Открытие PDF в новом поле HTML на WebKit
Коллеги, в связи с внедрением WebKit в поле HMTL документа в платформе 8.3.14 появились новые возможности, но и перестали работать старые.
К сожалению, я не спец в WebKit и прошу помощи, как теперь отобразить PDF на поле HTML документа. Желательно без сохранения файла.
Раньше код был следующий:
Теперь же он уже не работает, а попытки его модификации ни к чему пока не привели. У кого какие есть идеи по решению вопроса?
К сожалению, я не спец в WebKit и прошу помощи, как теперь отобразить PDF на поле HTML документа. Желательно без сохранения файла.
Раньше код был следующий:
HTMLДокумент = "<ht ml>
| <head>
| </head>
| <body>
| <EMB ED width=100% height=100% type=""application/pdf"" src=""" + АдресФайла + """></EMBED>
| </body>
|</html>";
ПоказатьТеперь же он уже не работает, а попытки его модификации ни к чему пока не привели. У кого какие есть идеи по решению вопроса?
По теме из базы знаний
Найденные решения
Итоговый код открытия PDF в новых версиях платформы 1С.
Тот же код найдёте и в приложенном файле для удобства использования, поскольку сайт портит теги скрипта, добавляя лишние пробелы.
Примечание: масштаб отображения можно регулировать, меняя переменную scale в коде скрипта.
Тот же код найдёте и в приложенном файле для удобства использования, поскольку сайт портит теги скрипта, добавляя лишние пробелы.
Примечание: масштаб отображения можно регулировать, меняя переменную scale в коде скрипта.
СтрокаPDFФайла = ПолучитьBase64СтрокуИзДвоичныхДанных(ПолучитьИзВременногоХранилища(АдресФайла));
// Или, например:
// ДД = Новый ДвоичныеДанные(Результат.ПолноеИмяФайла);
// СтрокаPDFФайла = ПолучитьBase64СтрокуИзДвоичныхДанных(ДД);
HTMLДокумент = "<!DO CTYPE html>
|<ht ml>
| <head>
| <met a http-equiv=""Content-Type"" content=""text/html; charset=UTF-8"" />
| <met a name=""viewport"" content=""width=device-width, initial-scale = 1.0, maximum-scale = 1.0, user-scalable=no"">
| <sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.4.456/pdf.min.js""></sc ript>
| <sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.4.456/pdf.worker.min.js""></sc ript>
| <canvas id=""the-canvas""></canvas>
| <sc ript>
| var currPage = 1; //Pages are 1-based not 0-based
| var numPages = 0;
| var thePDF = null;
|
| var loadingTask = pdfjsLib.getDocument({data: atob(`" + СтрокаPDFФайла + "`)});
| loadingTask.promise.then(function(pdf) {
|
| thePDF = pdf;
| numPages = pdf.numPages;
|
| pdf.getPage(1).then(handlePages);
|
| function handlePages(page) {
| var scale = 1.5;
|
| var viewport = page.getViewport({scale: scale});
|
| var canvas = document.createElement( ""canvas"" );
| canvas.style.display = ""block"";
| var context = canvas.getContext('2d');
| canvas.height = viewport.height;
| canvas.width = viewport.width;
|
| var renderContext = {
| canvasContext: context,
| viewport: viewport
| };
| var renderTask = page.render(renderContext);
|
| document.body.appendChild( canvas );
|
| currPage++;
| if ( thePDF !== null && currPage <= numPages )
| {
| thePDF.getPage( currPage ).then( handlePages );
| }
| };
|
| });
| </sc ript>
| </body>
|</html>";
ПоказатьПрикрепленные файлы:
Код открытия PDF в WebKit.txt
Остальные ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
(1) самое интересное, что этот код - РАБОТАЕТ!!!
Но криво работает. 1С как всегда в своем репертуаре...
Если в отладчике в событии ПолеХТМЛДокументаДокументСформирован в "вычислить выражение" посмотреть Элементы.ПолеХТМЛДокумента.Документ,
то при продолжении отладки содержимое pdf отлично показывается. НО!!! До перезапуска предприятия ломается сохранение любых табличных документов в pdf. Т.е. документ сохраняется, но просмотреть его не получается. Битый файл сохраняется.
Им бы баг репорт накатать... Кто может?
HTMLДокумент = "<ht ml>
| <head>
| </head>
| <body>
| <EMB ED width=100% height=100% type=""application/pdf"" src=""" + АдресФайла + """></EMBED>
| </body>
|</html>";
Но криво работает. 1С как всегда в своем репертуаре...
Если в отладчике в событии ПолеХТМЛДокументаДокументСформирован в "вычислить выражение" посмотреть Элементы.ПолеХТМЛДокумента.Документ,
то при продолжении отладки содержимое pdf отлично показывается. НО!!! До перезапуска предприятия ломается сохранение любых табличных документов в pdf. Т.е. документ сохраняется, но просмотреть его не получается. Битый файл сохраняется.
Им бы баг репорт накатать... Кто может?
Движок WebKit не поддерживает работу с PDF. В тонком клиенте для Windows раньше использовался Internet Explorer, который также не поддерживал работу с pdf-файлами. Однако при установке Adobe Acrobar Reader дополнительно устанавливался плагин к Internet Explorer, который и позволял просматривать pdf-файлы в полях HTML.
В случае веб-клиента 1С все будет зависеть от браузера. К примеру тот же хром поддерживает работу с pdf-файлами и вы сможете увидеть содержимое. Хромиум и Опера эту возможность не поддерживают.
В случае веб-клиента 1С все будет зависеть от браузера. К примеру тот же хром поддерживает работу с pdf-файлами и вы сможете увидеть содержимое. Хромиум и Опера эту возможность не поддерживают.
Я не силён в web, поэтому ни черта не понимаю... Должен, по идее, работать такой код, но не работает... Пример взят с сайта выше по ссылке.
HTMLДокумент = "<!DO CTYPE html>
|<ht ml>
|<head>
|<met a http-equiv=""Content-Type"" content=""text/html; charset=UTF-8"" />
|<met a name=""viewport"" content=""width=device-width, initial-scale = 1.0, maximum-scale = 1.0, user-scalable=no"">
|<sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.2.2/pdf.min.js""></sc ript>
|<sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.2.2/pdf.worker.min.js""></sc ript>
|<canvas id=""the-canvas""></canvas>
|<sc ript>
|// atob() is used to convert base64 encoded PDF to binary-like data.
|// (See also
|// Base64_encoding_and_decoding.)
|var pdfData = atob(" + ПолучитьBase64СтрокуИзДвоичныхДанных(ПолучитьИзВременногоХранилища(АдресФайла)) + ");
|
|// Loaded via <sc ript> tag, create shortcut to access PDF.js exports.
|var pdfjsLib = window['pdfjs-dist/build/pdf'];
|// The workerSrc property shall be specified.
|pdfjsLib.GlobalWorkerOptions.workerSrc = '//mozilla.github.io/pdf.js/build/pdf.worker.js';
|// Using DocumentInitParameters object to load binary data.
|var loadingTask = pdfjsLib.getDocument({data: pdfData});
|loadingTask.promise.then(function(pdf) {
| console.log('PDF loaded');
|
| // Fetch the first page
| var pageNumber = 1;
| pdf.getPage(pageNumber).then(function(page) {
| console.log('Page loaded');
|
| var scale = 1.5;
| var viewport = page.getViewport({scale: scale});
| // Prepare canvas using PDF page dimensions
| var canvas = document.getElementById('the-canvas');
| var context = canvas.getContext('2d');
| canvas.height = viewport.height;
| canvas.width = viewport.width;
| // Render PDF page into canvas context
| var renderContext = {
| canvasContext: context,
| viewport: viewport
| };
| var renderTask = page.render(renderContext);
| renderTask.promise.then(function () {
| console.log('Page rendered');
| });
| });
|}, function (reason) {
| // PDF loading error
| console.error(reason);
|});
|</sc ript>
|</body>
|</html>";
Показать
(5)
Вашему примеру не хватает тильды в функции atob(``), без них на 8.3.15.1700 изображение не появлялось. А так: спасибо, был избавлен он мучительного поиска в сети.
|var pdfData = atob(`" + ПолучитьBase64СтрокуИзДвоичныхДанных(ПолучитьИзВременногоХранилища(АдресФайла)) + "`);
Вашему примеру не хватает тильды в функции atob(``), без них на 8.3.15.1700 изображение не появлялось. А так: спасибо, был избавлен он мучительного поиска в сети.
(14) у меня не взлетело: тексты большие, прямое копирование в текстовый макет в конфигураторе зависает. Если же загрузить файлы в макеты двоичных данных - то ошибка xdto при клиент-серверном переходе. Как понял, скрипт worker содержит недопустимые xdto-символы.
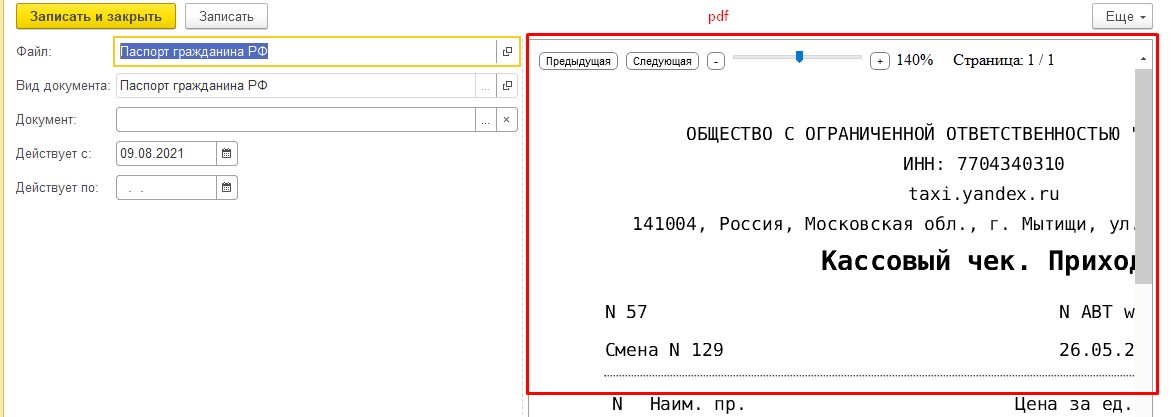
(11) Да, про то, что нужно тильды вставлять вместо апострофов, я бы никогда не догадался. Действительно, так заработало, но с большими ограничениями! Показывается только первая страница PDF, а так же недоступно масштабирование. Имейте в виду те, кто будет внедрять. А решение по полному отображению PDF со всеми страницами, масштабированию, да возможностью выделения/копирования текста - пока продолжаем искать.
(22) Дописал немного. При печати скрывается блок с кнопками и номером страницы.
Прикрепленные файлы:
Смотрелка PDF.epf
Скопировал код напрямую в текст, страничка стала отображаться, причем, даже в веб-клиенте(!), так что решение возможно, нужны только познания в этой области, чтобы правильно прописать код странички, да наладить взаимодействие.
Web-спецы, ауу!! :)
Web-спецы, ауу!! :)
(6)
Я не веб спец, но как уже писал выше в веб-клиенте оно и будет работать при поддержке pdf самим браузером. Мои коллеги (веб-программисты) посмотрели этот скрипт и сказали, что здесь идет преобразование pdf в картинку и только 1 листа. Для вывода много страничного документа необходимо сделать цикл.
Я не веб спец, но как уже писал выше в веб-клиенте оно и будет работать при поддержке pdf самим браузером. Мои коллеги (веб-программисты) посмотрели этот скрипт и сказали, что здесь идет преобразование pdf в картинку и только 1 листа. Для вывода много страничного документа необходимо сделать цикл.
(7) Ваши коллеги могут посмотреть исходный код библиотеки выше по ссылке на github? Там есть примеры онлайн просмотра и многостраничного документа с кучей элементов управления, т.е. аналог Acrobat Reader на JS. Нужно преобразовать этот код под реалии 1С, т.е. запихнуть всё в один файл. Выше я привел лишь пример одностраничного кода, не говорил же, что это результат.
И да, работать будет во всех современных браузерах вне зависимости от поддержки PDF.
Вот прямая ссылка на онлайн просмотр PDF силами JS:
Доступно и выделение текста, и просмотр всех страниц, и печать, в общем - полноценная работа с файлом.
И да, работать будет во всех современных браузерах вне зависимости от поддержки PDF.
Вот прямая ссылка на онлайн просмотр PDF силами JS:
Доступно и выделение текста, и просмотр всех страниц, и печать, в общем - полноценная работа с файлом.
Накидал обработку на УФ. Проверял в CRM.
В макете обработки страница для рисования и второй макет - собственно pdf для просмотра. Сам принцип думаю понятен, дальше можно адаптировать как угодно.
Взял один из примеров на сайте, где постранично выводится файл и немного адаптировал пример.
В макете обработки страница для рисования и второй макет - собственно pdf для просмотра. Сам принцип думаю понятен, дальше можно адаптировать как угодно.
Взял один из примеров на сайте, где постранично выводится файл и немного адаптировал пример.
Прикрепленные файлы:
Смотрелка PDF.epf
(17)В идеале хорошо. Вот что я смог добиться от своих программистов. Показывает все страницы!
