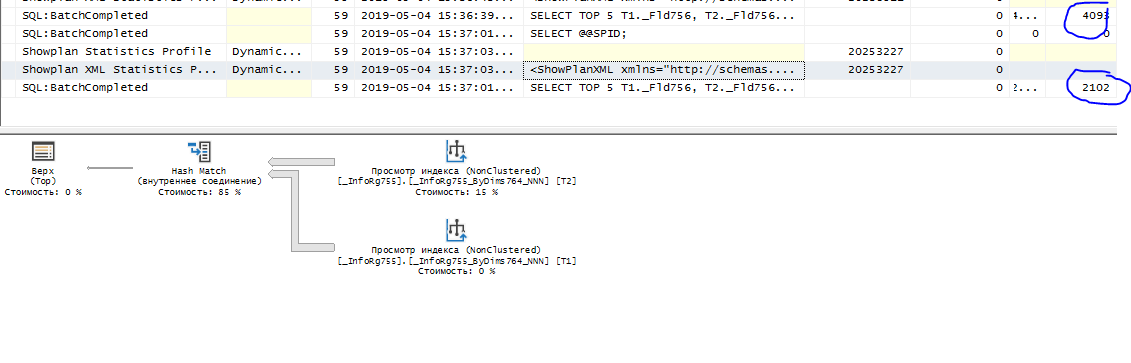
(27) это давно известна фича TOP. План запроса теряется при этом. Может построить как оптимальный план, так и не очень.
Ну и конечно перед каждым экспериментом необходимо сбрасывать статистику, иначе просто каждый раз будет браться предыдущий сформированный план.
Ну и конечно перед каждым экспериментом необходимо сбрасывать статистику, иначе просто каждый раз будет браться предыдущий сформированный план.
А по какой причине вы решили, что hash соединение - правильное? А nested loop - не правильное?
Hash - это построение временной таблицы с хешами от полей соединения, оптимизатор берет меньшую таблицу как правило при INNER JOIN, но в вашем случае вы одну и туже таблицу соединяете на себя же.
В случае top(5000) оптимизатор посчитал, что прочитать и построить таблицу хэшей дешевле, нежели делать 5000 лупов, в случае 5 строк, проще сделать 5 лупов, нежели читать полностью с диска всю таблицу для построения хэшей...
Hash - это построение временной таблицы с хешами от полей соединения, оптимизатор берет меньшую таблицу как правило при INNER JOIN, но в вашем случае вы одну и туже таблицу соединяете на себя же.
В случае top(5000) оптимизатор посчитал, что прочитать и построить таблицу хэшей дешевле, нежели делать 5000 лупов, в случае 5 строк, проще сделать 5 лупов, нежели читать полностью с диска всю таблицу для построения хэшей...
В данном случае топ 5 не обойдется выборкой 5 строк исходной таблицы.
Хотя стоп. Вроде ж тут при топ 5 в самом деле достаточно пяти итераций на вложенных циклах. Почему же тогда выполнение в два раза медленнее получается? Неправильно учтенная оптимизатором статистика? Выходит, при этих условиях даже 5 итераций на вложенных циклах дороже построения хэша?
(31) Почему вы так решили? То что иннер джоин может отсечь часть строк при выборке первых пяти строк из за джоина? Ну... теоретически это возможно... что в милионной таблице без TOP выборка будет 10 тыс строк, т.е. меньше процента данных попадет в выборку. Но опять же, для того что бы понимать попадет или не попадет, у оптимизатора есть статистика, он на нее ориентируется. И я описываю как работает оптимизатор а не как на самом деле оптимально. Что бы знать как на самом деле оптимально, необходимы знания а не догадки, например - сколько вообще в таблице строк, сколько весит таблица в килобайтах или страницах, сколько без ПЕРВЫЕ/TOP вообще строк вернет запрос и сколько из них задублится по условию соединения.
(36) Не факт, ессно. Но с другой стороны их может быть и не одна. По-идее, статистическую вероятность оптимизатор должен учитывать по данным статистики.
Так что оценка вполне реальна может быть (оценка ведь не 5, а 4.99985). Хотя признаюсь, в части тонкостей работы сиквельного оптимизатора я невеликий практик.
ЗЫ. Вот почему оценка так сильно разошлась с реальностью - вариантов вижу только три. Неактуальная статистика (но это вроде исключили), ошибка оптимизатора либо просто очень сильно не повезло (конкретный вариант оказался слишком далек от медианы).
Так что оценка вполне реальна может быть (оценка ведь не 5, а 4.99985). Хотя признаюсь, в части тонкостей работы сиквельного оптимизатора я невеликий практик.
ЗЫ. Вот почему оценка так сильно разошлась с реальностью - вариантов вижу только три. Неактуальная статистика (но это вроде исключили), ошибка оптимизатора либо просто очень сильно не повезло (конкретный вариант оказался слишком далек от медианы).
(35) Да, но не только, не наш случай. Еще луп выбирается, когда лупов не много, пусть даже луп и в небольшой таблице. А хэш, нужно понимать - это дополнительные накладные расходы на построение хэшей. В 1С на эту таблицу сделайте 2 индекса:
1. (Число3, Число2) или (Число2, Число3)
2. (Число3, Число1) или (Число1, Число3)
Ваш запрос существенно ускорится, избавитесь от хэш ))) Скорее всего мерж будет соединение
У хэш соединения есть один замечательный плюс, на джоинах огромных таблиц в мощных серверах - хэш джоин прекрасно параллелится, майкрасофт хоть и заявляет самое эффективное соединение мерж (без сортировок предварительных конечно же), но практика показывает, что на монструозных серверах на больших объемах данных хэш по скорости уделывает прочие типы физических соединений, в остальных случаях хэш приемлем, но не лучший вариант - это означает, что хэш возникает из за того что не хватает индекса
1. (Число3, Число2) или (Число2, Число3)
2. (Число3, Число1) или (Число1, Число3)
Ваш запрос существенно ускорится, избавитесь от хэш ))) Скорее всего мерж будет соединение
У хэш соединения есть один замечательный плюс, на джоинах огромных таблиц в мощных серверах - хэш джоин прекрасно параллелится, майкрасофт хоть и заявляет самое эффективное соединение мерж (без сортировок предварительных конечно же), но практика показывает, что на монструозных серверах на больших объемах данных хэш по скорости уделывает прочие типы физических соединений, в остальных случаях хэш приемлем, но не лучший вариант - это означает, что хэш возникает из за того что не хватает индекса
Вкратце... MSSQL в БД хранит данные в 8ми килобайтных страницах, т.е. если одна строка в среднем это 50 байтов, то в странице таких примерно 160 строк.
Например размер вашей таблицы 100 тыс строк, т.е. 625 страниц 8ми килобайтных на диске = 5 мегабайтов.
При запросе где ПЕРВЫЕ 5, оптимизатор читает 5 строк из одной таблицы - 1 страница, и 5 LOOP - 5 страниц соединенной таблицы = 6 страниц.
Если бы выбрал хэш, то для хэша нужно было бы прочитать 625 страниц для соединенной таблицы и еще одну для первых 5 строк - это 626 страниц. Очевидно что выгоднее прочитать 6 страниц чем 626 - выбран план с луп соединением.
Когда в запросе ПЕРВЫЕ 5000, то для чтения первых 5000 нужно прочитать - 5000/160 (160 строк в одной странице) = 32 страницы. И для хэша мы уже выяснили 625 страниц - итого 32+625 = 657 страниц. Но если оптимизатор выберет луп, то читать придется 32 страницы для первых 5000 строк и еще 5000 страниц - для каждого лупа страница перечитывается - мы имеем 5625 чтений. Здесь очевидно что хэш даст 657 страниц, луп даст 5625 - выгоднее хэш.
Т.е. нужно понимать, что когда указываем TOP/ПЕРВЫЕ нужно оценивать, а сколько вообще в таблице строк? Для хэша потребуется чтение всей таблицы... Для миллиарда строк и ПЕРВЫЕ 5000 - будет луп соединение
Например размер вашей таблицы 100 тыс строк, т.е. 625 страниц 8ми килобайтных на диске = 5 мегабайтов.
При запросе где ПЕРВЫЕ 5, оптимизатор читает 5 строк из одной таблицы - 1 страница, и 5 LOOP - 5 страниц соединенной таблицы = 6 страниц.
Если бы выбрал хэш, то для хэша нужно было бы прочитать 625 страниц для соединенной таблицы и еще одну для первых 5 строк - это 626 страниц. Очевидно что выгоднее прочитать 6 страниц чем 626 - выбран план с луп соединением.
Когда в запросе ПЕРВЫЕ 5000, то для чтения первых 5000 нужно прочитать - 5000/160 (160 строк в одной странице) = 32 страницы. И для хэша мы уже выяснили 625 страниц - итого 32+625 = 657 страниц. Но если оптимизатор выберет луп, то читать придется 32 страницы для первых 5000 строк и еще 5000 страниц - для каждого лупа страница перечитывается - мы имеем 5625 чтений. Здесь очевидно что хэш даст 657 страниц, луп даст 5625 - выгоднее хэш.
Т.е. нужно понимать, что когда указываем TOP/ПЕРВЫЕ нужно оценивать, а сколько вообще в таблице строк? Для хэша потребуется чтение всей таблицы... Для миллиарда строк и ПЕРВЫЕ 5000 - будет луп соединение
(30) а может ли тут быть проблема в том, что порядок в индексе Ч3, Ч1, Ч2, и от соединения Ч2=Ч1 у оптимизатора сорвало крышу? Потому что, когда я переписал запрос, используя только по одному условию соединения, Выбрать .... Ч3=Ч3 Как Т1 внутреннее соединение Выбрать .... Ч2 = Ч1 тогда все залетало как надо, и стрелочки на плане тонюсенькие стали
Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот