

{kind=link}
С чего начать? Во-первых, нужно понимать, что в результате этой операции в наших базах появится третья сущность – некая область данных обмена, которая будет представлять единое целое, расположенное в исходных базах и эта область должна восприниматься именно как нечто единое и неделимое, живущее по своим законам, но при этом остающееся неотъемлемой частью исходных баз. Есть и другое видение – когда получившуюся в результате внедрения обмена систему баз считают как бы одной большой распределенной базой – здесь все зависит от контекста задачи и объема обмениваемых данных. Во-вторых, необходимо выработать правила дальнейшего добавления синхронизируемой информации уже с учетом новых реалий. То ли это будет единое место ввода, то ли будут использоваться префиксы и т.д.
Рассмотрим конкретный пример, который мне довелось решить на практике. А практика, как известно, критерий истины! Немного предыстории. На одном производственном предприятии, территориально находящемся в российской глубинке, изначально учет велся в БП и на начальном этапе развития это всех устраивало. Потом, когда первоначальные цели были достигнуты – производство вышло на некоторый «взрослый» уровень, было решено внедрить в качестве управленческой системы УПП, а БП оставить для сдачи регламентированной отчетности. Всё вести в УПП руководство сочло рискованным, в том числе и по причине отсутствия квалифицированных бухгалтеров в радиусе 100 км вокруг предприятия (все кого удалось найти, уже работали на нем). Изначально внедрять УПП начали силами местной бухгалтерии, которая, недолго думая и поучившись на простеньких курсах в областном центре, начала руками вбивать исходные данные в пустую базу УПП. Через некоторое время (примерно через год по рассказам), так и не дождавшись внятных результатов, руководство предприятия решило все таки передать вопрос внедрения УПП специалисту (вашему покорному слуге – тогда сотруднику управляющей компании), а бухгалтерию разжаловать в разряд вспомогательных сил, то есть, по сути отстранить от непосредственного участия в проекте, на что бухгалтерия естественно обиделась (что впоследствии не раз аукнулось, но не об этом сейчас речь). То есть, УПП нужно было внедрить независимо и обособленно как чисто управленческую программу, и ни о каком обмене данными естественно никто не задумывался. Но, как известно, аппетит приходит во время еды. Достигнув определенных результатов во внедрении УПП (сам процесс внедрения заслуживает отдельного повествования), я получил задачу настроить обмен данными между базами УПП и БП, чтобы исключить дублирование ввода информации. А именно - решено было поступления материалов и отгрузки готовой продукции загружать в УПП из БП (ввод этих весьма ответственных операций на самом деле просто некому было доверить, а бухгалтерия наотрез отказалась касаться УПП, поставив руководство перед выбором – мы или УПП! – бред конечно, но бывает и такое:). Но, как я уже говорил, база изначально создавалась независимо от БП путем ручного ввода и досталась мне в наследство от бухгалтеров (кстати сказать, я об этом и не подозревал сначала – все эти подробности выяснились уже позже, а отступать было некуда, сказано - сделано). На этом предысторию я заканчиваю.
Итак, предстояло сделать следующее:
- Определить круг объектов, подлежащих синхронизации
- Выбрать метод синхронизации
- Определить базу, в которой будет производиться изменение ключевой для синхронизации информации
- В зависимости от выбранного метода синхронизации, изменить ключевые данные синхронизации в выбранной базе
Сами правила обмена были разработаны в кратчайшие сроки без каких-то проблем (их здесь не публикую, так как они нагружены некоторой не универсальной спецификой), так как конфигурации УПП и БП очень близки по структуре (ничего готового тогда не нашел).
Далее по пунктам.
- Объекты. Справочник «Номенклатура», подчиненные ему справочники «Единицы измерения» и т.д., справочник «Контрагенты» с подчиненными ему справочниками «Договоры контрагентов» и пр.
- Выбор метода синхронизации – «По внутреннему идентификатору». В силу разных причин для меня это самый привычный и предпочтительный метод синхронизации.
- В качестве базы, в которой будет произведена корректировка ключевой информации была выбрана УПП (ее размер был тогда меньше, да и ничего другого в силу изложенного выше было не дано и в общем не нужно).
- Вопрос синхронизации данных был решен в несколько этапов:
4.1 Из БП были выгружены данные нужных нам справочников - код, наименование, код владельца и наименование владельца.
4.2 В УПП были найдены все соответствующие элементы, которым были установлены такие же коды и наименования, как в БП – все это было аккуратно проделано вручную без использования каких либо средств автоматизации. Объемы работ были вменяемыми – мне повезло. Если бы понадобилось что-то придумывать, я бы скорей всего использовал нечеткий поиск на базе сравнения строк (//infostart.ru/public/146559/).
4.3 Дальше я применил следующий метод. Основываясь на том, что данные в двух базах вводились независимо, то есть уникальные идентификаторы объектов у всех разные и поэтому, получив таблицу замен уникальных идентификаторов: «UID в БП» – «UID в УПП», их можно заменять в XML - файле выгрузки базы просто как текст, не вникая в подробности (тип данных, структура самого файла XML и пр.), что и было проделано. Кстати сказать, свойство «вселенской» уникальности UIDов не раз меня выручало в различных задачах – выражаясь образно, его всегда можно «бросить» в некую «кучу», а потом легко найти там же простыми средствами (банальный перебор или еще что то - по ситуации).
То есть:
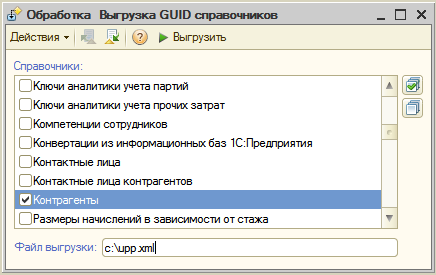
4.3.1 С помощью обработки "ВыгрузкаGUID_Справочников" (есть во вложении) были сформированы 2 файла с данными справочников (код, наименование, код владельца, наименование владельнца и UID) для каждой из баз.
4.3.2 Данные из базы УПП с помощью встроенной обработки обмена между одинаковыми базами были выгружены в файл. Можно было так же использовать универсальную обработку обмена данными между одинаковыми конфигурациями с диска ИТС или механизм создания подчиненного узла РИБ (потом главный узел отключить и удалить узлы).
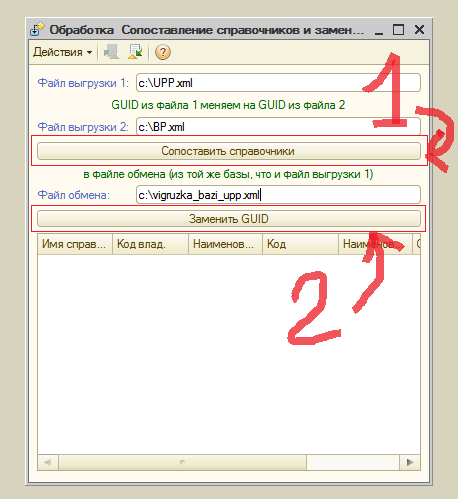
4.3.3 С помощью обработки "СопоставлениеСправочниковИЗаменаGUID" (есть во вложении), в файле выгрузки, путем перебора строк файла выгрузки базы как обычного текстового файла, произведены замены UIDов по данным выгруженных из баз файов с данными справочников (п. 4.3.1).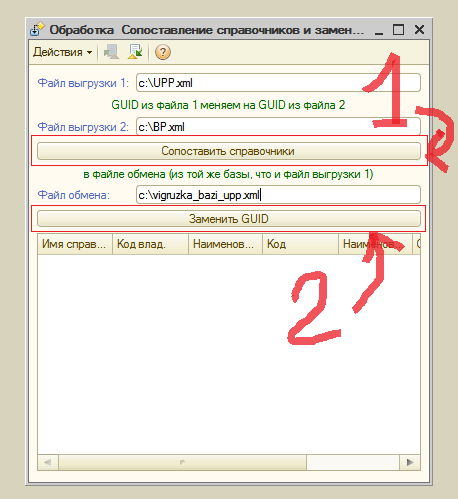
4.3.4 Данные обработанного таким образом файла выгрузки загружены в пустую базу УПП, созданную из конфигурации исходной.
В результате были получены базы, готовые обмениваться необходимыми мне данными.
Дальше в ходе работы конечно же всплывали некоторые единичные косячки, которые точечно устранялись универсальной обработкой замены ссылок.
Во вложении архив с использованными мной обработками (все как есть), которые могут пригодится в подобной ситуации и подойдут для любой конфигурации. Конечно, все это может показаться слишком сложным, но тем и интересно.
Надеюсь, мой опыт кому-нибудь пригодится!
P.S.
Для умников. Зачем я это пишу? Отчасти графомания, отчасти от скуки и все же не исключаю, что кому то это будет интересно :)