&НаСервере
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
Если ЭтоАдресВременногоХранилища(Параметры.Адрес) Тогда
ДвоичныеДанные = ПолучитьИзВременногоХранилища(Параметры.Адрес);
Если не ПустаяСтрока(Параметры.Заголовок) Тогда
АвтоЗаголовок = Ложь;
Заголовок = Параметры.Заголовок;
КонецЕсли;
Поле =
"<!DO CTYPE html>
|<ht ml>
|<head>
|<met a http-equiv=""Content-Type"" content=""text/html; charset=UTF-8"" />
|<met a name=""viewport"" content=""width=device-width, initial-scale = 1.0, maximum-scale = 1.0, user-scalable=no"">
|<sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.2.2/pdf.min.js""></sc ript>
|<sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.2.2/pdf.worker.min.js""></sc ript>
|<div id=""holder""></div>
|<sc ript>
|// atob() is used to convert base64 encoded PDF to binary-like data.
|// (See also
|// Base64_encoding_and_decoding.)
|var pdfData = atob(`" + ПолучитьBase64СтрокуИзДвоичныхДанных(ДвоичныеДанные) + "`);
|// Loaded via <sc ript> tag, create shortcut to access PDF.js exports.
|var pdfjsLib = window['pdfjs-dist/build/pdf'];
|// The workerSrc property shall be specified.
|pdfjsLib.GlobalWorkerOptions.workerSrc = '//mozilla.github.io/pdf.js/build/pdf.worker.js';
|// Using DocumentInitParameters object to load binary data.
|var loadingTask = pdfjsLib.getDocument({data: pdfData});
|loadingTask.promise.then(function(pdf)
|{
| var canvasContainer = document.getElementById('holder');
| console.log('PDF loaded');
|
| for(var pageNumber = 1; pageNumber <= pdf.numPages; pageNumber++){
| console.log(pageNumber);
|
| pdf.getPage(pageNumber).then(function(page) {
| console.log('Page loaded');
|
| var scale = 1.0;
| var viewport = page.getViewport({scale: scale});
| var canvas = document.createElement('canvas');
| var context = canvas.getContext('2d');
| canvas.height = viewport.height;
| canvas.width = viewport.width;
| var renderContext = {
| canvasContext: context,
| viewport: viewport
| };
| canvasContainer.appendChild(canvas);
| var renderTask = page.render(renderContext);
| renderTask.promise.then(function () {
| console.log('Page rendered');
| });
| });
|}
|},
|function (reason) {
| // PDF loading error
| console.error(reason);
|});
|</sc ript>
|</body>
|</html>";
Иначе
Отказ = Истина;
КонецЕсли;
КонецПроцедуры
Показать
(40)Дело не в платформе, дело в мозилле. Они поменяли библиотеку и в версии 2.4.456 от 20 марта не работает всё в WebKit и IE/Edge. Лечится использованием старых библиотек.
Допустим, в строках
и
Нужно написать
и
У меня с этими изменениями всё заработало в 8.3.15.1830)
Суммарно такой HTML получается:
Допустим, в строках
<sc ript src="https://mozilla.github.io/pdf.js/build/pdf.js"></sc ript
и
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://mozilla.github.io/pdf.js/build/pdf.worker.js'
Нужно написать
<sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.3.200/pdf.js""></sc ript>
и
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.3.200/pdf.worker.js'
У меня с этими изменениями всё заработало в 8.3.15.1830)
Суммарно такой HTML получается:
<!do ctype html>
<ht ml>
<head>
<sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.3.200/pdf.js""></sc ript>
<sc ript>
addEventListener('load',e=>{
var BinData = atob(`<ba se64pdf>`);
// Loaded via <sc ript> tag, create shortcut to access PDF.js exports.
var pdfjsLib = window['pdfjs-dist/build/pdf'];
// The workerSrc property shall be specified.
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.3.200/pdf.worker.js';
var pdfDoc = null,
pageNum = 1,
pageRendering = false,
pageNumPending = null,
scale = 0.8,
canvas = document.getElementById('the-canvas'),
ctx = canvas.getContext('2d');
/**
* Get page info from document, resize canvas accordingly, and render page.
* *param num Page number.
*/
function renderPage(num) {
pageRendering = true;
// Using promise to fetch the page
pdfDoc.getPage(num).then(function(page) {
var viewport = page.getViewport({scale: scale});
canvas.height = viewport.height;
canvas.width = viewport.width;
// Render PDF page into canvas context
var renderContext = {
canvasContext: ctx,
viewport: viewport
};
var renderTask = page.render(renderContext);
// Wait for rendering to finish
renderTask.promise.then(function() {
pageRendering = false;
if (pageNumPending !== null) {
// New page rendering is pending
renderPage(pageNumPending);
pageNumPending = null;
}
});
});
// Update page counters
document.getElementById('page_num').textContent = num;
}
/**
* If another page rendering in progress, waits until the rendering is
* finised. Otherwise, executes rendering immediately.
*/
function queueRenderPage(num) {
if (pageRendering) {
pageNumPending = num;
} else {
renderPage(num);
}
}
/**
* Displays previous page.
*/
function onPrevPage() {
if (pageNum <= 1) {
return;
}
pageNum--;
queueRenderPage(pageNum);
}
document.getElementById('prev').addEventListener('click', onPrevPage);
/**
* Displays next page.
*/
function onNextPage() {
if (pageNum >= pdfDoc.numPages) {
return;
}
pageNum++;
queueRenderPage(pageNum);
}
document.getElementById('next').addEventListener('click', onNextPage);
/**
* Asynchronously downloads PDF.
*/
pdfjsLib.getDocument({data: BinData}).promise.then(function(pdfDoc_) {
pdfDoc = pdfDoc_;
document.getElementById('page_count').textContent = pdfDoc.numPages;
// Initial/first page rendering
renderPage(pageNum);
});
});
</sc ript>
<st yle>
*media print{
.noprint {
display:none;
}
}
</style>
</head>
<body>
<div class=noprint>
<button id=""prev"">Предыдущая</button>
<button id=""next"">Следующая</button>
<span>Page: <span id=""page_num""></span> / <span id=""page_count""></span></span>
</div>
<canvas id=""the-canvas""></canvas>
</body>
</html>
Показать
Немного дополнил код от @deGreese. Теперь страницы на русском и добавил кнопки увеличения и уменьшения масштаба.
<!do ctype html>
<ht ml>
<head>
<sc ript src="https://mozilla.github.io/pdf.js/build/pdf.js"></sc ript>
<sc ript>
addEventListener('load',e=>{
var BinData = atob(`<ba se64pdf>`);
// Loaded via <sc ript> tag, create shortcut to access PDF.js exports.
var pdfjsLib = window['pdfjs-dist/build/pdf'];
// The workerSrc property shall be specified.
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://mozilla.github.io/pdf.js/build/pdf.worker.js';
var pdfDoc = null,
pageNum = 1,
pageRendering = false,
pageNumPending = null,
scale = 1,
canvas = document.getElementById('the-canvas'),
ctx = canvas.getContext('2d');
/**
* Get page info from document, resize canvas accordingly, and render page.
* @param num Page number.
*/
function renderPage(num) {
pageRendering = true;
// Using promise to fetch the page
pdfDoc.getPage(num).then(function(page) {
var viewport = page.getViewport({scale: scale});
canvas.height = viewport.height;
canvas.width = viewport.width;
// Render PDF page into canvas context
var renderContext = {
canvasContext: ctx,
viewport: viewport
};
var renderTask = page.render(renderContext);
// Wait for rendering to finish
renderTask.promise.then(function() {
pageRendering = false;
if (pageNumPending !== null) {
// New page rendering is pending
renderPage(pageNumPending);
pageNumPending = null;
}
});
});
// Update page counters
document.getElementById('page_num').textContent = num;
}
/**
* If another page rendering in progress, waits until the rendering is
* finised. Otherwise, executes rendering immediately.
*/
function queueRenderPage(num) {
if (pageRendering) {
pageNumPending = num;
} else {
renderPage(num);
}
}
/**
* Displays previous page.
*/
function onPrevPage() {
if (pageNum <= 1) {
return;
}
pageNum--;
queueRenderPage(pageNum);
}
document.getElementById('prev').addEventListener('click', onPrevPage);
/**
* Displays next page.
*/
function onNextPage() {
if (pageNum >= pdfDoc.numPages) {
return;
}
pageNum++;
queueRenderPage(pageNum);
}
document.getElementById('next').addEventListener('click', onNextPage);
/**
* Zoom Out.
*/
function onZoomOut() {
scale = scale - 0.2;
queueRenderPage(pageNum);
}
document.getElementById('ZoomOut').addEventListener('click', onZoomOut);
/**
* Zoom In.
*/
function onZoomIn() {
scale = scale + 0.2;
queueRenderPage(pageNum);
}
document.getElementById('ZoomIn').addEventListener('click', onZoomIn);
/**
* Asynchronously downloads PDF.
*/
pdfjsLib.getDocument({data: BinData}).promise.then(function(pdfDoc_) {
pdfDoc = pdfDoc_;
document.getElementById('page_count').textContent = pdfDoc.numPages;
// Initial/first page rendering
renderPage(pageNum);
});
});
</sc ript>
<st yle>
@media print{
.noprint {
display:none;
}
}
</style>
</head>
<body>
<div class=noprint>
<button id="prev">Предыдущая</button>
<button id="next">Следующая</button>
<span>Страница: <span id="page_num"></span> из <span id="page_count"></span></span>
<button id="ZoomOut">-</button>
<button id="ZoomIn">+</button>
</div>
<canvas id="the-canvas"></canvas>
</body>
</html> Показать
(29) Собственно, немного переделал для собственных нужд, однако оно работает
Добавил открытие файлов с компьютера (doc, xls, pdf)
Добавил кнопки масштаба
Добавил открытие файлов с компьютера (doc, xls, pdf)
Добавил кнопки масштаба
Прикрепленные файлы:
ОткрытиеPDF.epf
Кстати, у кого-нибудь получилось добавить кнопку печати?
Код <button on click="window.print()"> Print</button> печатает только то, что изображено на html (впрочем не удивительно).
Был бы признателен, если кто-то подкинул идею, как можно это реализовать и в каком направлении копать
Код <button on click="window.print()"> Print</button> печатает только то, что изображено на html (впрочем не удивительно).
Был бы признателен, если кто-то подкинул идею, как можно это реализовать и в каком направлении копать
Была такая же задача. Представляю упрощённый вариант на основе ответов выше. Получилось вывести все страницы с прокруткой мышью без использования доп.кнопок
ДД = Новый ДвоичныеДанные(Результат.ПолноеИмяФайла);
ксфТекущаяПечатнаяФормаПдф = "<!DO CTYPE html>
|<ht ml>
|<head>
|<met a http-equiv=""Content-Type"" content=""text/html; charset=UTF-8"" />
|<met a name=""viewport"" content=""width=device-width, initial-scale = 1.0, maximum-scale = 1.0, user-scalable=no"">
|<sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.2.2/pdf.min.js""></sc ript>
|<sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.2.2/pdf.worker.min.js""></sc ript>
|<canvas id=""the-canvas""></canvas>
|<sc ript>
|var currPage = 1; //Pages are 1-based not 0-based
|var numPages = 0;
|var thePDF = null;
|
|var loadingTask = pdfjsLib.getDocument({data: atob(`" + ПолучитьBase64СтрокуИзДвоичныхДанных(ДД) + "`)});
|loadingTask.promise.then(function(pdf) {
|
| thePDF = pdf;
| numPages = pdf.numPages;
|
| pdf.getPage(1).then(handlePages);
|
| function handlePages(page) {
| var scale = 1.5;
|
| var viewport = page.getViewport({scale: scale});
|
| var canvas = document.createElement( ""canvas"" );
| canvas.style.display = ""block"";
| var context = canvas.getContext('2d');
| canvas.height = viewport.height;
| canvas.width = viewport.width;
|
| var renderContext = {
| canvasContext: context,
| viewport: viewport
| };
| var renderTask = page.render(renderContext);
|
| document.body.appendChild( canvas );
|
| currPage++;
| if ( thePDF !== null && currPage <= numPages )
| {
| thePDF.getPage( currPage ).then( handlePages );
| }
| };
|
|});
|</sc ript>
|</body>
|</html>";
Показать
(44) Супер! Вы молодец! Протестировал и заменил свои прежние решения. Но доработал и Ваше, заменив версию библиотеки на новую 2.4.456. Крайне рекомендую и Вам это сделать, поскольку открытие больших файлов надолго подвешивало программу, а в новых же версиях они сделали постепенную подгрузку. Не смотря на то, что выше писали, что эта версия не работает, у меня на 8.3.18.1208 всё отлично.
Итоговый код открытия PDF в новых версиях платформы 1С.
Тот же код найдёте и в приложенном файле для удобства использования, поскольку сайт портит теги скрипта, добавляя лишние пробелы.
Примечание: масштаб отображения можно регулировать, меняя переменную scale в коде скрипта.
Тот же код найдёте и в приложенном файле для удобства использования, поскольку сайт портит теги скрипта, добавляя лишние пробелы.
Примечание: масштаб отображения можно регулировать, меняя переменную scale в коде скрипта.
СтрокаPDFФайла = ПолучитьBase64СтрокуИзДвоичныхДанных(ПолучитьИзВременногоХранилища(АдресФайла));
// Или, например:
// ДД = Новый ДвоичныеДанные(Результат.ПолноеИмяФайла);
// СтрокаPDFФайла = ПолучитьBase64СтрокуИзДвоичныхДанных(ДД);
HTMLДокумент = "<!DO CTYPE html>
|<ht ml>
| <head>
| <met a http-equiv=""Content-Type"" content=""text/html; charset=UTF-8"" />
| <met a name=""viewport"" content=""width=device-width, initial-scale = 1.0, maximum-scale = 1.0, user-scalable=no"">
| <sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.4.456/pdf.min.js""></sc ript>
| <sc ript src=""https://cdnjs.cloudflare.com/ajax/libs/pdf.js/2.4.456/pdf.worker.min.js""></sc ript>
| <canvas id=""the-canvas""></canvas>
| <sc ript>
| var currPage = 1; //Pages are 1-based not 0-based
| var numPages = 0;
| var thePDF = null;
|
| var loadingTask = pdfjsLib.getDocument({data: atob(`" + СтрокаPDFФайла + "`)});
| loadingTask.promise.then(function(pdf) {
|
| thePDF = pdf;
| numPages = pdf.numPages;
|
| pdf.getPage(1).then(handlePages);
|
| function handlePages(page) {
| var scale = 1.5;
|
| var viewport = page.getViewport({scale: scale});
|
| var canvas = document.createElement( ""canvas"" );
| canvas.style.display = ""block"";
| var context = canvas.getContext('2d');
| canvas.height = viewport.height;
| canvas.width = viewport.width;
|
| var renderContext = {
| canvasContext: context,
| viewport: viewport
| };
| var renderTask = page.render(renderContext);
|
| document.body.appendChild( canvas );
|
| currPage++;
| if ( thePDF !== null && currPage <= numPages )
| {
| thePDF.getPage( currPage ).then( handlePages );
| }
| };
|
| });
| </sc ript>
| </body>
|</html>";
ПоказатьПрикрепленные файлы:
Код открытия PDF в WebKit.txt
(48) Изменение масштаба лично у себя счёл удобнее сделать через поле на форме без встраивания кнопок в код страницы. Изменение масштаба работает путем подмены этого места кода в тексте страницы и перерисовкой. Даже на больших файлах работает быстро. По крайней мере обошлось без повторного чтения файла с сервера/диска.
На форме реквизит МасштабДокументаPDF с предустановленным списком, реквизит МасштабСтрокой для сохранения предыдущего значения и команда ИзменитьМасштаб.
На форме реквизит МасштабДокументаPDF с предустановленным списком, реквизит МасштабСтрокой для сохранения предыдущего значения и команда ИзменитьМасштаб.
&НаКлиенте
Процедура ИзменитьМасштаб(Команда)
Если МасштабДокументаPDF = 0 Тогда
МасштабДокументаPDF = 150;
КонецЕсли;
СтрокаПоиска = "var scale = " + МасштабСтрокой;
МасштабСтрокой = Формат(МасштабДокументаPDF / 100, "ЧРД=.");
СтрокаЗамены = "var scale = " + МасштабСтрокой;
HTMLДокумент = СтрЗаменить(HTMLДокумент, СтрокаПоиска, СтрокаЗамены);
КонецПроцедуры Показать
(48) В процессе тестов на многостраничных файлах выяснилось, что подгрузка страниц работает только в тонком и толстых клиентах, а в веб-клиенте при открытии, например, через Google Chrome, библиотека пытается рендерить весь файл целиком и только потом его показывает. Этот момент может свести пользователей с ума. Происходит это по той причине, что не надо подгружать сразу библиотеку pdf.worker.js. Она подгрузится автоматически, нужно лишь указать путь к ней. Исправленный код во вложении.
Прикрепленные файлы:
Код открытия PDF в WebKit.txt
(50) Огромное спасибо, сильно помогли ваши труды! В вебе и правда отображаться стало. Но я столкнулся с последующей проблемой, я гружу ПДФ файл в элемент справочника, вашим кодом показываю его в ХТМЛ-поле и все здорово. НО(!) когда с веба открываю уже записанный элемент с моей ПДФ-кой, валится ошибка "Несоответствие типов (параметр номер '1')". При работе на платформе таких проблем не возникает, элемент открывается, ПДФ снова отображается, имею возможность сохранить/открыть на устройстве. Не сталкивались с подобным? Может кто подскажет куда копать, что почитать на сей счет?
(48)
в 2022 можно так ))) 1С:Предприятие 8.3 (8.3.15.1700)
&НаСервере
в 2022 можно так ))) 1С:Предприятие 8.3 (8.3.15.1700)
&НаСервере
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
СтрокаPDFФайлаBase64 = ПолучитьBase64СтрокуИзДвоичныхДанных(ПолучитьОбщийМакет("PDF"));
Реквизит1 = "<ht ml><head>
|<body style='zoom: 1;'>
|<ifr ame id='framefile' frameborder='0' scrolling='auto' height='700px' width='100%'></iframe>
|<sc ript>
|document.addEventListener('DOMContentLoaded', () => {
| var blob = new Blob([Uint8Array.from(atob(`"+СтрокаPDFФайлаBase64+"`), c => c.charCodeAt(0))], {type: 'application/pdf'})
| var url = URL.createObjectURL(blob)
| var divfreime = document.getElementById('framefile')
| divfreime.src = url
| })
|</sc ript></body></html>";
КонецПроцедуры Показать
Задался задачей в 2022 году отобразить pdf, платформа 1С:Предприятие 8.3 (8.3.15.1700) встроенный браузер webkit.
Я не являюсь опытным разработчиком 1С. моя стихия это веб и c#. в свое время подобное реализовал на этих языках и просто прикрутил свои старые наработки.
