Всем привет.
Такой вопрос: можно ли как-то ускорить выполнение запроса, когда таблица соединяется сама с собой?
Пример: есть регистр в котором допустим хранится информация о проходах через турникеты. Т.е. структура такая: измерения Турникет и ДатаСобытия, ресурсы Вход и Выход.
Задача в запросе получить по каждому турникету дату события и дату предыдущего события.
Для решения можно соединить таблицу саму с собой, что-то вроде такого:
но при количестве записей в десятки или сотни тысяч такой запрос будет работать очень медленно. собственно, вот и вопрос как ускорить выборку таких данных
Такой вопрос: можно ли как-то ускорить выполнение запроса, когда таблица соединяется сама с собой?
Пример: есть регистр в котором допустим хранится информация о проходах через турникеты. Т.е. структура такая: измерения Турникет и ДатаСобытия, ресурсы Вход и Выход.
Задача в запросе получить по каждому турникету дату события и дату предыдущего события.
Для решения можно соединить таблицу саму с собой, что-то вроде такого:
ВЫБРАТЬ
| tmp.Турникет КАК Турникет,
| tmp.ДатаСобытия КАК ДатаСобытия,
| МАКСИМУМ(tmp1.DateCreated) КАК ДатаПредыдущегоСобытия
|ИЗ
| РегистрСведений.tmp КАК tmp
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.tmp КАК tmp1
| ПО tmp.Турникет = tmp1.Турникет
| И tmpTraffic.ДатаСоздания > tmp1.ДатаСоздания
|
|СГРУППИРОВАТЬ ПО
| tmp.Турникет,
| tmp.ДатаСоздания
|
|УПОРЯДОЧИТЬ ПО
| Турникет,
| ДатаСоздания УБЫВ Показатьно при количестве записей в десятки или сотни тысяч такой запрос будет работать очень медленно. собственно, вот и вопрос как ускорить выборку таких данных
По теме из базы знаний
- Видеокурс: Разработка и оптимизация запросов 1С
- Оптимизация запросов 1С - от теории к практике
- Оптимизация запросов 1С:Предприятие – от теории к практике
- Оптимизация запроса к виртуальной таблице регистра накопления
- Планы запросов - это просто! Разбор оптимизаций запросов PostgreSQL на живых примерах
Ответы
Подписаться на ответы
Инфостарт бот
Сортировка:
Древо развёрнутое
Свернуть все
(1)
Раз уж вы используете регистр сведений, так пользуйтесь срезом последних. А предпоследний можно найти как раз из движений по max(дата) при условии дата <> датапоследняя.
Что касается таблицы на саму себя, то оно всегда будет работать с ограничениями по быстродействию даже при хорошей индексации. Срез последних заранее вас избавляет от необходимости джойнить записи все ко всем, храня по сути все ваши турникеты в единичном экземпляре.
можно ли как-то ускорить выполнение запроса, когда таблица соединяется сама с собой?
Раз уж вы используете регистр сведений, так пользуйтесь срезом последних. А предпоследний можно найти как раз из движений по max(дата) при условии дата <> датапоследняя.
Что касается таблицы на саму себя, то оно всегда будет работать с ограничениями по быстродействию даже при хорошей индексации. Срез последних заранее вас избавляет от необходимости джойнить записи все ко всем, храня по сути все ваши турникеты в единичном экземпляре.
(24)
см.выше от идеи использования регистра решил отказаться по причине того, что помещение в регистр нужного количества записей(в зависимости от настроек отчета) занимает продолжительное время...хранить дубль таблицы в регистре ради пары отчетов смысл тоже нет.
в общем случае речь может идти о нескольких милионнах (от 3 до 10)
за месяц уже больше миллиона записей будет.
можете свою идею чуть подробнее описать на таком примере: нам нужно из всей таблицы внешнего источника(структура выше) отобрать записи за выбранный месяц по всем турникетам, каждая запись должна содержать текущую и предыдущую дату события. в итоговую выборку должны попасть записи с интервалом > n сек.
(26)
да, в этом плане все нормально.
с практической точки зрения использовать временные таблицы скорее всего не получится, т.к. предварительная запись данных в регистр это долго и ресурсоемко, выгрузка в ТЗ таких объемов тоже в ресурсы скорее всего упрется
в принципе, как я писал выше...с простым перебором работает вполне приемлемо по скорости...но как говорится нет предела совершенству.
вариант в (20) очень интересный и по скорости очень хорошие результаты дает, но ограничение на временные таблицы сводит на нет возможность его практического применения в данном случае.
Раз уж вы используете регистр сведений, так пользуйтесь срезом последних
см.выше от идеи использования регистра решил отказаться по причине того, что помещение в регистр нужного количества записей(в зависимости от настроек отчета) занимает продолжительное время...хранить дубль таблицы в регистре ради пары отчетов смысл тоже нет.
А вообще сотни тысяч записей
в общем случае речь может идти о нескольких милионнах (от 3 до 10)
первое ограничение брать месяц
за месяц уже больше миллиона записей будет.
можете свою идею чуть подробнее описать на таком примере: нам нужно из всей таблицы внешнего источника(структура выше) отобрать записи за выбранный месяц по всем турникетам, каждая запись должна содержать текущую и предыдущую дату события. в итоговую выборку должны попасть записи с интервалом > n сек.
(26)
И в источнике индексы есть?
да, в этом плане все нормально.
Выбираем максимальную дату в первой временной таблице
с практической точки зрения использовать временные таблицы скорее всего не получится, т.к. предварительная запись данных в регистр это долго и ресурсоемко, выгрузка в ТЗ таких объемов тоже в ресурсы скорее всего упрется
в принципе, как я писал выше...с простым перебором работает вполне приемлемо по скорости...но как говорится нет предела совершенству.
вариант в (20) очень интересный и по скорости очень хорошие результаты дает, но ограничение на временные таблицы сводит на нет возможность его практического применения в данном случае.
(1)
А вообще сотни тысяч записей не вызывают проблем с подобными запросами даже на допотопном железе, если речь об sql версии базы. У меня были десятки миллионов и я делал примерно следующее. Ограничивал дату и находил связи только для попавших в ограничения записей. Далее брал оставшиеся даты, но ограничивал базовые записи уже только теми, для которых значения даты еще не найдены. Естественно, это все одном запросе. Профит был ощутимый, все летало. Главное оптимально подобрать тот интервал, который мы считаем "свежим".
То есть допустим 100500 турникетов имеем, за 10 лет. Первым делом мы находим для них максимальную дату, т.е. дату последнего прохода. Вторым делом джойним к записям за последний год и получаем около 80% результата. На этом мы можем и остановиться, если нет задачи получать данные по древним нерабочим турникетам. Но если уж надо, то джойним к оставшимся 20% записям, для которых предыдущаядата = нулл, оставшиеся 9 лет записей. Если все примерно так, как в моем примере, то наши затраты примерно равны (N/10) * (N) + (9N/10) * (N/5), что равно вроде 28% от того, если бы мы работали в лоб. На практике же можно количество этапов увеличить, первое ограничение брать месяц (турникеты же, место посещаемое) и увеличить профит в разы. Осталось только индексировать таблицу по дате.
Выполняется это в виде пачки вложенных запросов, так что проблем быть не должно. Прям в конструкторе можно сочинять, если так удобнее.
А вообще сотни тысяч записей не вызывают проблем с подобными запросами даже на допотопном железе, если речь об sql версии базы. У меня были десятки миллионов и я делал примерно следующее. Ограничивал дату и находил связи только для попавших в ограничения записей. Далее брал оставшиеся даты, но ограничивал базовые записи уже только теми, для которых значения даты еще не найдены. Естественно, это все одном запросе. Профит был ощутимый, все летало. Главное оптимально подобрать тот интервал, который мы считаем "свежим".
То есть допустим 100500 турникетов имеем, за 10 лет. Первым делом мы находим для них максимальную дату, т.е. дату последнего прохода. Вторым делом джойним к записям за последний год и получаем около 80% результата. На этом мы можем и остановиться, если нет задачи получать данные по древним нерабочим турникетам. Но если уж надо, то джойним к оставшимся 20% записям, для которых предыдущаядата = нулл, оставшиеся 9 лет записей. Если все примерно так, как в моем примере, то наши затраты примерно равны (N/10) * (N) + (9N/10) * (N/5), что равно вроде 28% от того, если бы мы работали в лоб. На практике же можно количество этапов увеличить, первое ограничение брать месяц (турникеты же, место посещаемое) и увеличить профит в разы. Осталось только индексировать таблицу по дате.
Выполняется это в виде пачки вложенных запросов, так что проблем быть не должно. Прям в конструкторе можно сочинять, если так удобнее.
(6)
сейчас фактически так и сделано...простой обход всей выборки с проверкой условий и использованием ТЗ для дальнейшей работы.
вопрос-то в том и заключается, можно ли как-то в запросе получить текущее и предыдущее событие...может быть вообще запрос другой должен быть...соединение таблицы с собой же это просто первое, что приходит в голову.
потом простым обоходом
сейчас фактически так и сделано...простой обход всей выборки с проверкой условий и использованием ТЗ для дальнейшей работы.
вопрос-то в том и заключается, можно ли как-то в запросе получить текущее и предыдущее событие...может быть вообще запрос другой должен быть...соединение таблицы с собой же это просто первое, что приходит в голову.
0) Записи из регистра - во временную таблицу! В разы ускорит выполнение!
1) Естественно, индексация временных таблиц.
2) Отбор данных при помещении в ВТ.
3) Как я понимаю, количество турникетов несопоставимо мало в сравнении с числом событий? Тогда каким-то способом разделить данные по разным турникетам в разные ВТ. Тогда и индексов будет меньше, и поиск данных будет только в рамках одной ВТ (по одному турникету) за раз.
1) Естественно, индексация временных таблиц.
2) Отбор данных при помещении в ВТ.
3) Как я понимаю, количество турникетов несопоставимо мало в сравнении с числом событий? Тогда каким-то способом разделить данные по разным турникетам в разные ВТ. Тогда и индексов будет меньше, и поиск данных будет только в рамках одной ВТ (по одному турникету) за раз.
(10) Внешний источник, по определению - нечто внешнее и потому - нестабильное. Всегда лучше выдёргивать данные оттуда в какую-то временную сущность, анализировать корректность и уже затем - обрабатывать.
ТаблицаЗначений - действительно, потребует памяти.
РегистрСведений - позволит отделить получение данных от обработки, позволит получать данные поблочно, реализовать докачку при обрыве связи, и т. п.
А уж правильно сделанный запрос зависит лишь от Вас!
(11) Реклама хороша, прогиб засчитан. Но тут задача другая совсем. Либо это - кросс-постинг.
ТаблицаЗначений - действительно, потребует памяти.
РегистрСведений - позволит отделить получение данных от обработки, позволит получать данные поблочно, реализовать докачку при обрыве связи, и т. п.
А уж правильно сделанный запрос зависит лишь от Вас!
(11) Реклама хороша, прогиб засчитан. Но тут задача другая совсем. Либо это - кросс-постинг.
Вот в этой статье рассматривается именно эта задача и именно с точки зрения оптимизации запроса.
Задавайте вопросы, если что будет непонятно - мне очень интересны такого рода задачи и есть еще несколько еще неопубликованных приемов для их решения.
Задавайте вопросы, если что будет непонятно - мне очень интересны такого рода задачи и есть еще несколько еще неопубликованных приемов для их решения.
(14) У вас именно та таблица, которая в формулировке вопроса приведена?
- Я могу запрос для консоли сгенерировать или обработку прислать, чтобы вы сами попробовали.
Уточните для этого версию платформы, обычные формы или УФ, состав полей таблицы tmp.
Жалко будет, если просто из-за недопонимания решение из (16) не будет применено. Оно действительно быстрое!
- Я могу запрос для консоли сгенерировать или обработку прислать, чтобы вы сами попробовали.
Уточните для этого версию платформы, обычные формы или УФ, состав полей таблицы tmp.
Жалко будет, если просто из-за недопонимания решение из (16) не будет применено. Оно действительно быстрое!
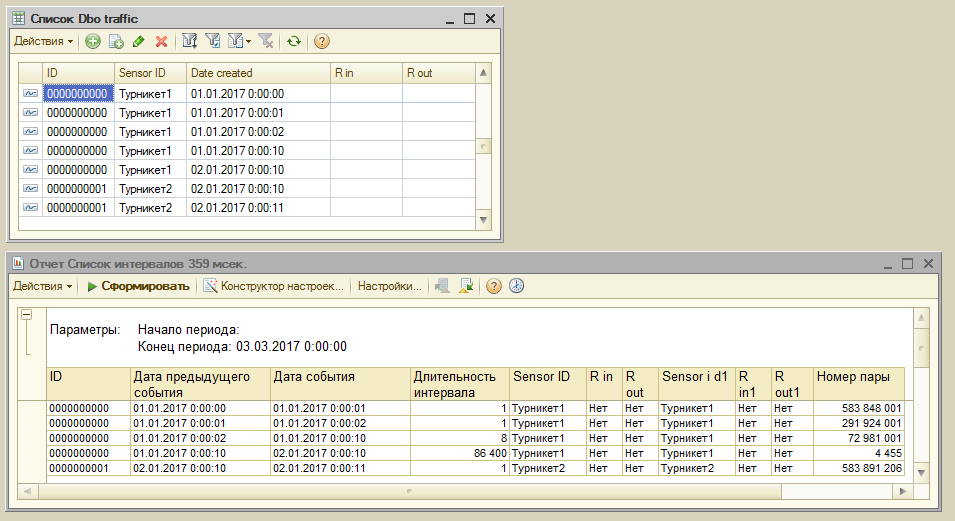
(19) Вот отчет для вашего случая. В пустой конфигурации был создан регистр сведений dbo_Traffic с соответствующими полями и на СКД сделан отчет. Можете испытать его у себя.
В предположении, что ID - идентификатор карты сотрудника отчет показывает связь предыдущего и следующего события одному и тому же ID.
Интересны замеры времени (в форме отчета правая кнопка с картинкой часы) на реально больших объемах данных. Правда, отчет писался под обычные формы, но на 8.3, где есть функция времени в миллисекундах.
В предположении, что ID - идентификатор карты сотрудника отчет показывает связь предыдущего и следующего события одному и тому же ID.
Интересны замеры времени (в форме отчета правая кнопка с картинкой часы) на реально больших объемах данных. Правда, отчет писался под обычные формы, но на 8.3, где есть функция времени в миллисекундах.
Прикрепленные файлы:
(20)
совсем в боевых не получится испытать, т.к. внешний источник накладывает ограничение на использование временных таблиц
но для эксперимента позагружал в регистр разное количество записей из источника
провел несколько замеров:
240 000 записей - 69 000 мсек
960 000 записей - 289 000 мсек
нет, ID - порядковый номер записи.
группировать события нужно по SensorID
переделал у себя регистр с учетом этого для эксперимента.
P.S.
для практического использования в нашем случае все равно медленно получается, во-первых, предварительно в регистр данные нужно будет скинуть, а во-вторых за месяц может быть несколько миллионов записей и получается, что простой перебор выборки с наложением условий и помещением в ТЗ даст самый быстрый результат.
Можете испытать его у себя
совсем в боевых не получится испытать, т.к. внешний источник накладывает ограничение на использование временных таблиц
но для эксперимента позагружал в регистр разное количество записей из источника
провел несколько замеров:
240 000 записей - 69 000 мсек
960 000 записей - 289 000 мсек
В предположении, что ID - идентификатор карты сотрудника
нет, ID - порядковый номер записи.
группировать события нужно по SensorID
переделал у себя регистр с учетом этого для эксперимента.
P.S.
для практического использования в нашем случае все равно медленно получается, во-первых, предварительно в регистр данные нужно будет скинуть, а во-вторых за месяц может быть несколько миллионов записей и получается, что простой перебор выборки с наложением условий и помещением в ТЗ даст самый быстрый результат.
(21) А время указано "чистое" или с учетом записи в регистр? А записи по одной добавлялись или сразу всем набором?
Хотя зависимость линейная, но все же время для миллиона записей кажется слишком большим.
Получается, что в данной постановке (внешний источник данных) смысл использования хитрого алгоритма запроса теряется. Поскольку для передачи данных в обычный запрос с временными таблицами все равно придется использовать таблицу значений. В этом преобразовании легко заодно и решить проблему быстрого расчета разности времени смежных записей.
Вывод такой, что поставленная проблема оптимизации запроса к внешнему источнику данных остается не решенной.
Хотя зависимость линейная, но все же время для миллиона записей кажется слишком большим.
Получается, что в данной постановке (внешний источник данных) смысл использования хитрого алгоритма запроса теряется. Поскольку для передачи данных в обычный запрос с временными таблицами все равно придется использовать таблицу значений. В этом преобразовании легко заодно и решить проблему быстрого расчета разности времени смежных записей.
Вывод такой, что поставленная проблема оптимизации запроса к внешнему источнику данных остается не решенной.
(22)
записи набором, без проверки уникальности....но все равно долго, особенно если несколько милионнов
время указано чисто на отчет, но мне тоже показалось большим...
вообщем, поковырялся еще, что называется из спортивного интереса
1) проблема в скорости была похоже из-за того, что тип измерения был ссылкой на таблицу внешнего источника (заменил на число)
результаты заметно улучшились:
1 400 000 записей - 272 000 мсек
(много времени уходит именно на вывод)
с указанием отбора по длительности интервала 1 400 000 - 58 000 мсек
3 500 000 записей - при выводе результата память клиента дошла до 4 Gb и приложение отвалилось
с указанием отбора по длительности интервала: 3 500 000 - 117 000 мсек
в любом случае вариант со скидыванием большого числа записей в регистр не подходит в плане ресурсов и времени (время записи 3 500 000 записей больше 5 минут, память клиента с 200 Мб доходит до 3.5 Гб)
Как вариант можно поэксперементировать еще просто в выгрузкой ТЗ и подсовыванием ее в запрос (3 500 000 записей выгружаются в ТЗ примерно 45 сек., и память до 1 Гб занимают).
Я так понял текст запроса в отчете еще как-то обрабатывается. Можете прислать вариант для консоли запросов с выборкой из ТЗ со структурой аналогичной регистру?
Для сравнения...простой перебор по выборке из 3 500 000 с наложением условий и пост обработкой занимает примерно 200 сек.
А записи по одной добавлялись или сразу всем набором?
записи набором, без проверки уникальности....но все равно долго, особенно если несколько милионнов
время указано "чистое" или с учетом записи в регистр?
время указано чисто на отчет, но мне тоже показалось большим...
вообщем, поковырялся еще, что называется из спортивного интереса
1) проблема в скорости была похоже из-за того, что тип измерения был ссылкой на таблицу внешнего источника (заменил на число)
результаты заметно улучшились:
1 400 000 записей - 272 000 мсек
(много времени уходит именно на вывод)
с указанием отбора по длительности интервала 1 400 000 - 58 000 мсек
3 500 000 записей - при выводе результата память клиента дошла до 4 Gb и приложение отвалилось
с указанием отбора по длительности интервала: 3 500 000 - 117 000 мсек
в любом случае вариант со скидыванием большого числа записей в регистр не подходит в плане ресурсов и времени (время записи 3 500 000 записей больше 5 минут, память клиента с 200 Мб доходит до 3.5 Гб)
Как вариант можно поэксперементировать еще просто в выгрузкой ТЗ и подсовыванием ее в запрос (3 500 000 записей выгружаются в ТЗ примерно 45 сек., и память до 1 Гб занимают).
Я так понял текст запроса в отчете еще как-то обрабатывается. Можете прислать вариант для консоли запросов с выборкой из ТЗ со структурой аналогичной регистру?
Для сравнения...простой перебор по выборке из 3 500 000 с наложением условий и пост обработкой занимает примерно 200 сек.
(22) попробовал вариант с предварительной выгрузкой данных в ТЗ и дальнейшим использованием вашего запроса.
3 600 000 записей - весь отчет строится около 3.5 минут, из них примерно 50 сек. выгрузка данных в ТЗ
по времени сопоставимо с перебором (на тех же данных время отчета с простым перебором чуть меньше 4 минут), но плюс варианта с перебором это менее требовательный вариант к ресурсам. (ТЗ такого объема более 1 Гб ОЗУ съедает при выгрузке).
но вообще, скорость вашего варианта реально впечатляет.
3 600 000 записей - весь отчет строится около 3.5 минут, из них примерно 50 сек. выгрузка данных в ТЗ
по времени сопоставимо с перебором (на тех же данных время отчета с простым перебором чуть меньше 4 минут), но плюс варианта с перебором это менее требовательный вариант к ресурсам. (ТЗ такого объема более 1 Гб ОЗУ съедает при выгрузке).
но вообще, скорость вашего варианта реально впечатляет.
(33) а можно пару вопросов?
1) зачем сырые данные тащить в 1С, если можно сразу в sql это все посчитать, пользуя оконные функции и всю остальную мощь?
2) а что вы далее делаете с итоговой таблицей? мне просто непонятно, ну получили вы кучу чуть менее сырых данных, не распечатываете же вы просто сотни страниц.
1) зачем сырые данные тащить в 1С, если можно сразу в sql это все посчитать, пользуя оконные функции и всю остальную мощь?
2) а что вы далее делаете с итоговой таблицей? мне просто непонятно, ну получили вы кучу чуть менее сырых данных, не распечатываете же вы просто сотни страниц.
(34)
через ADODB имеете ввиду к SQL подключиться?
(34)
часть таблицы отсекается по длительности (достаточно большая часть, кстати), затем данные группируются определенным образом.
в итоговом отчете получается не так уж много строк, которые надо распечатывать.
сразу в sql это все посчитать
через ADODB имеете ввиду к SQL подключиться?
(34)
мне просто непонятно, ну получили вы кучу чуть менее сырых данных
часть таблицы отсекается по длительности (достаточно большая часть, кстати), затем данные группируются определенным образом.
в итоговом отчете получается не так уж много строк, которые надо распечатывать.
(33) Пока нет времени самому попробовать.
Но вот информация, про которую говорилось в (32):
Это вот отсюда: . То есть появилось в версии 8.3.7.
Кстати, предложение из (25) как альтернативу "олимпийскому" методу тоже можно использовать. Его проблема - это необходимость выбора размера "окна", но она решаемая. Но все же думаю, что олимпийский метод будет побыстрее.
Еще есть вот такой вариант: из статьи (Задача 5). В определенных случаях, как видно из результатов, приведенных в статье и соответствующего плана запроса, он очень эффективен.
Но вот информация, про которую говорилось в (32):
В запросе к внешнему источнику данных возможно использование временных таблиц. При этом производится попытка создания временной таблицы непосредственно в базе данных, связанной с внешним источником данных. Если СУБД не поддерживает создание внешних источников данных – будет вызвано исключение. Имя временной таблице, при обращении к ней, формируется следующим образом:
ВнешнийИсточникДанных.<Имя внешнего источника данных>.ВременнаяТаблица.<Имя временной таблицы>
Пример:
ВЫБРАТЬ Name, ProductID
ПОМЕСТИТЬ ВнешнийИсточникДанных.AdventureWorks.ВременнаяТаблица.Остатки
ИЗ &ТаблицаЗначений
ВЫБРАТЬ Name, ProductID
ПОМЕСТИТЬ ВнешнийИсточникДанных.AdventureWorks.ВременнаяТаблица.Остатки
ИЗ ВнешнийИсточникДанных.AdventureWorks.Таблица.Production_Balance
ВнешнийИсточникДанных.<Имя внешнего источника данных>.ВременнаяТаблица.<Имя временной таблицы>
Пример:
ВЫБРАТЬ Name, ProductID
ПОМЕСТИТЬ ВнешнийИсточникДанных.AdventureWorks.ВременнаяТаблица.Остатки
ИЗ &ТаблицаЗначений
ВЫБРАТЬ Name, ProductID
ПОМЕСТИТЬ ВнешнийИсточникДанных.AdventureWorks.ВременнаяТаблица.Остатки
ИЗ ВнешнийИсточникДанных.AdventureWorks.Таблица.Production_Balance
Это вот отсюда: . То есть появилось в версии 8.3.7.
Кстати, предложение из (25) как альтернативу "олимпийскому" методу тоже можно использовать. Его проблема - это необходимость выбора размера "окна", но она решаемая. Но все же думаю, что олимпийский метод будет побыстрее.
Еще есть вот такой вариант:
ВЫБРАТЬ РАЗЛИЧНЫЕ
Т1.Ч КАК НачалоИнтервала,
Т2.Ч КАК КонецИнтервала
ПОМЕСТИТЬ Темп
ИЗ
БазоваяТаблица КАК Т1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ БазоваяТаблица КАК Т2
ПО Т1.Ч < Т2.Ч
И (Т2.Ч В
(ВЫБРАТЬ МИНИМУМ(ВНЗ.Ч)
ИЗ БазоваяТаблица КАК ВНЗ
ГДЕ Т1.Ч < ВНЗ.Ч)) Показать
Есть вот такое предложение:
Выбираем максимальную дату в первой временной таблице
Во второй выбираем максимальную дату и максимальная дата не равна первой
И объединяем две таблички
И в источнике индексы есть? Если нет, то не стоит ожидать производительности
Выбираем максимальную дату в первой временной таблице
Во второй выбираем максимальную дату и максимальная дата не равна первой
И объединяем две таблички
И в источнике индексы есть? Если нет, то не стоит ожидать производительности
(28)
в теории может и красиво...на практике например, встанет вопрос, где все дни периода взять, т.к. записи могут быть не за каждый день, а соединять внешние и внутренние источники нельзя.
но за саму идею все равно спасибо...при наличии времени, можно будет и в эту сторону поэксперементировать, хотя неуверен, что такое количество джойнов даст какой-то выигрыш по производительности.
Если заменить месяц на день составляет проблему
в теории может и красиво...на практике например, встанет вопрос, где все дни периода взять, т.к. записи могут быть не за каждый день, а соединять внешние и внутренние источники нельзя.
но за саму идею все равно спасибо...при наличии времени, можно будет и в эту сторону поэксперементировать, хотя неуверен, что такое количество джойнов даст какой-то выигрыш по производительности.
Мы можем брать интервал хоть 45 дней 14 часов 10 минут 22 секунды назад от текущей даты, не суть. В теории красиво, на практике еще красивее. Я уже не раз это применял и добивался увеличения производительности в тысячи раз подбором нужных интервалов.
Ты наверное не понял суть. Вот у тебя на полу грязь и вонища стоит. Ты берешь первый раз тряпку и забираешь больше половины грази со всей площади пола. За второй раз - еще какую-то часть, но уже гораздо поменьше. Это быстрее, чем если бы ты мыл полностью на 100% сначала левый дальний угол, потом правый дальний...
Ты наверное не понял суть. Вот у тебя на полу грязь и вонища стоит. Ты берешь первый раз тряпку и забираешь больше половины грази со всей площади пола. За второй раз - еще какую-то часть, но уже гораздо поменьше. Это быстрее, чем если бы ты мыл полностью на 100% сначала левый дальний угол, потом правый дальний...
Для получения уведомлений об ответах подключите телеграм бот:
Инфостарт бот