
//////////////////////////////////////////////////////////////////////
//СтрокаХэш - исходный текст
//hash- начальное значение hash
// М - множитель (влияет накачество хэш и производительность)
// TABLE_SIZE - размер получаемого ключа, как Максимальная величина + 1
Функция Хэш(СтрокаХэш, hash=0, M = 31, TABLE_SIZE = 18446744073709551616)
//TABLE_SIZE = 18446744073709551615; 64 бита
//M = 31; Умножитель
ДлинаСтроки = СтрДлина(СтрокаХэш);
Для к=1 по ДлинаСтроки цикл
hash = M * hash + КодСимвола(Сред(СтрокаХэш,к,1));
конеццикла;
возврат hash%TABLE_SIZE;
КонецФункции
// Для ускорения работы с большими текстами их надо передавать блоками
// Данная функция разбивает исходный текст (Параметр "Строка") на блоки
// длиной ДлинаБлока и вычислет хэш блоками возвращая результат для всего текста.
Функция ХэшБлоками(Строка, ДлинаБлока = 64, hash = 0, M = 31, TABLE_SIZE = 18446744073709551616)
НачПозиция = 1;
ДлинаСтроки = СтрДлина(Строка);
Пока НачПозиция<=ДлинаСтроки цикл
hash = Хэш(Сред(Строка, НачПозиция, ДлинаБлока), hash, M, TABLE_SIZE);
НачПозиция = НачПозиция + ДлинаБлока;
КонецЦикла;
возврат hash;
КонецФункции
Простая и быстрая хэш функция (hash) средствами 1С
Разработка - Универсальные функции
В частности для индексирования строк неограниченной длины или групп строк.
Готовую нашел здесь (реализация MD5), но уж очень медленно работает и оптимизировать её не получится - в 1С нет быстрой работы с битами.
Вот нашел выход. Спасибо сайту за теорию http://www.strchr.com/hash_functions
Оказывается своя хэш функция - это просто.
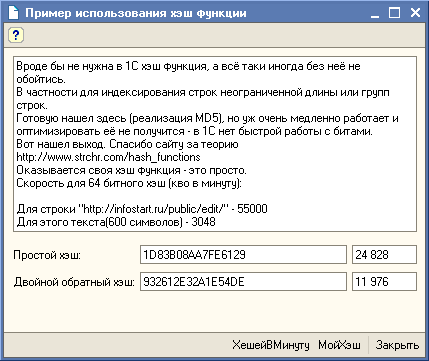
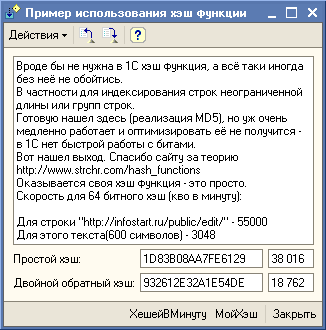
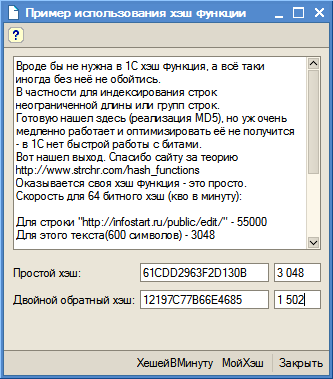
Скорость для 64 битного хэш (кво в минуту):
Для строки "http://infostart.ru/public/edit/" - 55000
Для этого текста(600 символов) - 3048
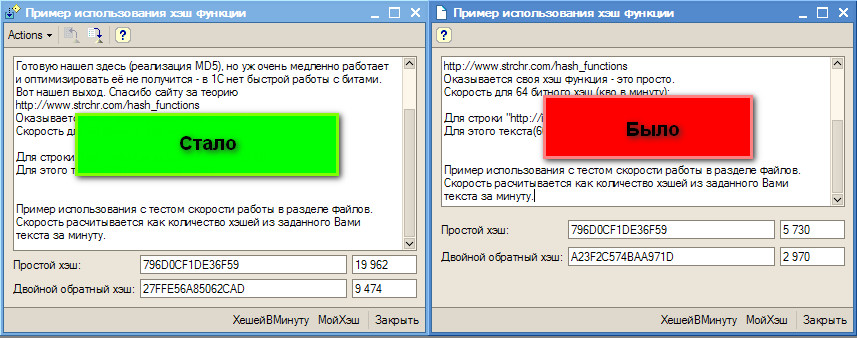
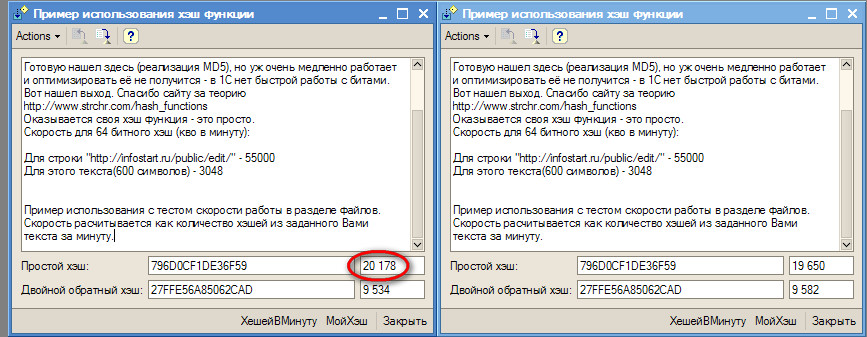
Пример использования с тестом скорости работы в разделе файлов.
Скорость расчитывается как количество хэшей из заданного Вами текста за минуту.
http://www.strchr.com/hash_functions
См. также
Вставляем картинку из буфера обмена (платформа 1С 8.3.24)
1 стартмани
18.03.2024 2917 2 John_d 11
Печать непроведенных документов для УТ, КА, ERP. Настройка печати по пользователям, документам и печатным формам
2 стартмани
22.08.2023 2278 26 progmaster 8
Расширение: Быстрые отборы через буфер [Alt+C] Копировать список, [Alt+V] Вставить список, [Ctrl+C] Копировать из файлов
1 стартмани
13.10.2022 16400 143 sapervodichka 112
{kind=link}