Вот Вам вариант без всяких костылей. по мимо этого реализовал через NetObjectToIDispatch45 оптимизатор PDF способный на лету при загрузки без временных файлов, формировать из чего угодно PDF. на вход объект на выход Base64, но это уже я так понимаю не входит в рамки данного обсуждения.
Удачи друзья.
Я не являюсь опытным разработчиком 1С. моя стихия это веб и c#. в свое время подобное реализовал на этих языках и просто прикрутил свои старые наработки.
Вот Вам вариант без всяких костылей. по мимо этого реализовал через NetObjectToIDispatch45 оптимизатор PDF способный на лету при загрузки без временных файлов, формировать из чего угодно PDF. на вход объект на выход Base64, но это уже я так понимаю не входит в рамки данного обсуждения.
Удачи друзья.
&НаСервере
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
СтрокаPDFФайлаBase64 = ПолучитьBase64СтрокуИзДвоичныхДанных(ПолучитьОбщийМакет("PDF"));
Реквизит1 = "<ht ml><head>
|<body style='zoom: 1;'>
|<ifr ame id='framefile' frameborder='0' scrolling='auto' height='700px' width='100%'></iframe>
|<sc ript>
|document.addEventListener('DOMContentLoaded', () => {
| var blob = new Blob([Uint8Array.from(atob(`"+СтрокаPDFФайлаBase64+"`), c => c.charCodeAt(0))], {type: 'application/pdf'})
| var url = URL.createObjectURL(blob)
| var divfreime = document.getElementById('framefile')
| divfreime.src = url
| })
|</sc ript></body></html>";
КонецПроцедуры Показать
(70) Работает. 8.3.18.1520
На 8.3.18 работают версии pdf.js 2.2.2 и 2.4.456. Версии свежее - не работают (и ошибку webkit не выдает). При этом в Chrome все работает; видимо проблема в необновляемом webkit встроенном в 1С.
Во вложении обработка, в которой можно выбирать разные версии pdf.js
Для реальной работы этот js лучше всего скачать и залить в текстовый макет. В заливке есть нюанс: ctrl+с ctrl+v не работают если копируешь сжатый вариант pdf.js т.к. в нем непечатаемые символы. Нужен исходник. Исходники 2.4.199 во вложении
На 8.3.18 работают версии pdf.js 2.2.2 и 2.4.456. Версии свежее - не работают (и ошибку webkit не выдает). При этом в Chrome все работает; видимо проблема в необновляемом webkit встроенном в 1С.
Во вложении обработка, в которой можно выбирать разные версии pdf.js
Для реальной работы этот js лучше всего скачать и залить в текстовый макет. В заливке есть нюанс: ctrl+с ctrl+v не работают если копируешь сжатый вариант pdf.js т.к. в нем непечатаемые символы. Нужен исходник. Исходники 2.4.199 во вложении
Прикрепленные файлы:
MainJS.txt
Тест открытия pdf-мой.epf
Добрый день. Можете пожалуйста подсказать, почему даже если я использую scale=1.0 при сохранении документа в файл его внешний вид размывается ? Я же по идее никак его не меняю. Если загрузил с оригинальным размером то и выгружаться он должен так же.
Коллеги, добрый день.
Скажите пожалуйста, кто нибудь делал позиционирование открываемого pdf на заранее заданном фрагменте текста?
Кейс 1. Имеем многостраничный pdf, нужно в нем найти подстроку и открыть файл на просмотр на нужной странице. В идеале - выделить найденную подстроку.
Кейс 2. Имеем многостраничный pdf, и набор строк. Пользователь выделяет первую строку - ищем ее в pdf, показываем пользователю страницу с найденным фрагментом. Пользователь выделяет вторую строку - ищем ее в pdf, показываем пользователю страницу с найденным фрагментом. И так далее.
По идее это можно сделать через pdf.js, но не понятно как передать параметр и вызвать метод поиска. Может у кого-то есть примеры?
Скажите пожалуйста, кто нибудь делал позиционирование открываемого pdf на заранее заданном фрагменте текста?
Кейс 1. Имеем многостраничный pdf, нужно в нем найти подстроку и открыть файл на просмотр на нужной странице. В идеале - выделить найденную подстроку.
Кейс 2. Имеем многостраничный pdf, и набор строк. Пользователь выделяет первую строку - ищем ее в pdf, показываем пользователю страницу с найденным фрагментом. Пользователь выделяет вторую строку - ищем ее в pdf, показываем пользователю страницу с найденным фрагментом. И так далее.
По идее это можно сделать через pdf.js, но не понятно как передать параметр и вызвать метод поиска. Может у кого-то есть примеры?
Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот